 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Zorro: the masked multimodal transformer
Jan 23, 2023



Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
Collaborative Augmented Reality on Smartphones via Life-long City-scale Maps
Nov 10, 2020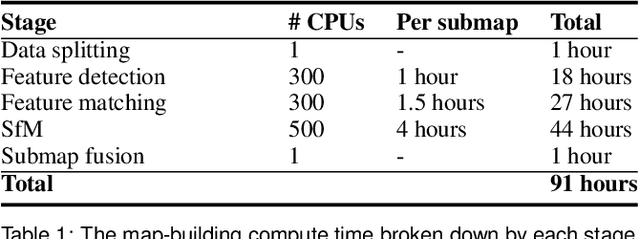
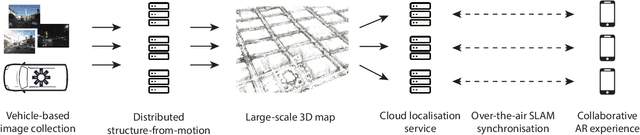
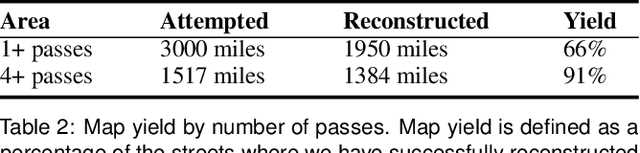
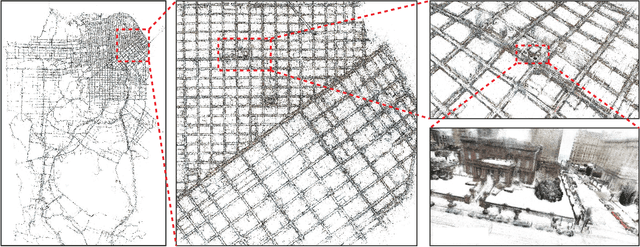
In this paper we present the first published end-to-end production computer-vision system for powering city-scale shared augmented reality experiences on mobile devices. In doing so we propose a new formulation for an experience-based mapping framework as an effective solution to the key issues of city-scale SLAM scalability, robustness, map updates and all-time all-weather performance required by a production system. Furthermore, we propose an effective way of synchronising SLAM systems to deliver seamless real-time localisation of multiple edge devices at the same time. All this in the presence of network latency and bandwidth limitations. The resulting system is deployed and tested at scale in San Francisco where it delivers AR experiences in a mapped area of several hundred kilometers. To foster further development of this area we offer the data set to the public, constituting the largest of this kind to date.