 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the End-to-end Writing Trajectory in Scholarly Manuscripts
Mar 31, 2023Scholarly writing presents a complex space that generally follows a methodical procedure to plan and produce both rationally sound and creative compositions. Recent works involving large language models (LLM) demonstrate considerable success in text generation and revision tasks; however, LLMs still struggle to provide structural and creative feedback on the document level that is crucial to academic writing. In this paper, we introduce a novel taxonomy that categorizes scholarly writing behaviors according to intention, writer actions, and the information types of the written data. We also provide ManuScript, an original dataset annotated with a simplified version of our taxonomy to show writer actions and the intentions behind them. Motivated by cognitive writing theory, our taxonomy for scientific papers includes three levels of categorization in order to trace the general writing flow and identify the distinct writer activities embedded within each higher-level process. ManuScript intends to provide a complete picture of the scholarly writing process by capturing the linearity and non-linearity of writing trajectory, such that writing assistants can provide stronger feedback and suggestions on an end-to-end level. The collected writing trajectories are viewed at https://minnesotanlp.github.io/REWARD_demo/
PAUSE: Positive and Annealed Unlabeled Sentence Embedding
Sep 07, 2021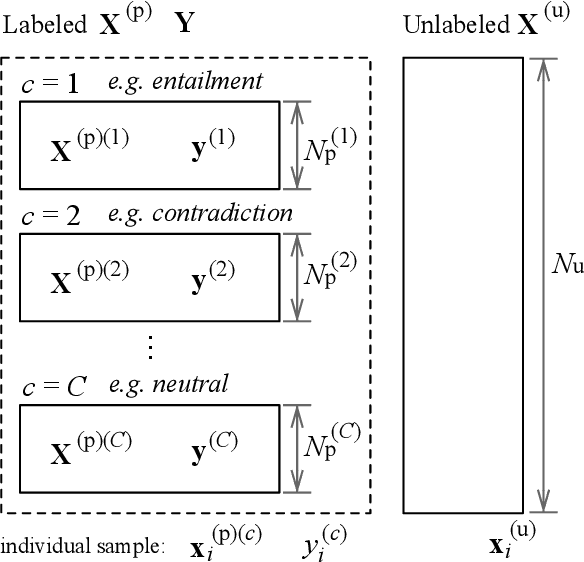
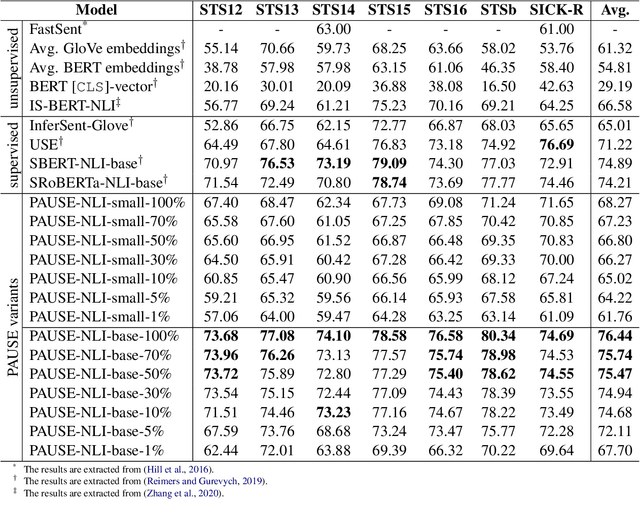
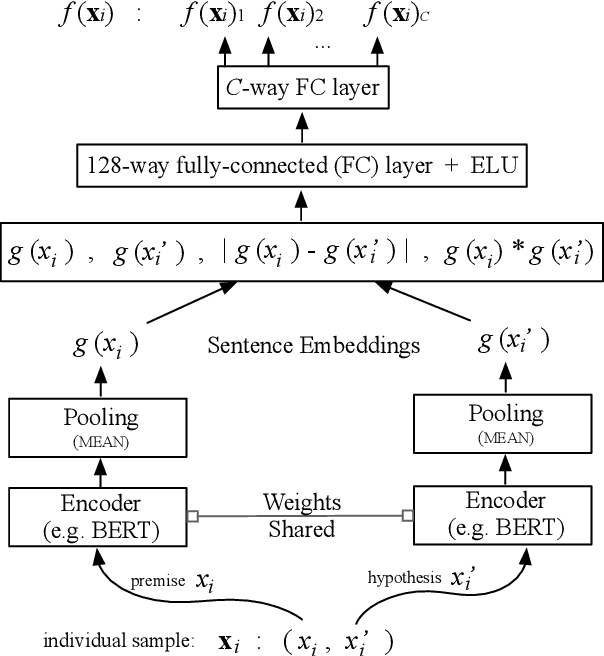
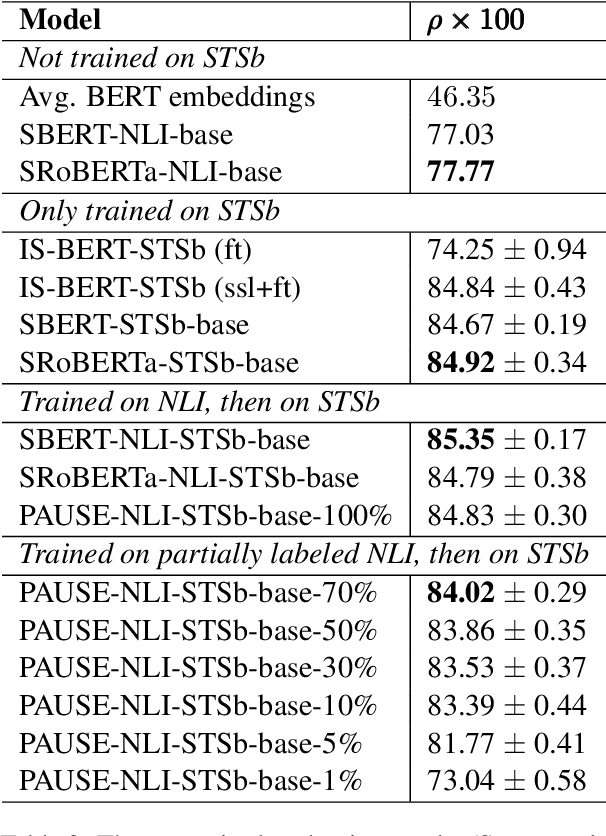
Sentence embedding refers to a set of effective and versatile techniques for converting raw text into numerical vector representations that can be used in a wide range of natural language processing (NLP) applications. The majority of these techniques are either supervised or unsupervised. Compared to the unsupervised methods, the supervised ones make less assumptions about optimization objectives and usually achieve better results. However, the training requires a large amount of labeled sentence pairs, which is not available in many industrial scenarios. To that end, we propose a generic and end-to-end approach -- PAUSE (Positive and Annealed Unlabeled Sentence Embedding), capable of learning high-quality sentence embeddings from a partially labeled dataset. We experimentally show that PAUSE achieves, and sometimes surpasses, state-of-the-art results using only a small fraction of labeled sentence pairs on various benchmark tasks. When applied to a real industrial use case where labeled samples are scarce, PAUSE encourages us to extend our dataset without the liability of extensive manual annotation work.