 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity over Quality: Training an AV Motion Planner with Large Scale Commodity Vision Data
Mar 03, 2022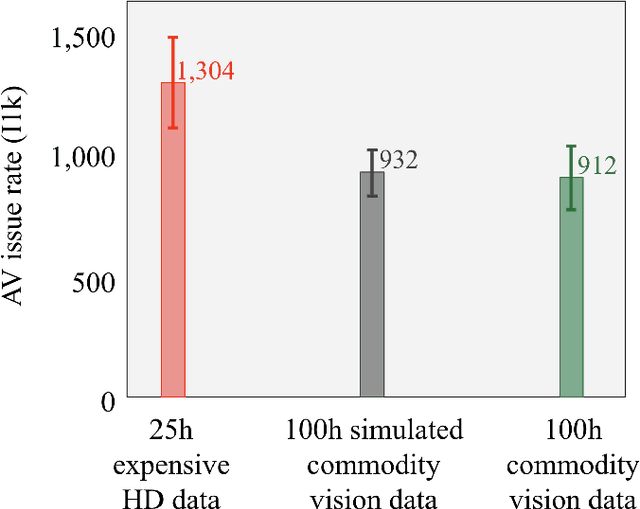
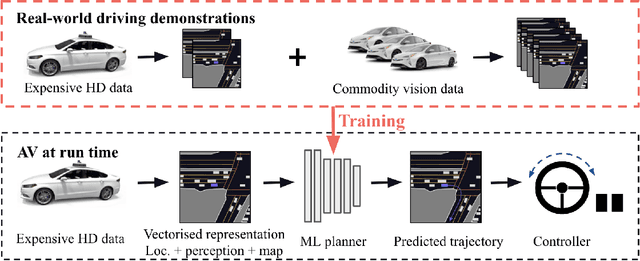
With the Autonomous Vehicle (AV) industry shifting towards Autonomy 2.0, the performance of self-driving systems starts to rely heavily on large quantities of expert driving demonstrations. However, collecting this demonstration data typically involves expensive HD sensor suites (LiDAR + RADAR + cameras), which quickly becomes financially infeasible at the scales required. This motivates the use of commodity vision sensors for data collection, which are an order of magnitude cheaper than the HD sensor suites, but offer lower fidelity. If it were possible to leverage these for training an AV motion planner, observing the `long tail' of driving events would become a financially viable strategy. As our main contribution we show it is possible to train a high-performance motion planner using commodity vision data which outperforms planners trained on HD-sensor data for a fraction of the cost. We do this by comparing the autonomy system performance when training on these two different sensor configurations, and showing that we can compensate for the lower sensor fidelity by means of increased quantity: a planner trained on 100h of commodity vision data outperforms one with 25h of expensive HD data. We also share the technical challenges we had to tackle to make this work. To the best of our knowledge, we are the first to demonstrate that this is possible using real-world data.
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021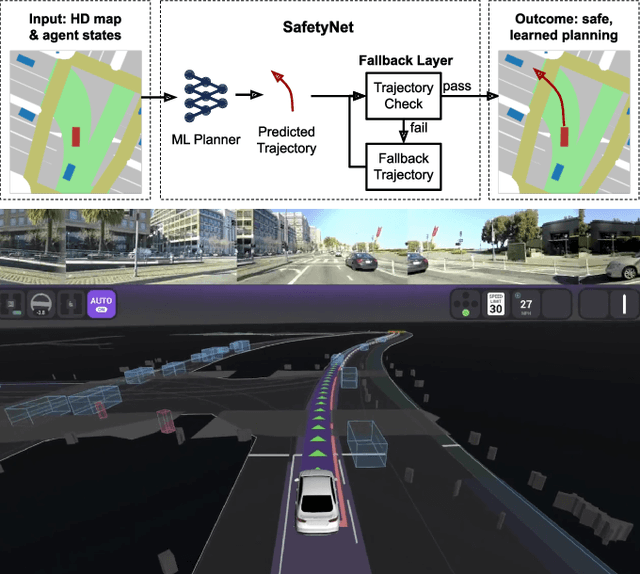
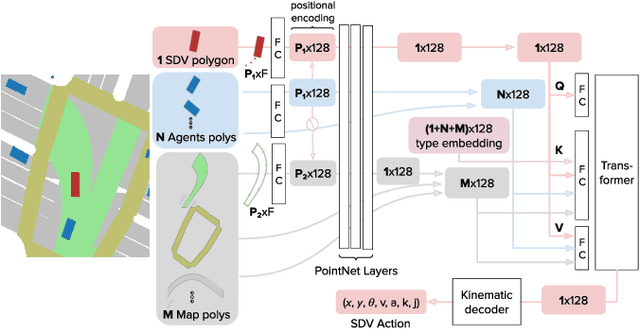
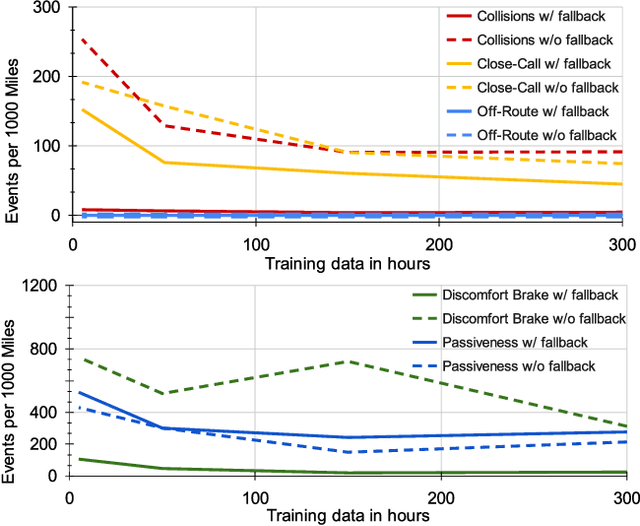
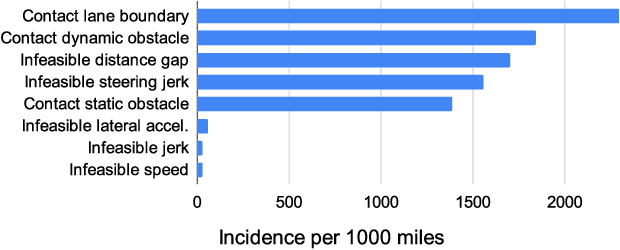
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.
Autonomy 2.0: Why is self-driving always 5 years away?
Aug 09, 2021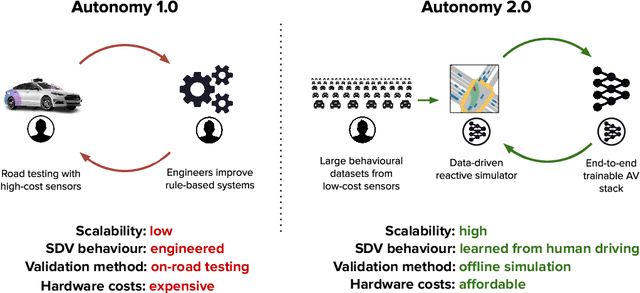

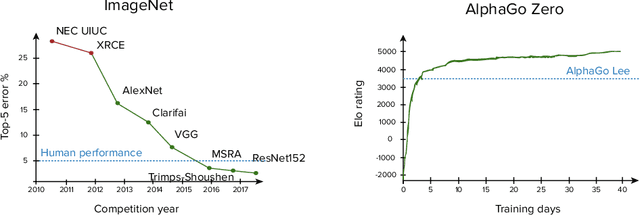
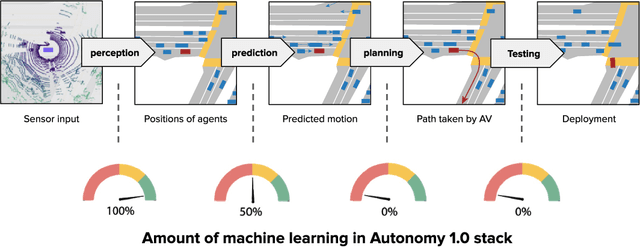
Despite the numerous successes of machine learning over the past decade (image recognition, decision-making, NLP, image synthesis), self-driving technology has not yet followed the same trend. In this paper, we study the history, composition, and development bottlenecks of the modern self-driving stack. We argue that the slow progress is caused by approaches that require too much hand-engineering, an over-reliance on road testing, and high fleet deployment costs. We observe that the classical stack has several bottlenecks that preclude the necessary scale needed to capture the long tail of rare events. To resolve these problems, we outline the principles of Autonomy 2.0, an ML-first approach to self-driving, as a viable alternative to the currently adopted state-of-the-art. This approach is based on (i) a fully differentiable AV stack trainable from human demonstrations, (ii) closed-loop data-driven reactive simulation, and (iii) large-scale, low-cost data collections as critical solutions towards scalability issues. We outline the general architecture, survey promising works in this direction and propose key challenges to be addressed by the community in the future.
What data do we need for training an AV motion planner?
May 26, 2021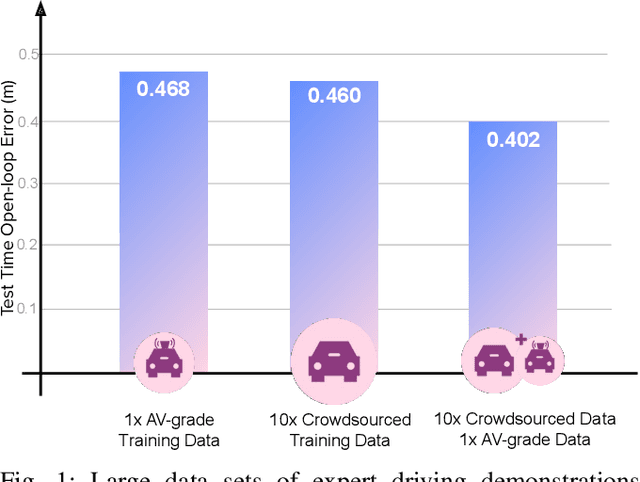
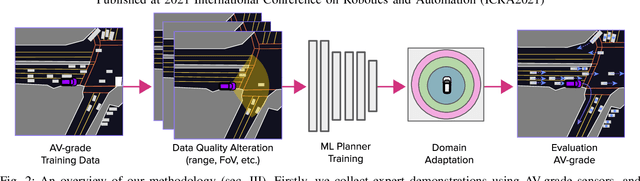
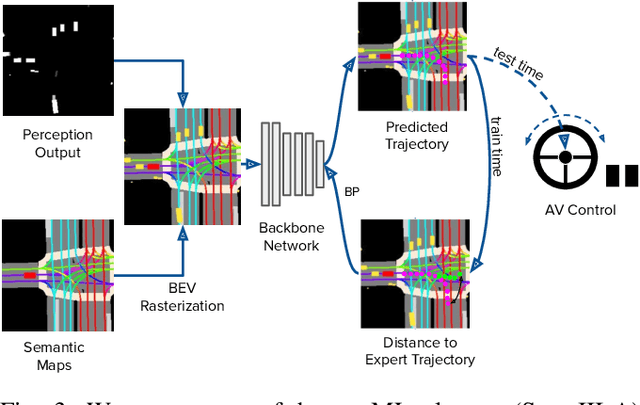
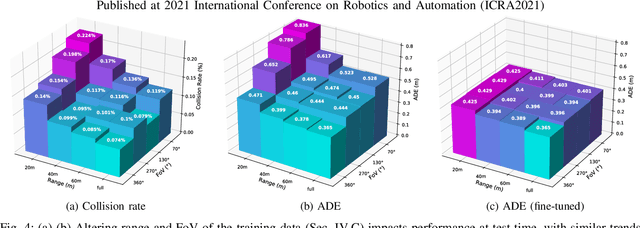
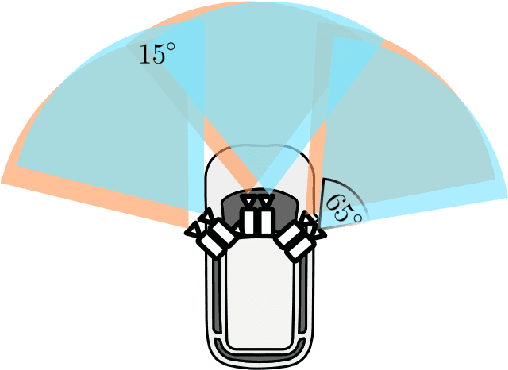
We investigate what grade of sensor data is required for training an imitation-learning-based AV planner on human expert demonstration. Machine-learned planners are very hungry for training data, which is usually collected using vehicles equipped with the same sensors used for autonomous operation. This is costly and non-scalable. If cheaper sensors could be used for collection instead, data availability would go up, which is crucial in a field where data volume requirements are large and availability is small. We present experiments using up to 1000 hours worth of expert demonstration and find that training with 10x lower-quality data outperforms 1x AV-grade data in terms of planner performance. The important implication of this is that cheaper sensors can indeed be used. This serves to improve data access and democratize the field of imitation-based motion planning. Alongside this, we perform a sensitivity analysis of planner performance as a function of perception range, field-of-view, accuracy, and data volume, and the reason why lower-quality data still provide good planning results.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
May 26, 2021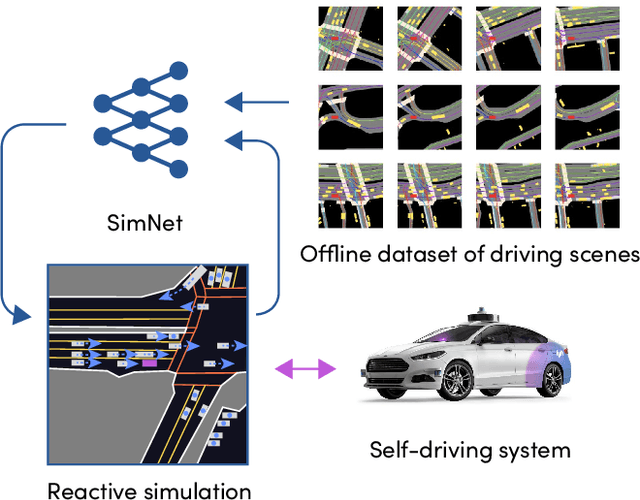
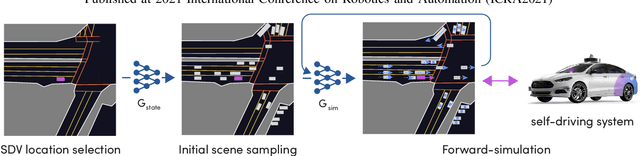
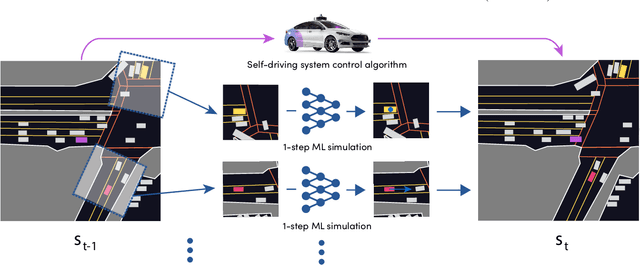
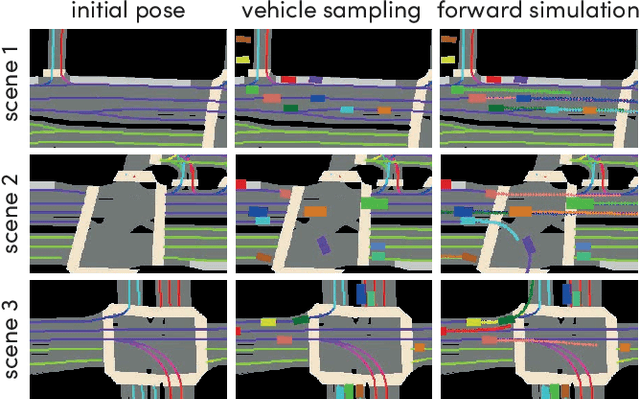
In this work, we present a simple end-to-end trainable machine learning system capable of realistically simulating driving experiences. This can be used for the verification of self-driving system performance without relying on expensive and time-consuming road testing. In particular, we frame the simulation problem as a Markov Process, leveraging deep neural networks to model both state distribution and transition function. These are trainable directly from the existing raw observations without the need for any handcrafting in the form of plant or kinematic models. All that is needed is a dataset of historical traffic episodes. Our formulation allows the system to construct never seen scenes that unfold realistically reacting to the self-driving car's behaviour. We train our system directly from 1,000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation. At the same time, we apply the method to evaluate the performance of a recently proposed state-of-the-art ML planning system trained from human driving logs. We discover this planning system is prone to previously unreported causal confusion issues that are difficult to test by non-reactive simulation. To the best of our knowledge, this is the first work that directly merges highly realistic data-driven simulations with a closed-loop evaluation for self-driving vehicles. We make the data, code, and pre-trained models publicly available to further stimulate simulation development.
Collaborative Augmented Reality on Smartphones via Life-long City-scale Maps
Nov 10, 2020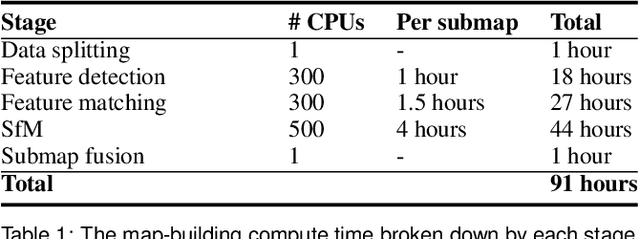
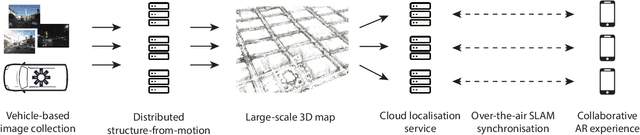
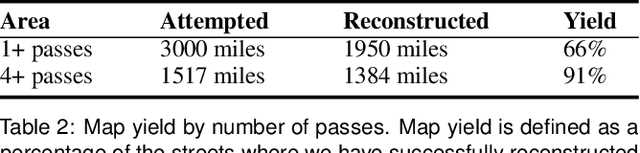
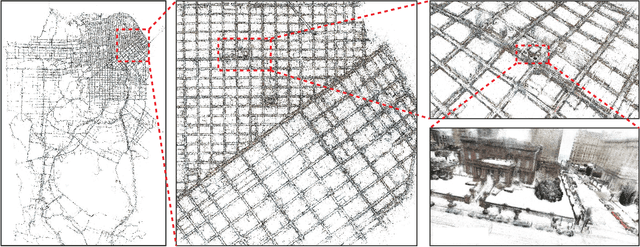
In this paper we present the first published end-to-end production computer-vision system for powering city-scale shared augmented reality experiences on mobile devices. In doing so we propose a new formulation for an experience-based mapping framework as an effective solution to the key issues of city-scale SLAM scalability, robustness, map updates and all-time all-weather performance required by a production system. Furthermore, we propose an effective way of synchronising SLAM systems to deliver seamless real-time localisation of multiple edge devices at the same time. All this in the presence of network latency and bandwidth limitations. The resulting system is deployed and tested at scale in San Francisco where it delivers AR experiences in a mapped area of several hundred kilometers. To foster further development of this area we offer the data set to the public, constituting the largest of this kind to date.
VALUE: Large Scale Voting-based Automatic Labelling for Urban Environments
Jun 05, 2020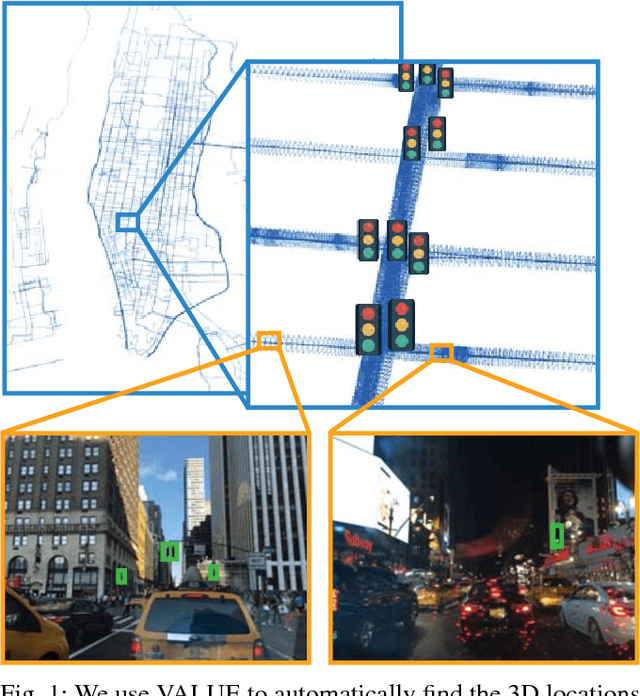
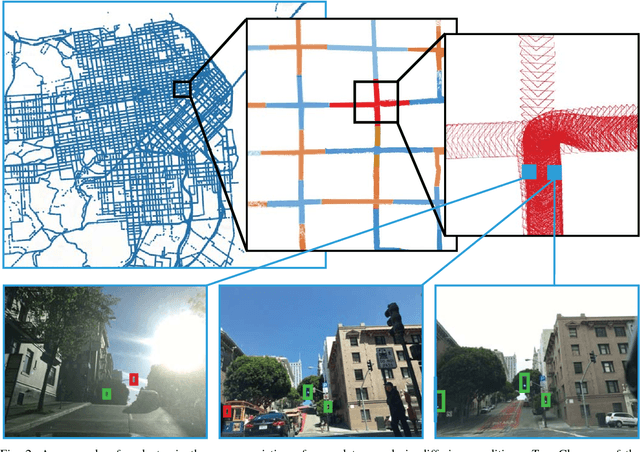
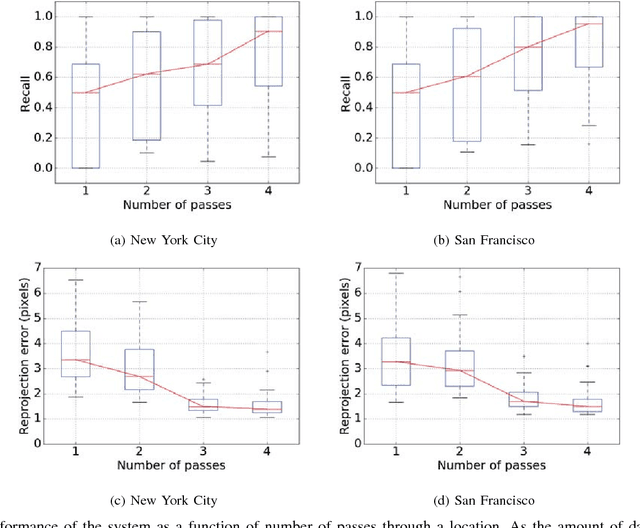

This paper presents a simple and robust method for the automatic localisation of static 3D objects in large-scale urban environments. By exploiting the potential to merge a large volume of noisy but accurately localised 2D image data, we achieve superior performance in terms of both robustness and accuracy of the recovered 3D information. The method is based on a simple distributed voting schema which can be fully distributed and parallelised to scale to large-scale scenarios. To evaluate the method we collected city-scale data sets from New York City and San Francisco consisting of almost 400k images spanning the area of 40 km$^2$ and used it to accurately recover the 3D positions of traffic lights. We demonstrate a robust performance and also show that the solution improves in quality over time as the amount of data increases.