 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explainable Dense Reward Shapes via Bayesian Optimization
Apr 22, 2025Current reinforcement learning from human feedback (RLHF) pipelines for large language model (LLM) alignment typically assign scalar rewards to sequences, using the final token as a surrogate indicator for the quality of the entire sequence. However, this leads to sparse feedback and suboptimal token-level credit assignment. In this work, we frame reward shaping as an optimization problem focused on token-level credit assignment. We propose a reward-shaping function leveraging explainability methods such as SHAP and LIME to estimate per-token rewards from the reward model. To learn parameters of this shaping function, we employ a bilevel optimization framework that integrates Bayesian Optimization and policy training to handle noise from the token reward estimates. Our experiments show that achieving a better balance of token-level reward attribution leads to performance improvements over baselines on downstream tasks and finds an optimal policy faster during training. Furthermore, we show theoretically that explainability methods that are feature additive attribution functions maintain the optimal policy as the original reward.
Reinforcement Learning with Dynamic Multi-Reward Weighting for Multi-Style Controllable Generation
Feb 21, 2024Style is an integral component of text that expresses a diverse set of information, including interpersonal dynamics (e.g. formality) and the author's emotions or attitudes (e.g. disgust). Humans often employ multiple styles simultaneously. An open question is how large language models can be explicitly controlled so that they weave together target styles when generating text: for example, to produce text that is both negative and non-toxic. Previous work investigates the controlled generation of a single style, or else controlled generation of a style and other attributes. In this paper, we expand this into controlling multiple styles simultaneously. Specifically, we investigate various formulations of multiple style rewards for a reinforcement learning (RL) approach to controlled multi-style generation. These reward formulations include calibrated outputs from discriminators and dynamic weighting by discriminator gradient magnitudes. We find that dynamic weighting generally outperforms static weighting approaches, and we explore its effectiveness in 2- and 3-style control, even compared to strong baselines like plug-and-play model. All code and data for RL pipelines with multiple style attributes will be publicly available.
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
Benchmarking Cognitive Biases in Large Language Models as Evaluators
Sep 29, 2023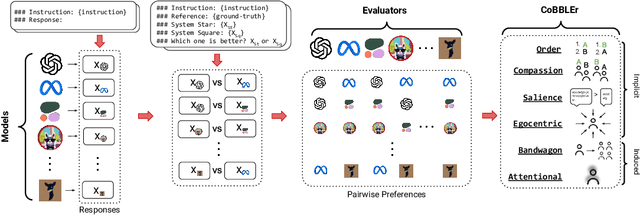



Large Language Models (LLMs) have recently been shown to be effective as automatic evaluators with simple prompting and in-context learning. In this work, we assemble 15 LLMs of four different size ranges and evaluate their output responses by preference ranking from the other LLMs as evaluators, such as System Star is better than System Square. We then evaluate the quality of ranking outputs introducing the Cognitive Bias Benchmark for LLMs as Evaluators (CoBBLEr), a benchmark to measure six different cognitive biases in LLM evaluation outputs, such as the Egocentric bias where a model prefers to rank its own outputs highly in evaluation. We find that LLMs are biased text quality evaluators, exhibiting strong indications on our bias benchmark (average of 40% of comparisons across all models) within each of their evaluations that question their robustness as evaluators. Furthermore, we examine the correlation between human and machine preferences and calculate the average Rank-Biased Overlap (RBO) score to be 49.6%, indicating that machine preferences are misaligned with humans. According to our findings, LLMs may still be unable to be utilized for automatic annotation aligned with human preferences. Our project page is at: https://minnesotanlp.github.io/cobbler.
CoEdIT: Text Editing by Task-Specific Instruction Tuning
May 17, 2023Text editing or revision is an essential function of the human writing process. Understanding the capabilities of LLMs for making high-quality revisions and collaborating with human writers is a critical step toward building effective writing assistants. With the prior success of LLMs and instruction tuning, we leverage instruction-tuned LLMs for text revision to improve the quality of user-generated text and improve the efficiency of the process. We introduce CoEdIT, a state-of-the-art text editing model for writing assistance. CoEdIT takes instructions from the user specifying the attributes of the desired text, such as "Make the sentence simpler" or "Write it in a more neutral style," and outputs the edited text. We present a large language model fine-tuned on a diverse collection of task-specific instructions for text editing (a total of 82K instructions). Our model (1) achieves state-of-the-art performance on various text editing benchmarks, (2) is competitive with publicly available largest-sized LLMs trained on instructions while being $\sim$60x smaller, (3) is capable of generalizing to unseen edit instructions, and (4) exhibits compositional comprehension abilities to generalize to instructions containing different combinations of edit actions. Through extensive qualitative and quantitative analysis, we show that writers prefer the edits suggested by CoEdIT, relative to other state-of-the-art text editing models. Our code and dataset are publicly available.
Decoding the End-to-end Writing Trajectory in Scholarly Manuscripts
Mar 31, 2023Scholarly writing presents a complex space that generally follows a methodical procedure to plan and produce both rationally sound and creative compositions. Recent works involving large language models (LLM) demonstrate considerable success in text generation and revision tasks; however, LLMs still struggle to provide structural and creative feedback on the document level that is crucial to academic writing. In this paper, we introduce a novel taxonomy that categorizes scholarly writing behaviors according to intention, writer actions, and the information types of the written data. We also provide ManuScript, an original dataset annotated with a simplified version of our taxonomy to show writer actions and the intentions behind them. Motivated by cognitive writing theory, our taxonomy for scientific papers includes three levels of categorization in order to trace the general writing flow and identify the distinct writer activities embedded within each higher-level process. ManuScript intends to provide a complete picture of the scholarly writing process by capturing the linearity and non-linearity of writing trajectory, such that writing assistants can provide stronger feedback and suggestions on an end-to-end level. The collected writing trajectories are viewed at https://minnesotanlp.github.io/REWARD_demo/