 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealing Creator's Workflow: A Creator-Inspired Agentic Framework with Iterative Feedback Loop for Improved Scientific Short-form Generation
Apr 26, 2025Generating engaging, accurate short-form videos from scientific papers is challenging due to content complexity and the gap between expert authors and readers. Existing end-to-end methods often suffer from factual inaccuracies and visual artifacts, limiting their utility for scientific dissemination. To address these issues, we propose SciTalk, a novel multi-LLM agentic framework, grounding videos in various sources, such as text, figures, visual styles, and avatars. Inspired by content creators' workflows, SciTalk uses specialized agents for content summarization, visual scene planning, and text and layout editing, and incorporates an iterative feedback mechanism where video agents simulate user roles to give feedback on generated videos from previous iterations and refine generation prompts. Experimental evaluations show that SciTalk outperforms simple prompting methods in generating scientifically accurate and engaging content over the refined loop of video generation. Although preliminary results are still not yet matching human creators' quality, our framework provides valuable insights into the challenges and benefits of feedback-driven video generation. Our code, data, and generated videos will be publicly available.
A Framework for Robust Cognitive Evaluation of LLMs
Apr 03, 2025Emergent cognitive abilities in large language models (LLMs) have been widely observed, but their nature and underlying mechanisms remain poorly understood. A growing body of research draws on cognitive science to investigate LLM cognition, but standard methodologies and experimen-tal pipelines have not yet been established. To address this gap we develop CognitivEval, a framework for systematically evaluating the artificial cognitive capabilities of LLMs, with a particular emphasis on robustness in response collection. The key features of CognitivEval include: (i) automatic prompt permutations, and (ii) testing that gathers both generations and model probability estimates. Our experiments demonstrate that these features lead to more robust experimental outcomes. Using CognitivEval, we replicate five classic experiments in cognitive science, illustrating the framework's generalizability across various experimental tasks and obtaining a cognitive profile of several state of the art LLMs. CognitivEval will be released publicly to foster broader collaboration within the cognitive science community.
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Jan 29, 2024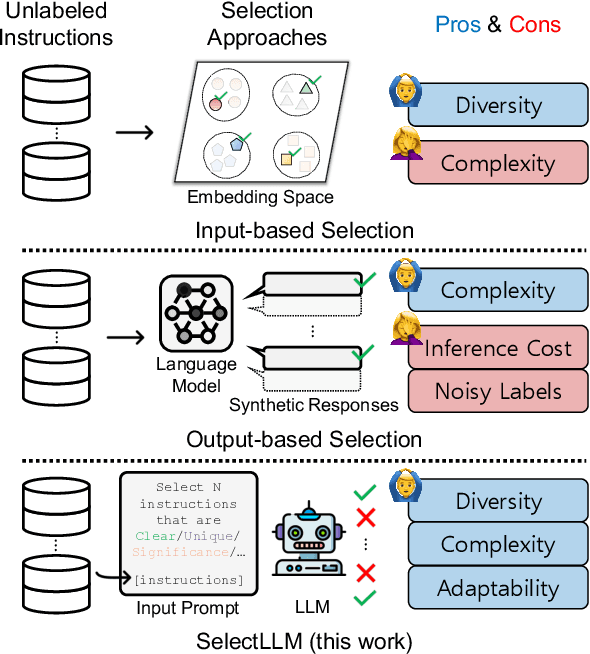



Training large language models (LLMs) with a large and diverse instruction dataset aligns the models to comprehend and follow human instructions. Recent works have shown that using a small set of high-quality instructions can outperform using large yet more noisy ones. Because instructions are unlabeled and their responses are natural text, traditional active learning schemes with the model's confidence cannot be directly applied to the selection of unlabeled instructions. In this work, we propose a novel method for instruction selection, called SelectLLM, that leverages LLMs for the selection of high-quality instructions. Our high-level idea is to use LLMs to estimate the usefulness and impactfulness of each instruction without the corresponding labels (i.e., responses), via prompting. SelectLLM involves two steps: dividing the unlabelled instructions using a clustering algorithm (e.g., CoreSet) to multiple clusters, and then prompting LLMs to choose high-quality instructions within each cluster. SelectLLM showed comparable or slightly better performance on the popular instruction benchmarks, compared to the recent state-of-the-art selection methods. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).
Benchmarking Cognitive Biases in Large Language Models as Evaluators
Sep 29, 2023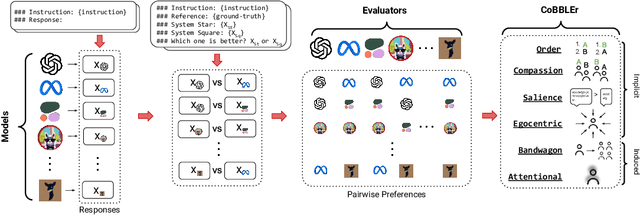



Large Language Models (LLMs) have recently been shown to be effective as automatic evaluators with simple prompting and in-context learning. In this work, we assemble 15 LLMs of four different size ranges and evaluate their output responses by preference ranking from the other LLMs as evaluators, such as System Star is better than System Square. We then evaluate the quality of ranking outputs introducing the Cognitive Bias Benchmark for LLMs as Evaluators (CoBBLEr), a benchmark to measure six different cognitive biases in LLM evaluation outputs, such as the Egocentric bias where a model prefers to rank its own outputs highly in evaluation. We find that LLMs are biased text quality evaluators, exhibiting strong indications on our bias benchmark (average of 40% of comparisons across all models) within each of their evaluations that question their robustness as evaluators. Furthermore, we examine the correlation between human and machine preferences and calculate the average Rank-Biased Overlap (RBO) score to be 49.6%, indicating that machine preferences are misaligned with humans. According to our findings, LLMs may still be unable to be utilized for automatic annotation aligned with human preferences. Our project page is at: https://minnesotanlp.github.io/cobbler.