 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeyman-Pearson Classification under Both Null and Alternative Distributions Shift
Nov 10, 2025We consider the problem of transfer learning in Neyman-Pearson classification, where the objective is to minimize the error w.r.t. a distribution $μ_1$, subject to the constraint that the error w.r.t. a distribution $μ_0$ remains below a prescribed threshold. While transfer learning has been extensively studied in traditional classification, transfer learning in imbalanced classification such as Neyman-Pearson classification has received much less attention. This setting poses unique challenges, as both types of errors must be simultaneously controlled. Existing works address only the case of distribution shift in $μ_1$, whereas in many practical scenarios shifts may occur in both $μ_0$ and $μ_1$. We derive an adaptive procedure that not only guarantees improved Type-I and Type-II errors when the source is informative, but also automatically adapt to situations where the source is uninformative, thereby avoiding negative transfer. In addition to such statistical guarantees, the procedures is efficient, as shown via complementary computational guarantees.
On the Convergence and Stability of Distributed Sub-model Training
Nov 08, 2025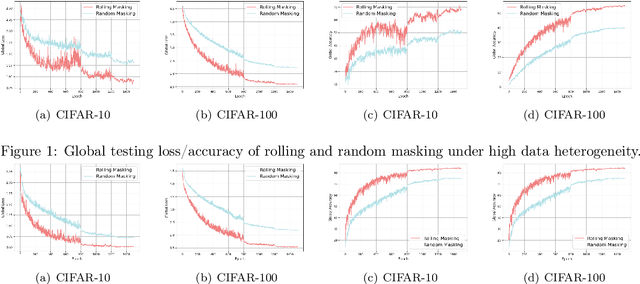
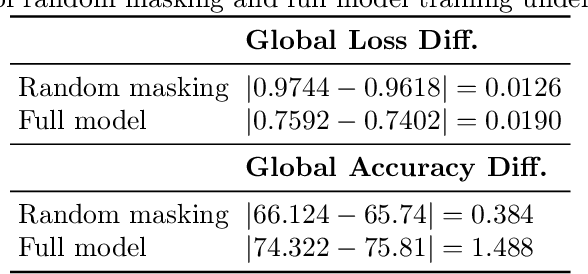
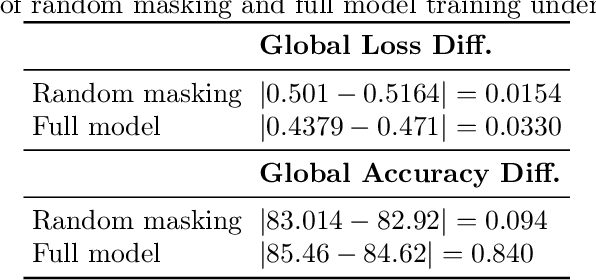

As learning models continue to grow in size, enabling on-device local training of these models has emerged as a critical challenge in federated learning. A popular solution is sub-model training, where the server only distributes randomly sampled sub-models to the edge clients, and clients only update these small models. However, those random sampling of sub-models may not give satisfying convergence performance. In this paper, observing the success of SGD with shuffling, we propose a distributed shuffled sub-model training, where the full model is partitioned into several sub-models in advance, and the server shuffles those sub-models, sends each of them to clients at each round, and by the end of local updating period, clients send back the updated sub-models, and server averages them. We establish the convergence rate of this algorithm. We also study the generalization of distributed sub-model training via stability analysis, and find that the sub-model training can improve the generalization via amplifying the stability of training process. The extensive experiments also validate our theoretical findings.
Stochastic Compositional Minimax Optimization with Provable Convergence Guarantees
Aug 22, 2024Stochastic compositional minimax problems are prevalent in machine learning, yet there are only limited established on the convergence of this class of problems. In this paper, we propose a formal definition of the stochastic compositional minimax problem, which involves optimizing a minimax loss with a compositional structure either in primal , dual, or both primal and dual variables. We introduce a simple yet effective algorithm, stochastically Corrected stOchastic gradient Descent Ascent (CODA), which is a descent ascent type algorithm with compositional correction steps, and establish its convergence rate in aforementioned three settings. In the presence of the compositional structure in primal, the objective function typically becomes nonconvex in primal due to function composition. Thus, we consider the nonconvex-strongly-concave and nonconvex-concave settings and show that CODA can efficiently converge to a stationary point. In the case of composition on the dual, the objective function becomes nonconcave in the dual variable, and we demonstrate convergence in the strongly-convex-nonconcave and convex-nonconcave setting. In the case of composition on both variables, the primal and dual variables may lose convexity and concavity, respectively. Therefore, we anaylze the convergence in weakly-convex-weakly-concave setting. We also give a variance reduction version algorithm, CODA+, which achieves the best known rate on nonconvex-strongly-concave and nonconvex-concave compositional minimax problem. This work initiates the theoretical study of the stochastic compositional minimax problem on various settings and may inform modern machine learning scenarios such as domain adaptation or robust model-agnostic meta-learning.
On the Generalization Ability of Unsupervised Pretraining
Mar 11, 2024


Recent advances in unsupervised learning have shown that unsupervised pre-training, followed by fine-tuning, can improve model generalization. However, a rigorous understanding of how the representation function learned on an unlabeled dataset affects the generalization of the fine-tuned model is lacking. Existing theoretical research does not adequately account for the heterogeneity of the distribution and tasks in pre-training and fine-tuning stage. To bridge this gap, this paper introduces a novel theoretical framework that illuminates the critical factor influencing the transferability of knowledge acquired during unsupervised pre-training to the subsequent fine-tuning phase, ultimately affecting the generalization capabilities of the fine-tuned model on downstream tasks. We apply our theoretical framework to analyze generalization bound of two distinct scenarios: Context Encoder pre-training with deep neural networks and Masked Autoencoder pre-training with deep transformers, followed by fine-tuning on a binary classification task. Finally, inspired by our findings, we propose a novel regularization method during pre-training to further enhances the generalization of fine-tuned model. Overall, our results contribute to a better understanding of unsupervised pre-training and fine-tuning paradigm, and can shed light on the design of more effective pre-training algorithms.
Collaborative Learning with Different Labeling Functions
Feb 20, 2024We study a variant of Collaborative PAC Learning, in which we aim to learn an accurate classifier for each of the $n$ data distributions, while minimizing the number of samples drawn from them in total. Unlike in the usual collaborative learning setup, it is not assumed that there exists a single classifier that is simultaneously accurate for all distributions. We show that, when the data distributions satisfy a weaker realizability assumption, sample-efficient learning is still feasible. We give a learning algorithm based on Empirical Risk Minimization (ERM) on a natural augmentation of the hypothesis class, and the analysis relies on an upper bound on the VC dimension of this augmented class. In terms of the computational efficiency, we show that ERM on the augmented hypothesis class is NP-hard, which gives evidence against the existence of computationally efficient learners in general. On the positive side, for two special cases, we give learners that are both sample- and computationally-efficient.
Early ChatGPT User Portrait through the Lens of Data
Dec 10, 2023Since its launch, ChatGPT has achieved remarkable success as a versatile conversational AI platform, drawing millions of users worldwide and garnering widespread recognition across academic, industrial, and general communities. This paper aims to point a portrait of early GPT users and understand how they evolved. Specific questions include their topics of interest and their potential careers; and how this changes over time. We conduct a detailed analysis of real-world ChatGPT datasets with multi-turn conversations between users and ChatGPT. Through a multi-pronged approach, we quantify conversation dynamics by examining the number of turns, then gauge sentiment to understand user sentiment variations, and finally employ Latent Dirichlet Allocation (LDA) to discern overarching topics within the conversation. By understanding shifts in user demographics and interests, we aim to shed light on the changing nature of human-AI interaction and anticipate future trends in user engagement with language models.
Distributed Personalized Empirical Risk Minimization
Oct 26, 2023
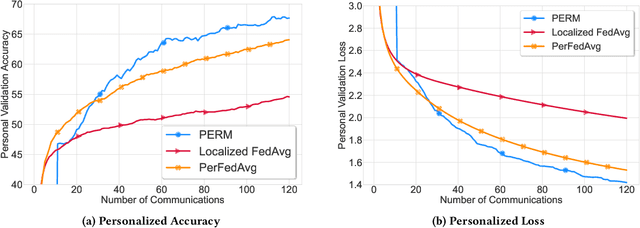

This paper advocates a new paradigm Personalized Empirical Risk Minimization (PERM) to facilitate learning from heterogeneous data sources without imposing stringent constraints on computational resources shared by participating devices. In PERM, we aim to learn a distinct model for each client by learning who to learn with and personalizing the aggregation of local empirical losses by effectively estimating the statistical discrepancy among data distributions, which entails optimal statistical accuracy for all local distributions and overcomes the data heterogeneity issue. To learn personalized models at scale, we propose a distributed algorithm that replaces the standard model averaging with model shuffling to simultaneously optimize PERM objectives for all devices. This also allows us to learn distinct model architectures (e.g., neural networks with different numbers of parameters) for different clients, thus confining underlying memory and compute resources of individual clients. We rigorously analyze the convergence of the proposed algorithm and conduct experiments that corroborate the effectiveness of the proposed paradigm.
Understanding Deep Gradient Leakage via Inversion Influence Functions
Sep 22, 2023Deep Gradient Leakage (DGL) is a highly effective attack that recovers private training images from gradient vectors. This attack casts significant privacy challenges on distributed learning from clients with sensitive data, where clients are required to share gradients. Defending against such attacks requires but lacks an understanding of when and how privacy leakage happens, mostly because of the black-box nature of deep networks. In this paper, we propose a novel Inversion Influence Function (I$^2$F) that establishes a closed-form connection between the recovered images and the private gradients by implicitly solving the DGL problem. Compared to directly solving DGL, I$^2$F is scalable for analyzing deep networks, requiring only oracle access to gradients and Jacobian-vector products. We empirically demonstrate that I$^2$F effectively approximated the DGL generally on different model architectures, datasets, attack implementations, and noise-based defenses. With this novel tool, we provide insights into effective gradient perturbation directions, the unfairness of privacy protection, and privacy-preferred model initialization. Our codes are provided in https://github.com/illidanlab/inversion-influence-function.
Mixture Weight Estimation and Model Prediction in Multi-source Multi-target Domain Adaptation
Sep 19, 2023

We consider the problem of learning a model from multiple heterogeneous sources with the goal of performing well on a new target distribution. The goal of learner is to mix these data sources in a target-distribution aware way and simultaneously minimize the empirical risk on the mixed source. The literature has made some tangible advancements in establishing theory of learning on mixture domain. However, there are still two unsolved problems. Firstly, how to estimate the optimal mixture of sources, given a target domain; Secondly, when there are numerous target domains, how to solve empirical risk minimization (ERM) for each target using possibly unique mixture of data sources in a computationally efficient manner. In this paper we address both problems efficiently and with guarantees. We cast the first problem, mixture weight estimation, as a convex-nonconcave compositional minimax problem, and propose an efficient stochastic algorithm with provable stationarity guarantees. Next, for the second problem, we identify that for certain regimes, solving ERM for each target domain individually can be avoided, and instead parameters for a target optimal model can be viewed as a non-linear function on a space of the mixture coefficients. Building upon this, we show that in the offline setting, a GD-trained overparameterized neural network can provably learn such function to predict the model of target domain instead of solving a designated ERM problem. Finally, we also consider an online setting and propose a label efficient online algorithm, which predicts parameters for new targets given an arbitrary sequence of mixing coefficients, while enjoying regret guarantees.
On the Hardness of Robustness Transfer: A Perspective from Rademacher Complexity over Symmetric Difference Hypothesis Space
Feb 23, 2023


Recent studies demonstrated that the adversarially robust learning under $\ell_\infty$ attack is harder to generalize to different domains than standard domain adaptation. How to transfer robustness across different domains has been a key question in domain adaptation field. To investigate the fundamental difficulty behind adversarially robust domain adaptation (or robustness transfer), we propose to analyze a key complexity measure that controls the cross-domain generalization: the adversarial Rademacher complexity over {\em symmetric difference hypothesis space} $\mathcal{H} \Delta \mathcal{H}$. For linear models, we show that adversarial version of this complexity is always greater than the non-adversarial one, which reveals the intrinsic hardness of adversarially robust domain adaptation. We also establish upper bounds on this complexity measure. Then we extend them to the ReLU neural network class by upper bounding the adversarial Rademacher complexity in the binary classification setting. Finally, even though the robust domain adaptation is provably harder, we do find positive relation between robust learning and standard domain adaptation. We explain \emph{how adversarial training helps domain adaptation in terms of standard risk}. We believe our results initiate the study of the generalization theory of adversarially robust domain adaptation, and could shed lights on distributed adversarially robust learning from heterogeneous sources, e.g., federated learning scenario.