 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Informed Revenue Extrapolation with Confidence Estimate for Scaleup Companies Using Scarce Time-Series Data
Aug 23, 2022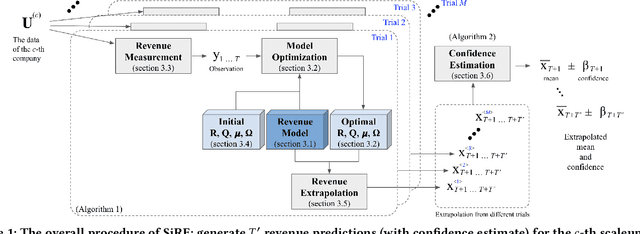
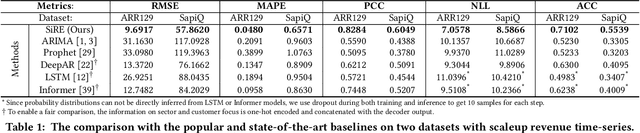
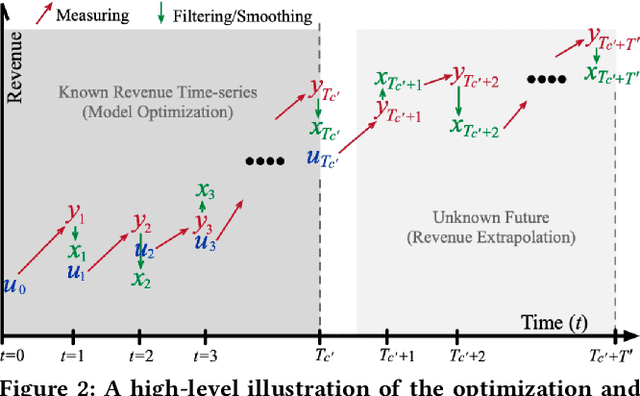
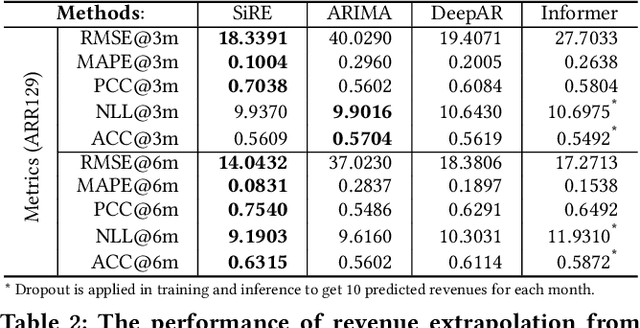
Investment professionals rely on extrapolating company revenue into the future (i.e. revenue forecast) to approximate the valuation of scaleups (private companies in a high-growth stage) and inform their investment decision. This task is manual and empirical, leaving the forecast quality heavily dependent on the investment professionals' experiences and insights. Furthermore, financial data on scaleups is typically proprietary, costly and scarce, ruling out the wide adoption of data-driven approaches. To this end, we propose a simulation-informed revenue extrapolation (SiRE) algorithm that generates fine-grained long-term revenue predictions on small datasets and short time-series. SiRE models the revenue dynamics as a linear dynamical system (LDS), which is solved using the EM algorithm. The main innovation lies in how the noisy revenue measurements are obtained during training and inferencing. SiRE works for scaleups that operate in various sectors and provides confidence estimates. The quantitative experiments on two practical tasks show that SiRE significantly surpasses the baseline methods by a large margin. We also observe high performance when SiRE extrapolates long-term predictions from short time-series. The performance-efficiency balance and result explainability of SiRE are also validated empirically. Evaluated from the perspective of investment professionals, SiRE can precisely locate the scaleups that have a great potential return in 2 to 5 years. Furthermore, our qualitative inspection illustrates some advantageous attributes of the SiRE revenue forecasts.
PAUSE: Positive and Annealed Unlabeled Sentence Embedding
Sep 07, 2021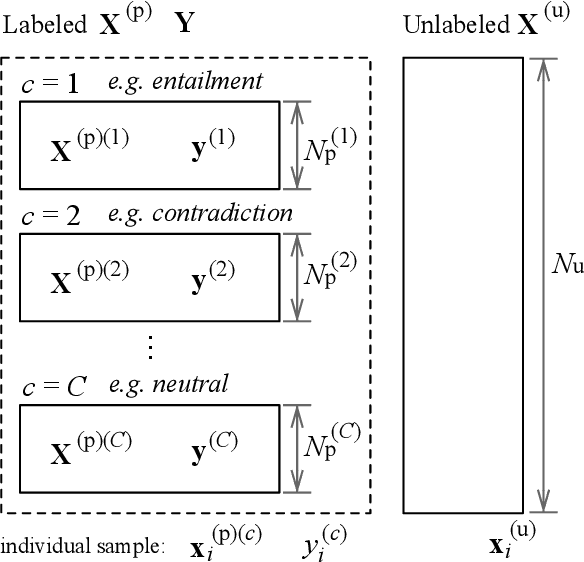
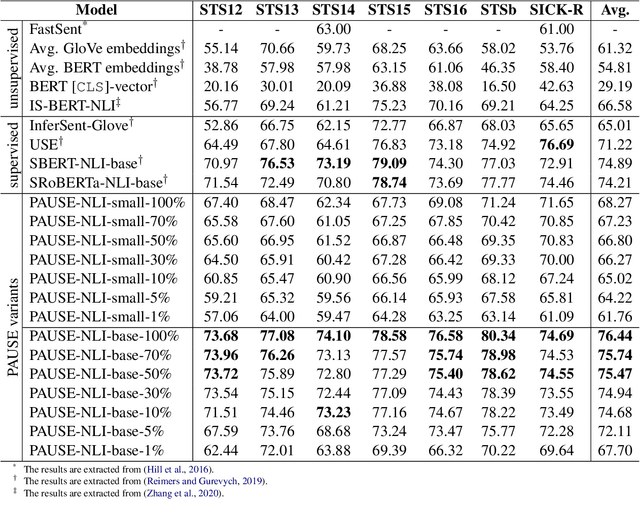
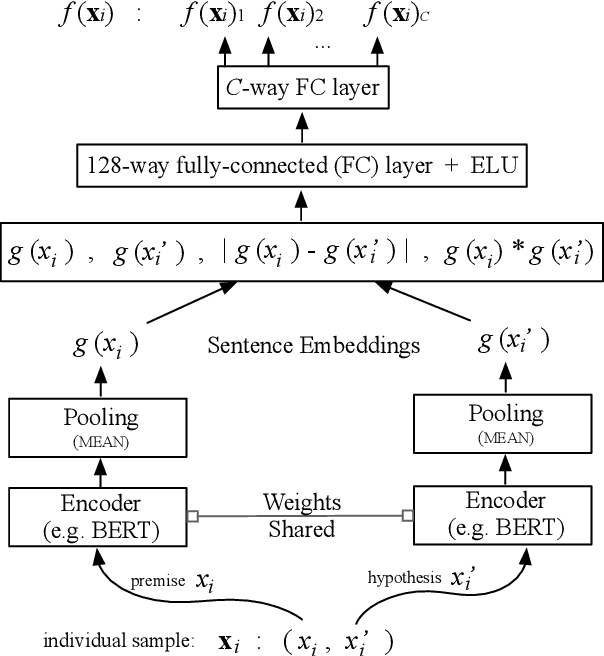
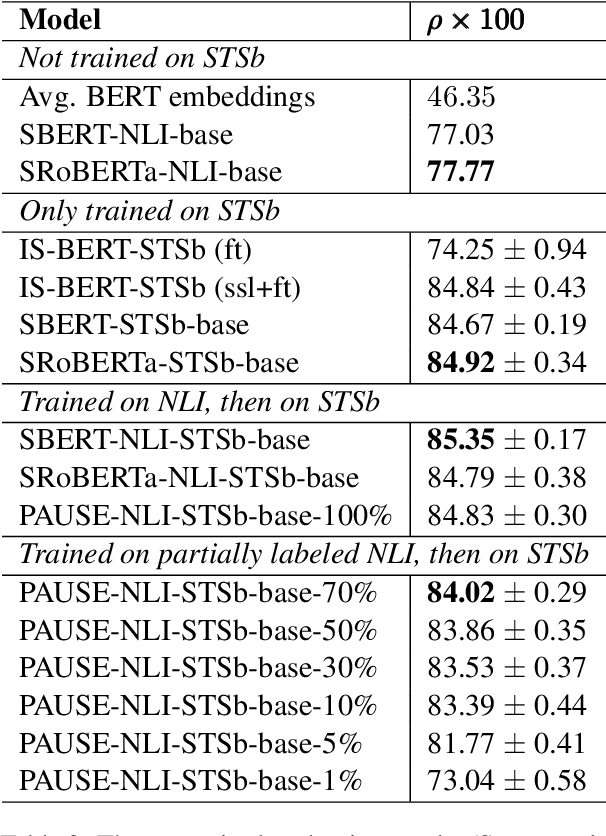
Sentence embedding refers to a set of effective and versatile techniques for converting raw text into numerical vector representations that can be used in a wide range of natural language processing (NLP) applications. The majority of these techniques are either supervised or unsupervised. Compared to the unsupervised methods, the supervised ones make less assumptions about optimization objectives and usually achieve better results. However, the training requires a large amount of labeled sentence pairs, which is not available in many industrial scenarios. To that end, we propose a generic and end-to-end approach -- PAUSE (Positive and Annealed Unlabeled Sentence Embedding), capable of learning high-quality sentence embeddings from a partially labeled dataset. We experimentally show that PAUSE achieves, and sometimes surpasses, state-of-the-art results using only a small fraction of labeled sentence pairs on various benchmark tasks. When applied to a real industrial use case where labeled samples are scarce, PAUSE encourages us to extend our dataset without the liability of extensive manual annotation work.