 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Average Stability of Multipass Preconditioned SGD and Effective Dimension
Mar 12, 2026We study trade-offs between the population risk curvature, geometry of the noise, and preconditioning on the generalisation ability of the multipass Preconditioned Stochastic Gradient Descent (PSGD). Many practical optimisation heuristics implicitly navigate this trade-off in different ways -- for instance, some aim to whiten gradient noise, while others aim to align updates with expected loss curvature. When the geometry of the population risk curvature and the geometry of the gradient noise do not match, an aggressive choice that improves one aspect can amplify instability along the other, leading to suboptimal statistical behavior. In this paper we employ on-average algorithmic stability to connect generalisation of PSGD to the effective dimension that depends on these sources of curvature. While existing techniques for on-average stability of SGD are limited to a single pass, as first contribution we develop a new on-average stability analysis for multipass SGD that handles the correlations induced by data reuse. This allows us to derive excess risk bounds that depend on the effective dimension. In particular, we show that an improperly chosen preconditioner can yield suboptimal effective dimension dependence in both optimisation and generalisation. Finally, we complement our upper bounds with matching, instance-dependent lower bounds.
Sufficient Conditions for Stability of Minimum-Norm Interpolating Deep ReLU Networks
Feb 14, 2026Algorithmic stability is a classical framework for analyzing the generalization error of learning algorithms. It predicts that an algorithm has small generalization error if it is insensitive to small perturbations in the training set such as the removal or replacement of a training point. While stability has been demonstrated for numerous well-known algorithms, this framework has had limited success in analyses of deep neural networks. In this paper we study the algorithmic stability of deep ReLU homogeneous neural networks that achieve zero training error using parameters with the smallest $L_2$ norm, also known as the minimum-norm interpolation, a phenomenon that can be observed in overparameterized models trained by gradient-based algorithms. We investigate sufficient conditions for such networks to be stable. We find that 1) such networks are stable when they contain a (possibly small) stable sub-network, followed by a layer with a low-rank weight matrix, and 2) such networks are not guaranteed to be stable even when they contain a stable sub-network, if the following layer is not low-rank. The low-rank assumption is inspired by recent empirical and theoretical results which demonstrate that training deep neural networks is biased towards low-rank weight matrices, for minimum-norm interpolation and weight-decay regularization.
Pointwise confidence estimation in the non-linear $\ell^2$-regularized least squares
Jun 08, 2025We consider a high-probability non-asymptotic confidence estimation in the $\ell^2$-regularized non-linear least-squares setting with fixed design. In particular, we study confidence estimation for local minimizers of the regularized training loss. We show a pointwise confidence bound, meaning that it holds for the prediction on any given fixed test input $x$. Importantly, the proposed confidence bound scales with similarity of the test input to the training data in the implicit feature space of the predictor (for instance, becoming very large when the test input lies far outside of the training data). This desirable last feature is captured by the weighted norm involving the inverse-Hessian matrix of the objective function, which is a generalized version of its counterpart in the linear setting, $x^{\top} \text{Cov}^{-1} x$. Our generalized result can be regarded as a non-asymptotic counterpart of the classical confidence interval based on asymptotic normality of the MLE estimator. We propose an efficient method for computing the weighted norm, which only mildly exceeds the cost of a gradient computation of the loss function. Finally, we complement our analysis with empirical evidence showing that the proposed confidence bound provides better coverage/width trade-off compared to a confidence estimation by bootstrapping, which is a gold-standard method in many applications involving non-linear predictors such as neural networks.
Low-rank bias, weight decay, and model merging in neural networks
Feb 24, 2025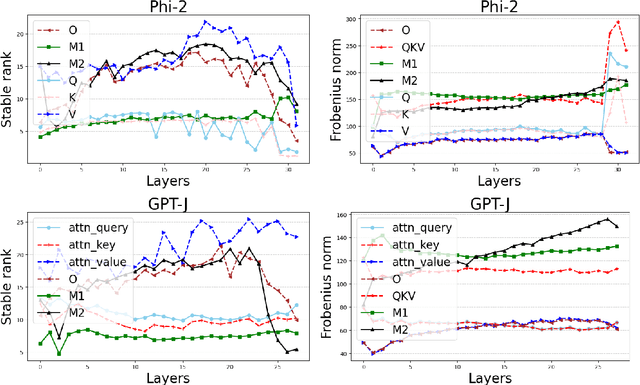
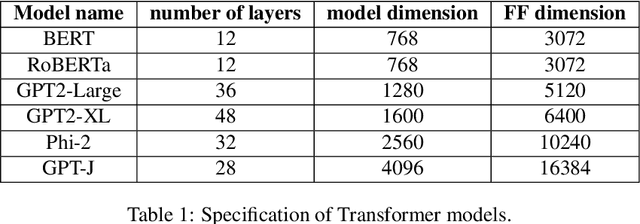
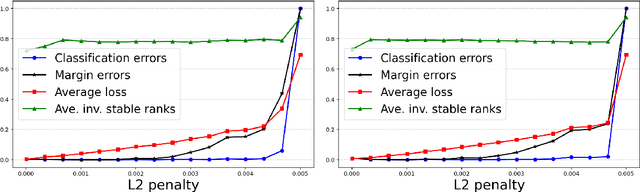
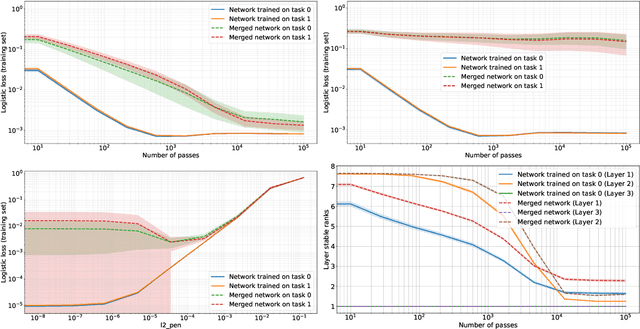
We explore the low-rank structure of the weight matrices in neural networks originating from training with Gradient Descent (GD) and Gradient Flow (GF) with $L2$ regularization (also known as weight decay). We show several properties of GD-trained deep neural networks, induced by $L2$ regularization. In particular, for a stationary point of GD we show alignment of the parameters and the gradient, norm preservation across layers, and low-rank bias: properties previously known in the context of GF solutions. Experiments show that the assumptions made in the analysis only mildly affect the observations. In addition, we investigate a multitask learning phenomenon enabled by $L2$ regularization and low-rank bias. In particular, we show that if two networks are trained, such that the inputs in the training set of one network are approximately orthogonal to the inputs in the training set of the other network, the new network obtained by simply summing the weights of the two networks will perform as well on both training sets as the respective individual networks. We demonstrate this for shallow ReLU neural networks trained by GD, as well as deep linear and deep ReLU networks trained by GF.
Better-than-KL PAC-Bayes Bounds
Feb 14, 2024Let $f(\theta, X_1),$ $ \dots,$ $ f(\theta, X_n)$ be a sequence of random elements, where $f$ is a fixed scalar function, $X_1, \dots, X_n$ are independent random variables (data), and $\theta$ is a random parameter distributed according to some data-dependent posterior distribution $P_n$. In this paper, we consider the problem of proving concentration inequalities to estimate the mean of the sequence. An example of such a problem is the estimation of the generalization error of some predictor trained by a stochastic algorithm, such as a neural network where $f$ is a loss function. Classically, this problem is approached through a PAC-Bayes analysis where, in addition to the posterior, we choose a prior distribution which captures our belief about the inductive bias of the learning problem. Then, the key quantity in PAC-Bayes concentration bounds is a divergence that captures the complexity of the learning problem where the de facto standard choice is the KL divergence. However, the tightness of this choice has rarely been questioned. In this paper, we challenge the tightness of the KL-divergence-based bounds by showing that it is possible to achieve a strictly tighter bound. In particular, we demonstrate new high-probability PAC-Bayes bounds with a novel and better-than-KL divergence that is inspired by Zhang et al. (2022). Our proof is inspired by recent advances in regret analysis of gambling algorithms, and its use to derive concentration inequalities. Our result is first-of-its-kind in that existing PAC-Bayes bounds with non-KL divergences are not known to be strictly better than KL. Thus, we believe our work marks the first step towards identifying optimal rates of PAC-Bayes bounds.
Mixture Weight Estimation and Model Prediction in Multi-source Multi-target Domain Adaptation
Sep 19, 2023

We consider the problem of learning a model from multiple heterogeneous sources with the goal of performing well on a new target distribution. The goal of learner is to mix these data sources in a target-distribution aware way and simultaneously minimize the empirical risk on the mixed source. The literature has made some tangible advancements in establishing theory of learning on mixture domain. However, there are still two unsolved problems. Firstly, how to estimate the optimal mixture of sources, given a target domain; Secondly, when there are numerous target domains, how to solve empirical risk minimization (ERM) for each target using possibly unique mixture of data sources in a computationally efficient manner. In this paper we address both problems efficiently and with guarantees. We cast the first problem, mixture weight estimation, as a convex-nonconcave compositional minimax problem, and propose an efficient stochastic algorithm with provable stationarity guarantees. Next, for the second problem, we identify that for certain regimes, solving ERM for each target domain individually can be avoided, and instead parameters for a target optimal model can be viewed as a non-linear function on a space of the mixture coefficients. Building upon this, we show that in the offline setting, a GD-trained overparameterized neural network can provably learn such function to predict the model of target domain instead of solving a designated ERM problem. Finally, we also consider an online setting and propose a label efficient online algorithm, which predicts parameters for new targets given an arbitrary sequence of mixing coefficients, while enjoying regret guarantees.
Tighter PAC-Bayes Bounds Through Coin-Betting
Feb 12, 2023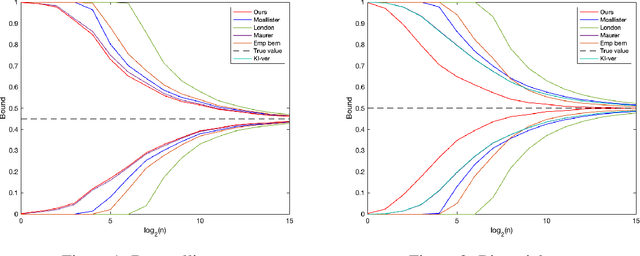

We consider the problem of estimating the mean of a sequence of random elements $f(X_1, \theta)$ $, \ldots, $ $f(X_n, \theta)$ where $f$ is a fixed scalar function, $S=(X_1, \ldots, X_n)$ are independent random variables, and $\theta$ is a possibly $S$-dependent parameter. An example of such a problem would be to estimate the generalization error of a neural network trained on $n$ examples where $f$ is a loss function. Classically, this problem is approached through concentration inequalities holding uniformly over compact parameter sets of functions $f$, for example as in Rademacher or VC type analysis. However, in many problems, such inequalities often yield numerically vacuous estimates. Recently, the \emph{PAC-Bayes} framework has been proposed as a better alternative for this class of problems for its ability to often give numerically non-vacuous bounds. In this paper, we show that we can do even better: we show how to refine the proof strategy of the PAC-Bayes bounds and achieve \emph{even tighter} guarantees. Our approach is based on the \emph{coin-betting} framework that derives the numerically tightest known time-uniform concentration inequalities from the regret guarantees of online gambling algorithms. In particular, we derive the first PAC-Bayes concentration inequality based on the coin-betting approach that holds simultaneously for all sample sizes. We demonstrate its tightness showing that by \emph{relaxing} it we obtain a number of previous results in a closed form including Bernoulli-KL and empirical Bernstein inequalities. Finally, we propose an efficient algorithm to numerically calculate confidence sequences from our bound, which often generates nonvacuous confidence bounds even with one sample, unlike the state-of-the-art PAC-Bayes bounds.
Learning Lipschitz Functions by GD-trained Shallow Overparameterized ReLU Neural Networks
Dec 28, 2022We explore the ability of overparameterized shallow ReLU neural networks to learn Lipschitz, non-differentiable, bounded functions with additive noise when trained by Gradient Descent (GD). To avoid the problem that in the presence of noise, neural networks trained to nearly zero training error are inconsistent in this class, we focus on the early-stopped GD which allows us to show consistency and optimal rates. In particular, we explore this problem from the viewpoint of the Neural Tangent Kernel (NTK) approximation of a GD-trained finite-width neural network. We show that whenever some early stopping rule is guaranteed to give an optimal rate (of excess risk) on the Hilbert space of the kernel induced by the ReLU activation function, the same rule can be used to achieve minimax optimal rate for learning on the class of considered Lipschitz functions by neural networks. We discuss several data-free and data-dependent practically appealing stopping rules that yield optimal rates.
Stability & Generalisation of Gradient Descent for Shallow Neural Networks without the Neural Tangent Kernel
Jul 27, 2021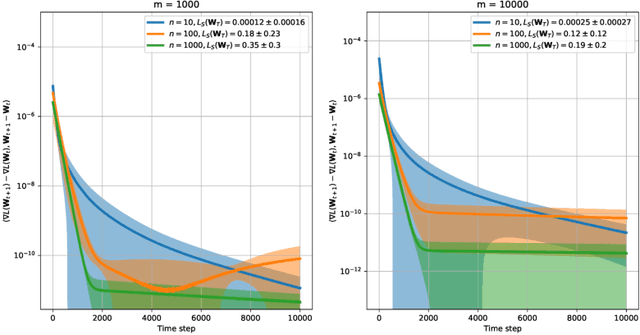
We revisit on-average algorithmic stability of Gradient Descent (GD) for training overparameterised shallow neural networks and prove new generalisation and excess risk bounds without the Neural Tangent Kernel (NTK) or Polyak-{\L}ojasiewicz (PL) assumptions. In particular, we show oracle type bounds which reveal that the generalisation and excess risk of GD is controlled by an interpolating network with the shortest GD path from initialisation (in a sense, an interpolating network with the smallest relative norm). While this was known for kernelised interpolants, our proof applies directly to networks trained by GD without intermediate kernelisation. At the same time, by relaxing oracle inequalities developed here we recover existing NTK-based risk bounds in a straightforward way, which demonstrates that our analysis is tighter. Finally, unlike most of the NTK-based analyses we focus on regression with label noise and show that GD with early stopping is consistent.
On the Role of Optimization in Double Descent: A Least Squares Study
Jul 27, 2021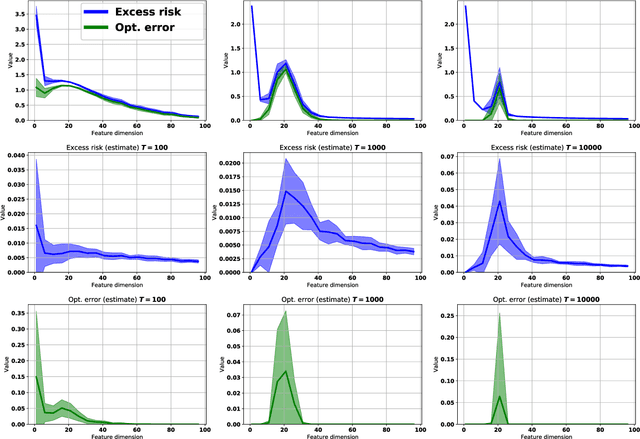
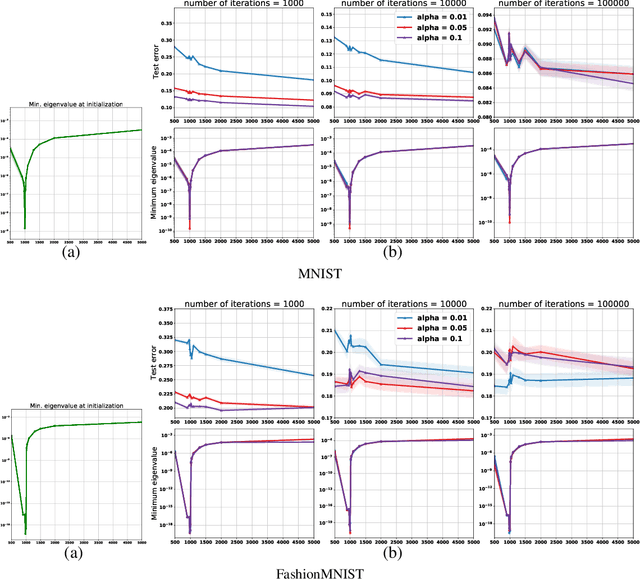
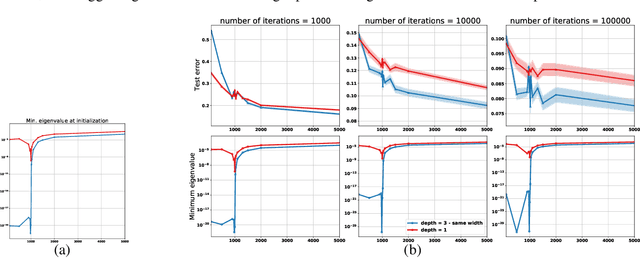
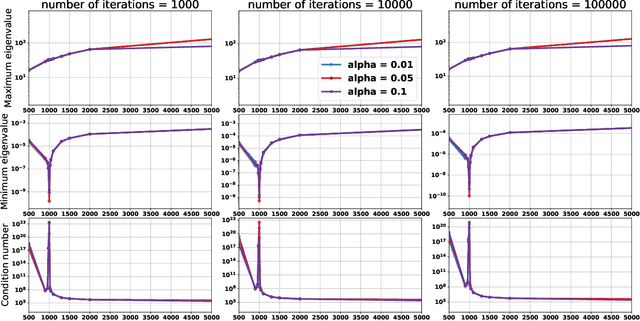
Empirically it has been observed that the performance of deep neural networks steadily improves as we increase model size, contradicting the classical view on overfitting and generalization. Recently, the double descent phenomena has been proposed to reconcile this observation with theory, suggesting that the test error has a second descent when the model becomes sufficiently overparameterized, as the model size itself acts as an implicit regularizer. In this paper we add to the growing body of work in this space, providing a careful study of learning dynamics as a function of model size for the least squares scenario. We show an excess risk bound for the gradient descent solution of the least squares objective. The bound depends on the smallest non-zero eigenvalue of the covariance matrix of the input features, via a functional form that has the double descent behavior. This gives a new perspective on the double descent curves reported in the literature. Our analysis of the excess risk allows to decouple the effect of optimization and generalization error. In particular, we find that in case of noiseless regression, double descent is explained solely by optimization-related quantities, which was missed in studies focusing on the Moore-Penrose pseudoinverse solution. We believe that our derivation provides an alternative view compared to existing work, shedding some light on a possible cause of this phenomena, at least in the considered least squares setting. We empirically explore if our predictions hold for neural networks, in particular whether the covariance of intermediary hidden activations has a similar behavior as the one predicted by our derivations.