 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Online RLHF with Generalized Bilinear Preferences
Feb 26, 2026We consider the problem of contextual online RLHF with general preferences, where the goal is to identify the Nash Equilibrium. We adopt the Generalized Bilinear Preference Model (GBPM) to capture potentially intransitive preferences via low-rank, skew-symmetric matrices. We investigate general preference learning with any strongly convex regularizer (where $η^{-1}$ is the regularization strength), generalizing beyond prior works limited to reverse KL-regularization. Central to our analysis is proving that the dual gap of the greedy policy is bounded by the square of the estimation error - a result derived solely from strong convexity and the skew-symmetricity of GBPM.Building on this insight and a feature diversity assumption, we establish two regret bounds via two simple algorithms: (1) Greedy Sampling achieves polylogarithmic, $e^{O(η)}$-free regret $\tilde{O}(ηd^4 (\log T)^2)$. (2) Explore-Then-Commit achieves $\mathrm{poly}(d)$-free regret $\tilde{O}(\sqrt{ηr T})$ by exploiting the low-rank structure; this is the first statistically efficient guarantee for online RLHF in high-dimensions.
Fixed Budget is No Harder Than Fixed Confidence in Best-Arm Identification up to Logarithmic Factors
Feb 03, 2026The best-arm identification (BAI) problem is one of the most fundamental problems in interactive machine learning, which has two flavors: the fixed-budget setting (FB) and the fixed-confidence setting (FC). For $K$-armed bandits with the unique best arm, the optimal sample complexities for both settings have been settled down, and they match up to logarithmic factors. This prompts an interesting research question about the generic, potentially structured BAI problems: Is FB harder than FC or the other way around? In this paper, we show that FB is no harder than FC up to logarithmic factors. We do this constructively: we propose a novel algorithm called FC2FB (fixed confidence to fixed budget), which is a meta algorithm that takes in an FC algorithm $\mathcal{A}$ and turn it into an FB algorithm. We prove that this FC2FB enjoys a sample complexity that matches, up to logarithmic factors, that of the sample complexity of $\mathcal{A}$. This means that the optimal FC sample complexity is an upper bound of the optimal FB sample complexity up to logarithmic factors. Our result not only reveals a fundamental relationship between FB and FC, but also has a significant implication: FC2FB, combined with existing state-of-the-art FC algorithms, leads to improved sample complexity for a number of FB problems.
Nearly Optimal Active Preference Learning and Its Application to LLM Alignment
Feb 02, 2026Aligning large language models (LLMs) depends on high-quality datasets of human preference labels, which are costly to collect. Although active learning has been studied to improve sample efficiency relative to passive collection, many existing approaches adopt classical experimental design criteria such as G- or D-optimality. These objectives are not tailored to the structure of preference learning, leaving open the design of problem-specific algorithms. In this work, we identify a simple intuition specific to preference learning that calls into question the suitability of these existing design objectives. Motivated by this insight, we propose two active learning algorithms. The first provides the first instance-dependent label complexity guarantee for this setting, and the second is a simple, practical greedy method. We evaluate our algorithm on real-world preference datasets and observe improved sample efficiency compared to existing methods.
Coverage Improvement and Fast Convergence of On-policy Preference Learning
Jan 13, 2026Online on-policy preference learning algorithms for language model alignment such as online direct policy optimization (DPO) can significantly outperform their offline counterparts. We provide a theoretical explanation for this phenomenon by analyzing how the sampling policy's coverage evolves throughout on-policy training. We propose and rigorously justify the \emph{coverage improvement principle}: with sufficient batch size, each update moves into a region around the target where coverage is uniformly better, making subsequent data increasingly informative and enabling rapid convergence. In the contextual bandit setting with Bradley-Terry preferences and linear softmax policy class, we show that on-policy DPO converges exponentially in the number of iterations for batch size exceeding a generalized coverage threshold. In contrast, any learner restricted to offline samples from the initial policy suffers a slower minimax rate, leading to a sharp separation in total sample complexity. Motivated by this analysis, we further propose a simple hybrid sampler based on a novel \emph{preferential} G-optimal design, which removes dependence on coverage and guarantees convergence in just two rounds. Finally, we develop principled on-policy schemes for reward distillation in the general function class setting, and show faster noiseless rates under an alternative deviation-based notion of coverage. Experimentally, we confirm that on-policy DPO and our proposed reward distillation algorithms outperform their off-policy counterparts and enjoy stable, monotonic performance gains across iterations.
Learning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.
Achieving adaptivity and optimality for multi-armed bandits using Exponential-Kullback Leiblier Maillard Sampling
Feb 20, 2025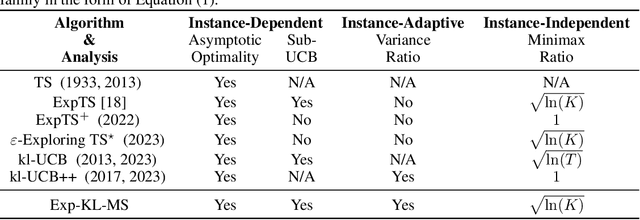


We study the problem of Multi-Armed Bandits (MAB) with reward distributions belonging to a One-Parameter Exponential Distribution (OPED) family. In the literature, several criteria have been proposed to evaluate the performance of such algorithms, including Asymptotic Optimality (A.O.), Minimax Optimality (M.O.), Sub-UCB, and variance-adaptive worst-case regret bound. Thompson Sampling (TS)-based and Upper Confidence Bound (UCB)-based algorithms have been employed to achieve some of these criteria. However, none of these algorithms simultaneously satisfy all the aforementioned criteria. In this paper, we design an algorithm, Exponential Kullback-Leibler Maillard Sampling (abbrev. \expklms), that can achieve multiple optimality criteria simultaneously, including A.O., M.O. with a logarithmic factor, Sub-UCB, and variance-adaptive worst-case regret bound.
Fixing the Loose Brake: Exponential-Tailed Stopping Time in Best Arm Identification
Nov 04, 2024

The best arm identification problem requires identifying the best alternative (i.e., arm) in active experimentation using the smallest number of experiments (i.e., arm pulls), which is crucial for cost-efficient and timely decision-making processes. In the fixed confidence setting, an algorithm must stop data-dependently and return the estimated best arm with a correctness guarantee. Since this stopping time is random, we desire its distribution to have light tails. Unfortunately, many existing studies focus on high probability or in expectation bounds on the stopping time, which allow heavy tails and, for high probability bounds, even not stopping at all. We first prove that this never-stopping event can indeed happen for some popular algorithms. Motivated by this, we propose algorithms that provably enjoy an exponential-tailed stopping time, which improves upon the polynomial tail bound reported by Kalyanakrishnan et al. (2012). The first algorithm is based on a fixed budget algorithm called Sequential Halving along with a doubling trick. The second algorithm is a meta algorithm that takes in any fixed confidence algorithm with a high probability stopping guarantee and turns it into one that enjoys an exponential-tailed stopping time. Our results imply that there is much more to be desired for contemporary fixed confidence algorithms.
HAVER: Instance-Dependent Error Bounds for Maximum Mean Estimation and Applications to Q-Learning
Nov 01, 2024We study the problem of estimating the \emph{value} of the largest mean among $K$ distributions via samples from them (rather than estimating \emph{which} distribution has the largest mean), which arises from various machine learning tasks including Q-learning and Monte Carlo tree search. While there have been a few proposed algorithms, their performance analyses have been limited to their biases rather than a precise error metric. In this paper, we propose a novel algorithm called HAVER (Head AVERaging) and analyze its mean squared error. Our analysis reveals that HAVER has a compelling performance in two respects. First, HAVER estimates the maximum mean as well as the oracle who knows the identity of the best distribution and reports its sample mean. Second, perhaps surprisingly, HAVER exhibits even better rates than this oracle when there are many distributions near the best one. Both of these improvements are the first of their kind in the literature, and we also prove that the naive algorithm that reports the largest empirical mean does not achieve these bounds. Finally, we confirm our theoretical findings via numerical experiments including bandits and Q-learning scenarios where HAVER outperforms baseline methods.
Minimum Empirical Divergence for Sub-Gaussian Linear Bandits
Oct 31, 2024



We propose a novel linear bandit algorithm called LinMED (Linear Minimum Empirical Divergence), which is a linear extension of the MED algorithm that was originally designed for multi-armed bandits. LinMED is a randomized algorithm that admits a closed-form computation of the arm sampling probabilities, unlike the popular randomized algorithm called linear Thompson sampling. Such a feature proves useful for off-policy evaluation where the unbiased evaluation requires accurately computing the sampling probability. We prove that LinMED enjoys a near-optimal regret bound of $d\sqrt{n}$ up to logarithmic factors where $d$ is the dimension and $n$ is the time horizon. We further show that LinMED enjoys a $\frac{d^2}{\Delta}\left(\log^2(n)\right)\log\left(\log(n)\right)$ problem-dependent regret where $\Delta$ is the smallest sub-optimality gap, which is lower than $\frac{d^2}{\Delta}\log^3(n)$ of the standard algorithm OFUL (Abbasi-yadkori et al., 2011). Our empirical study shows that LinMED has a competitive performance with the state-of-the-art algorithms.
A Unified Confidence Sequence for Generalized Linear Models, with Applications to Bandits
Jul 19, 2024We present a unified likelihood ratio-based confidence sequence (CS) for any (self-concordant) generalized linear models (GLMs) that is guaranteed to be convex and numerically tight. We show that this is on par or improves upon known CSs for various GLMs, including Gaussian, Bernoulli, and Poisson. In particular, for the first time, our CS for Bernoulli has a poly(S)-free radius where S is the norm of the unknown parameter. Our first technical novelty is its derivation, which utilizes a time-uniform PAC-Bayesian bound with a uniform prior/posterior, despite the latter being a rather unpopular choice for deriving CSs. As a direct application of our new CS, we propose a simple and natural optimistic algorithm called OFUGLB applicable to any generalized linear bandits (GLB; Filippi et al. (2010)). Our analysis shows that the celebrated optimistic approach simultaneously attains state-of-the-art regrets for various self-concordant (not necessarily bounded) GLBs, and even poly(S)-free for bounded GLBs, including logistic bandits. The regret analysis, our second technical novelty, follows from combining our new CS with a new proof technique that completely avoids the previously widely used self-concordant control lemma (Faury et al., 2020, Lemma 9). Finally, we verify numerically that OFUGLB significantly outperforms the prior state-of-the-art (Lee et al., 2024) for logistic bandits.