 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned In-Context Learners for Efficient Adaptation
Dec 22, 2025When adapting large language models (LLMs) to a specific downstream task, two primary approaches are commonly employed: (1) prompt engineering, often with in-context few-shot learning, leveraging the model's inherent generalization abilities, and (2) fine-tuning on task-specific data, directly optimizing the model's parameters. While prompt-based methods excel in few-shot scenarios, their effectiveness often plateaus as more data becomes available. Conversely, fine-tuning scales well with data but may underperform when training examples are scarce. We investigate a unified approach that bridges these two paradigms by incorporating in-context learning directly into the fine-tuning process. Specifically, we fine-tune the model on task-specific data augmented with in-context examples, mimicking the structure of k-shot prompts. This approach, while requiring per-task fine-tuning, combines the sample efficiency of in-context learning with the performance gains of fine-tuning, leading to a method that consistently matches and often significantly exceeds both these baselines. To perform hyperparameter selection in the low-data regime, we propose to use prequential evaluation, which eliminates the need for expensive cross-validation and leverages all available data for training while simultaneously providing a robust validation signal. We conduct an extensive empirical study to determine which adaptation paradigm - fine-tuning, in-context learning, or our proposed unified approach offers the best predictive performance on a concrete data downstream-tasks.
Benchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation
Nov 13, 2025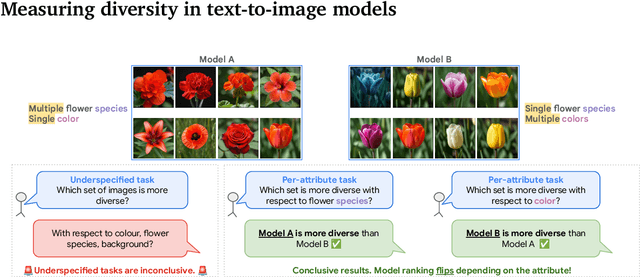


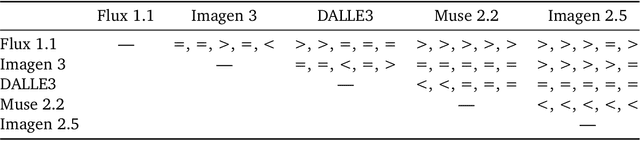
Despite advances in generation quality, current text-to-image (T2I) models often lack diversity, generating homogeneous outputs. This work introduces a framework to address the need for robust diversity evaluation in T2I models. Our framework systematically assesses diversity by evaluating individual concepts and their relevant factors of variation. Key contributions include: (1) a novel human evaluation template for nuanced diversity assessment; (2) a curated prompt set covering diverse concepts with their identified factors of variation (e.g. prompt: An image of an apple, factor of variation: color); and (3) a methodology for comparing models in terms of human annotations via binomial tests. Furthermore, we rigorously compare various image embeddings for diversity measurement. Notably, our principled approach enables ranking of T2I models by diversity, identifying categories where they particularly struggle. This research offers a robust methodology and insights, paving the way for improvements in T2I model diversity and metric development.
Mind the Graph When Balancing Data for Fairness or Robustness
Jun 25, 2024



Failures of fairness or robustness in machine learning predictive settings can be due to undesired dependencies between covariates, outcomes and auxiliary factors of variation. A common strategy to mitigate these failures is data balancing, which attempts to remove those undesired dependencies. In this work, we define conditions on the training distribution for data balancing to lead to fair or robust models. Our results display that, in many cases, the balanced distribution does not correspond to selectively removing the undesired dependencies in a causal graph of the task, leading to multiple failure modes and even interference with other mitigation techniques such as regularization. Overall, our results highlight the importance of taking the causal graph into account before performing data balancing.
Transformers for Supervised Online Continual Learning
Mar 03, 2024



Transformers have become the dominant architecture for sequence modeling tasks such as natural language processing or audio processing, and they are now even considered for tasks that are not naturally sequential such as image classification. Their ability to attend to and to process a set of tokens as context enables them to develop in-context few-shot learning abilities. However, their potential for online continual learning remains relatively unexplored. In online continual learning, a model must adapt to a non-stationary stream of data, minimizing the cumulative nextstep prediction loss. We focus on the supervised online continual learning setting, where we learn a predictor $x_t \rightarrow y_t$ for a sequence of examples $(x_t, y_t)$. Inspired by the in-context learning capabilities of transformers and their connection to meta-learning, we propose a method that leverages these strengths for online continual learning. Our approach explicitly conditions a transformer on recent observations, while at the same time online training it with stochastic gradient descent, following the procedure introduced with Transformer-XL. We incorporate replay to maintain the benefits of multi-epoch training while adhering to the sequential protocol. We hypothesize that this combination enables fast adaptation through in-context learning and sustained longterm improvement via parametric learning. Our method demonstrates significant improvements over previous state-of-the-art results on CLOC, a challenging large-scale real-world benchmark for image geo-localization.
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
Mar 03, 2024



We consider the problem of online fine tuning the parameters of a language model at test time, also known as dynamic evaluation. While it is generally known that this approach improves the overall predictive performance, especially when considering distributional shift between training and evaluation data, we here emphasize the perspective that online adaptation turns parameters into temporally changing states and provides a form of context-length extension with memory in weights, more in line with the concept of memory in neuroscience. We pay particular attention to the speed of adaptation (in terms of sample efficiency),sensitivity to the overall distributional drift, and the computational overhead for performing gradient computations and parameter updates. Our empirical study provides insights on when online adaptation is particularly interesting. We highlight that with online adaptation the conceptual distinction between in-context learning and fine tuning blurs: both are methods to condition the model on previously observed tokens.
Revisiting Evaluation Metrics for Semantic Segmentation: Optimization and Evaluation of Fine-grained Intersection over Union
Oct 30, 2023
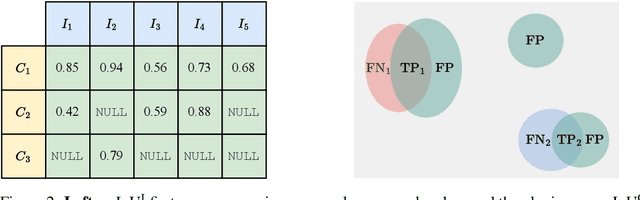


Semantic segmentation datasets often exhibit two types of imbalance: \textit{class imbalance}, where some classes appear more frequently than others and \textit{size imbalance}, where some objects occupy more pixels than others. This causes traditional evaluation metrics to be biased towards \textit{majority classes} (e.g. overall pixel-wise accuracy) and \textit{large objects} (e.g. mean pixel-wise accuracy and per-dataset mean intersection over union). To address these shortcomings, we propose the use of fine-grained mIoUs along with corresponding worst-case metrics, thereby offering a more holistic evaluation of segmentation techniques. These fine-grained metrics offer less bias towards large objects, richer statistical information, and valuable insights into model and dataset auditing. Furthermore, we undertake an extensive benchmark study, where we train and evaluate 15 modern neural networks with the proposed metrics on 12 diverse natural and aerial segmentation datasets. Our benchmark study highlights the necessity of not basing evaluations on a single metric and confirms that fine-grained mIoUs reduce the bias towards large objects. Moreover, we identify the crucial role played by architecture designs and loss functions, which lead to best practices in optimizing fine-grained metrics. The code is available at \href{https://github.com/zifuwanggg/JDTLosses}{https://github.com/zifuwanggg/JDTLosses}.
Towards Robust and Efficient Continual Language Learning
Jul 11, 2023



As the application space of language models continues to evolve, a natural question to ask is how we can quickly adapt models to new tasks. We approach this classic question from a continual learning perspective, in which we aim to continue fine-tuning models trained on past tasks on new tasks, with the goal of "transferring" relevant knowledge. However, this strategy also runs the risk of doing more harm than good, i.e., negative transfer. In this paper, we construct a new benchmark of task sequences that target different possible transfer scenarios one might face, such as a sequence of tasks with high potential of positive transfer, high potential for negative transfer, no expected effect, or a mixture of each. An ideal learner should be able to maximally exploit information from all tasks that have any potential for positive transfer, while also avoiding the negative effects of any distracting tasks that may confuse it. We then propose a simple, yet effective, learner that satisfies many of our desiderata simply by leveraging a selective strategy for initializing new models from past task checkpoints. Still, limitations remain, and we hope this benchmark can help the community to further build and analyze such learners.
Kalman Filter for Online Classification of Non-Stationary Data
Jun 14, 2023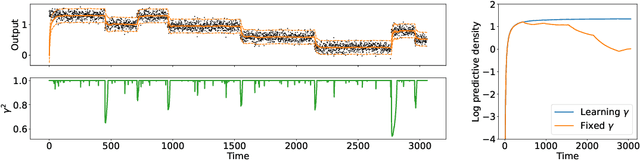
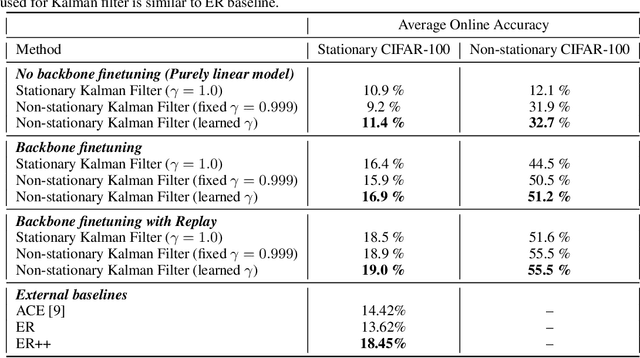
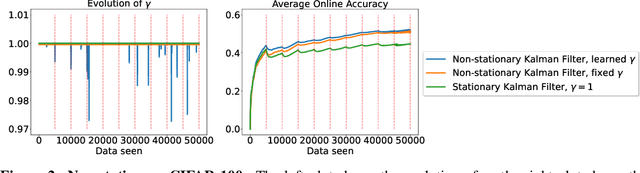
In Online Continual Learning (OCL) a learning system receives a stream of data and sequentially performs prediction and training steps. Important challenges in OCL are concerned with automatic adaptation to the particular non-stationary structure of the data, and with quantification of predictive uncertainty. Motivated by these challenges we introduce a probabilistic Bayesian online learning model by using a (possibly pretrained) neural representation and a state space model over the linear predictor weights. Non-stationarity over the linear predictor weights is modelled using a parameter drift transition density, parametrized by a coefficient that quantifies forgetting. Inference in the model is implemented with efficient Kalman filter recursions which track the posterior distribution over the linear weights, while online SGD updates over the transition dynamics coefficient allows to adapt to the non-stationarity seen in data. While the framework is developed assuming a linear Gaussian model, we also extend it to deal with classification problems and for fine-tuning the deep learning representation. In a set of experiments in multi-class classification using data sets such as CIFAR-100 and CLOC we demonstrate the predictive ability of the model and its flexibility to capture non-stationarity.
Towards Compute-Optimal Transfer Learning
Apr 25, 2023



The field of transfer learning is undergoing a significant shift with the introduction of large pretrained models which have demonstrated strong adaptability to a variety of downstream tasks. However, the high computational and memory requirements to finetune or use these models can be a hindrance to their widespread use. In this study, we present a solution to this issue by proposing a simple yet effective way to trade computational efficiency for asymptotic performance which we define as the performance a learning algorithm achieves as compute tends to infinity. Specifically, we argue that zero-shot structured pruning of pretrained models allows them to increase compute efficiency with minimal reduction in performance. We evaluate our method on the Nevis'22 continual learning benchmark that offers a diverse set of transfer scenarios. Our results show that pruning convolutional filters of pretrained models can lead to more than 20% performance improvement in low computational regimes.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.