 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021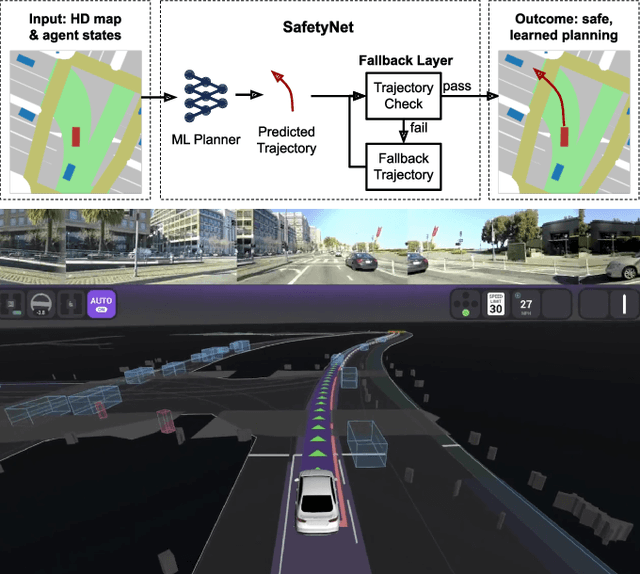
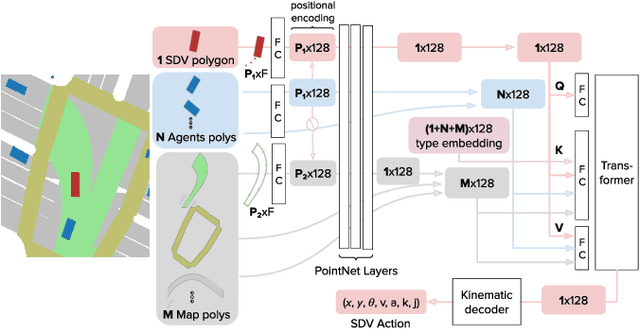
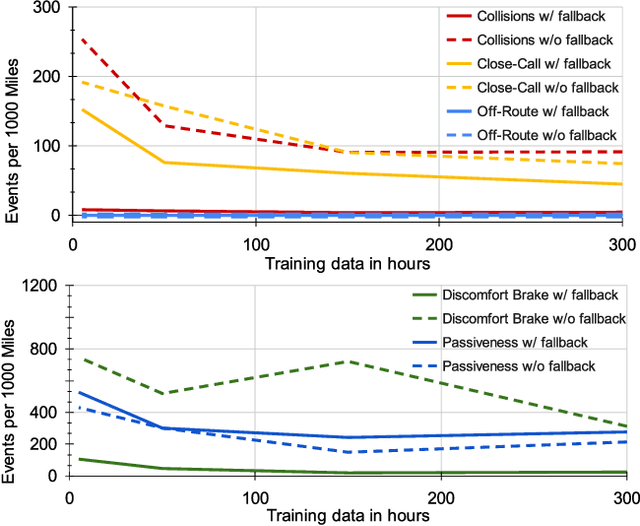
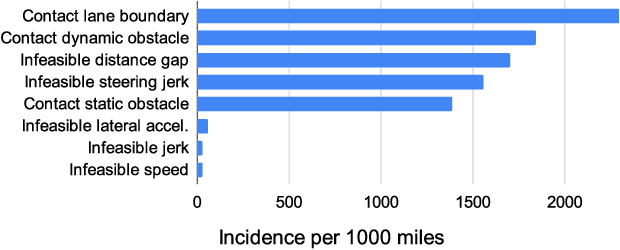
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.
Autonomy 2.0: Why is self-driving always 5 years away?
Aug 09, 2021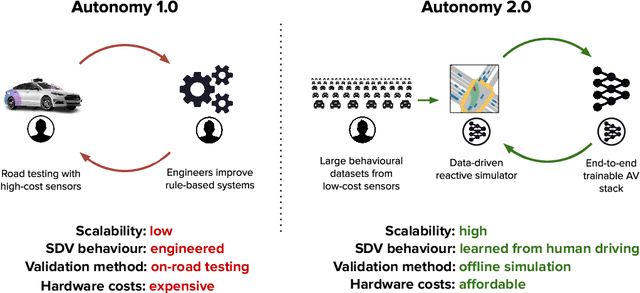

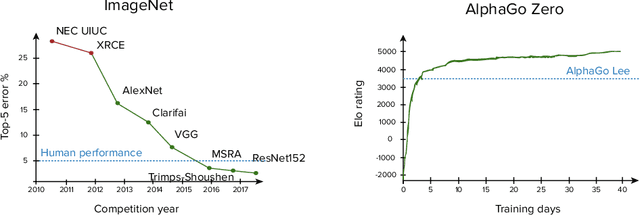
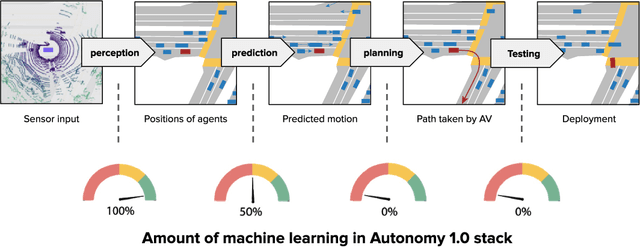
Despite the numerous successes of machine learning over the past decade (image recognition, decision-making, NLP, image synthesis), self-driving technology has not yet followed the same trend. In this paper, we study the history, composition, and development bottlenecks of the modern self-driving stack. We argue that the slow progress is caused by approaches that require too much hand-engineering, an over-reliance on road testing, and high fleet deployment costs. We observe that the classical stack has several bottlenecks that preclude the necessary scale needed to capture the long tail of rare events. To resolve these problems, we outline the principles of Autonomy 2.0, an ML-first approach to self-driving, as a viable alternative to the currently adopted state-of-the-art. This approach is based on (i) a fully differentiable AV stack trainable from human demonstrations, (ii) closed-loop data-driven reactive simulation, and (iii) large-scale, low-cost data collections as critical solutions towards scalability issues. We outline the general architecture, survey promising works in this direction and propose key challenges to be addressed by the community in the future.
One Thousand and One Hours: Self-driving Motion Prediction Dataset
Jun 25, 2020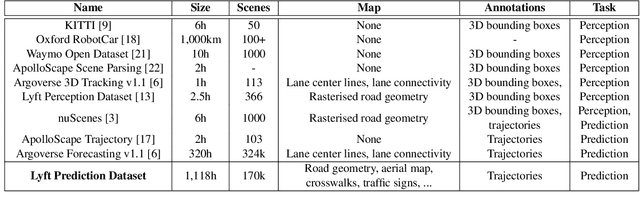

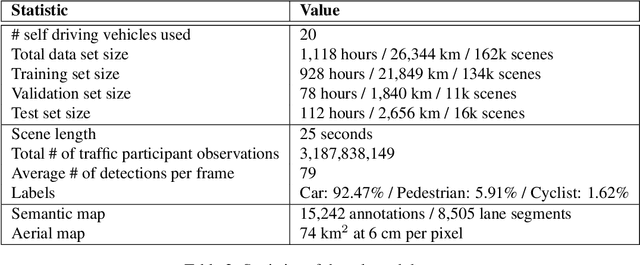
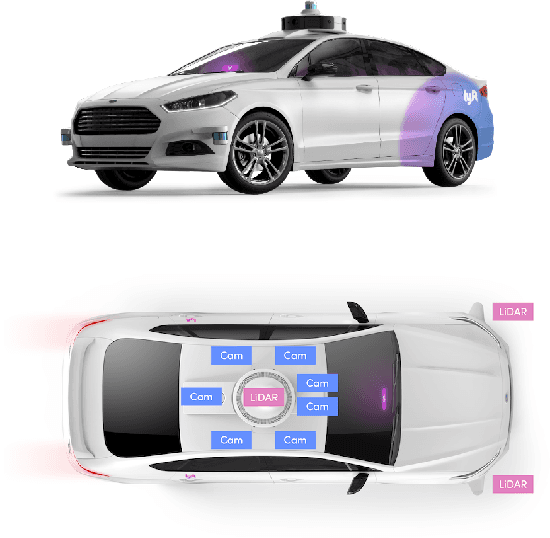
We present the largest self-driving dataset for motion prediction to date, with over 1,000 hours of data. This was collected by a fleet of 20 autonomous vehicles along a fixed route in Palo Alto, California over a four-month period. It consists of 170,000 scenes, where each scene is 25 seconds long and captures the perception output of the self-driving system, which encodes the precise positions and motions of nearby vehicles, cyclists, and pedestrians over time. On top of this, the dataset contains a high-definition semantic map with 15,242 labelled elements and a high-definition aerial view over the area. Together with the provided software kit, this collection forms the largest, most complete and detailed dataset to date for the development of self-driving, machine learning tasks such as motion forecasting, planning and simulation. The full dataset is available at http://level5.lyft.com/.
PointFusion: Deep Sensor Fusion for 3D Bounding Box Estimation
Aug 25, 2018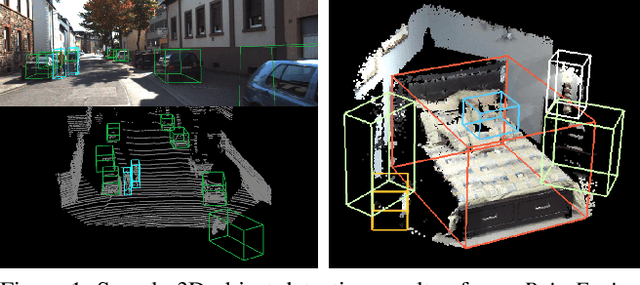
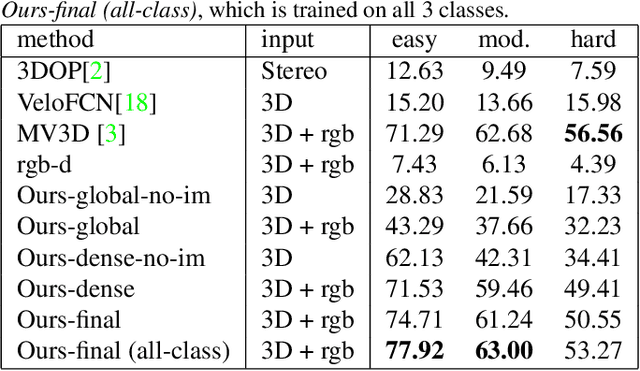
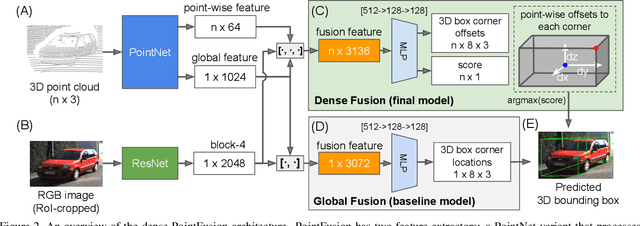
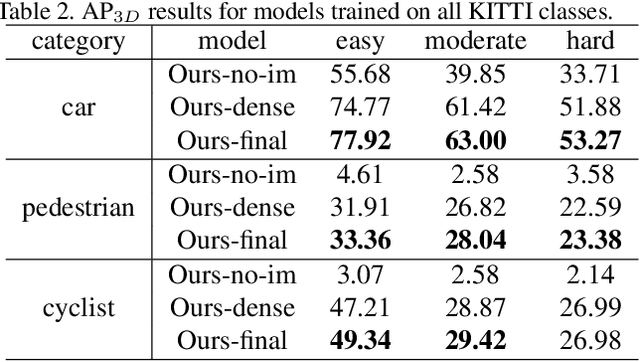
We present PointFusion, a generic 3D object detection method that leverages both image and 3D point cloud information. Unlike existing methods that either use multi-stage pipelines or hold sensor and dataset-specific assumptions, PointFusion is conceptually simple and application-agnostic. The image data and the raw point cloud data are independently processed by a CNN and a PointNet architecture, respectively. The resulting outputs are then combined by a novel fusion network, which predicts multiple 3D box hypotheses and their confidences, using the input 3D points as spatial anchors. We evaluate PointFusion on two distinctive datasets: the KITTI dataset that features driving scenes captured with a lidar-camera setup, and the SUN-RGBD dataset that captures indoor environments with RGB-D cameras. Our model is the first one that is able to perform better or on-par with the state-of-the-art on these diverse datasets without any dataset-specific model tuning.
Structural-RNN: Deep Learning on Spatio-Temporal Graphs
Apr 11, 2016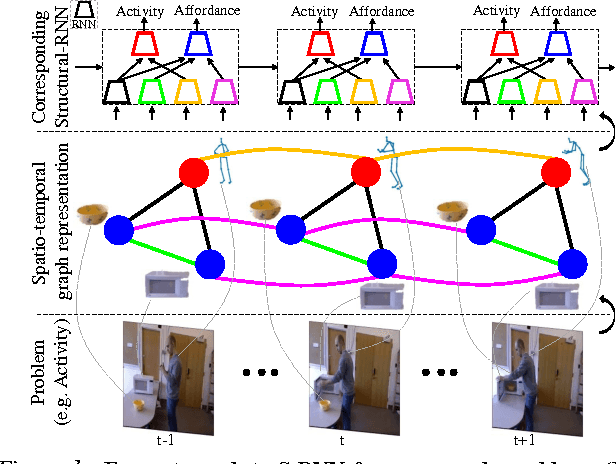
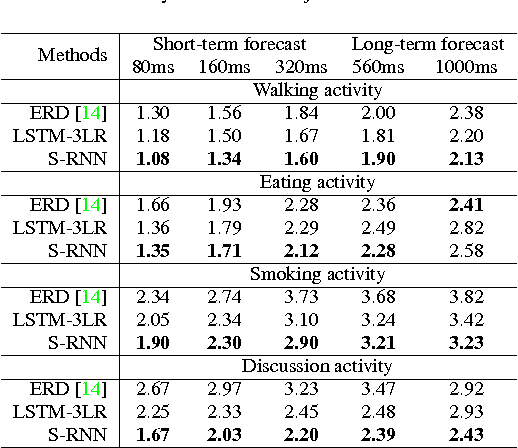
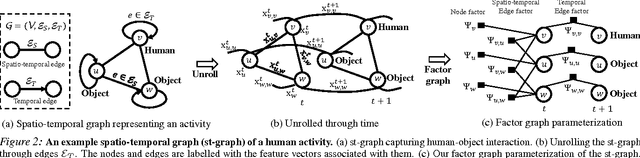
Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks~(RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower new approaches to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks.
Learning Preferences for Manipulation Tasks from Online Coactive Feedback
Jan 05, 2016
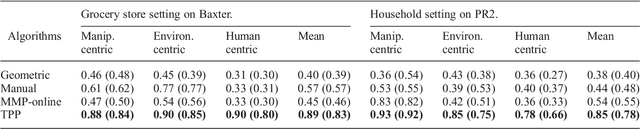

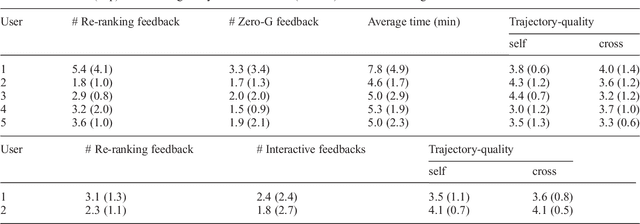
We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than simple geometric constraints on trajectories; they are rather governed by the surrounding context of various objects and human interactions in the environment. We propose a coactive online learning framework for teaching preferences in contextually rich environments. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this coactive preference feedback can be more easily elicited than demonstrations of optimal trajectories. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We implement our algorithm on two high degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings -- household chores and grocery store checkout -- and show that users are able to train the robot with just a few feedbacks (taking only a few minutes).\footnote{Parts of this work has been published at NIPS and ISRR conferences~\citep{Jain13,Jain13b}. This journal submission presents a consistent full paper, and also includes the proof of regret bounds, more details of the robotic system, and a thorough related work.}
PlanIt: A Crowdsourcing Approach for Learning to Plan Paths from Large Scale Preference Feedback
Jan 05, 2016
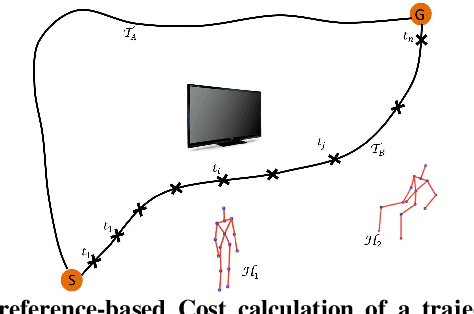
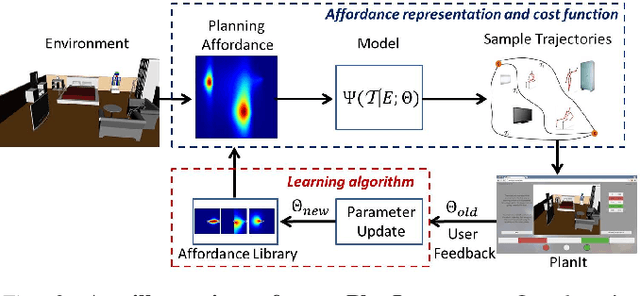
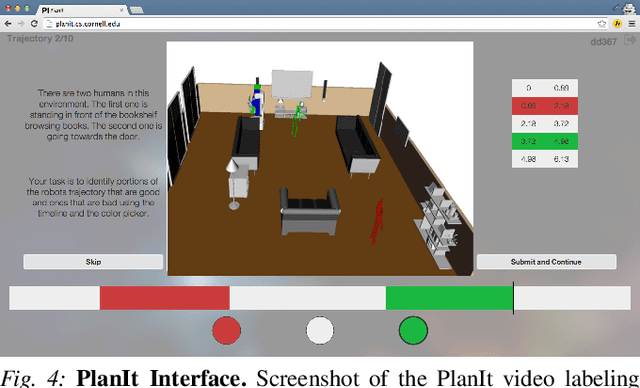
We consider the problem of learning user preferences over robot trajectories for environments rich in objects and humans. This is challenging because the criterion defining a good trajectory varies with users, tasks and interactions in the environment. We represent trajectory preferences using a cost function that the robot learns and uses it to generate good trajectories in new environments. We design a crowdsourcing system - PlanIt, where non-expert users label segments of the robot's trajectory. PlanIt allows us to collect a large amount of user feedback, and using the weak and noisy labels from PlanIt we learn the parameters of our model. We test our approach on 122 different environments for robotic navigation and manipulation tasks. Our extensive experiments show that the learned cost function generates preferred trajectories in human environments. Our crowdsourcing system is publicly available for the visualization of the learned costs and for providing preference feedback: \url{http://planit.cs.cornell.edu}
Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture
Jan 05, 2016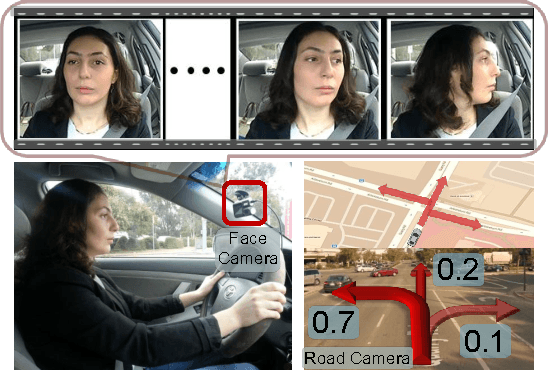

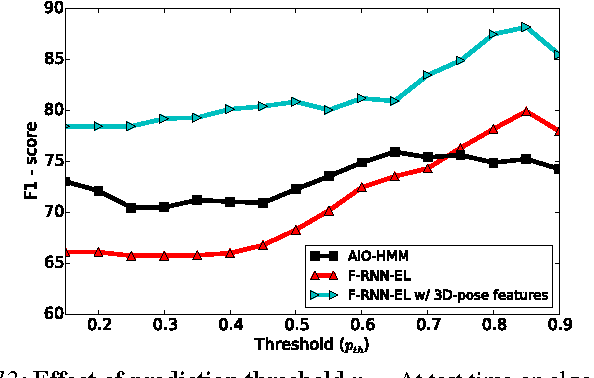
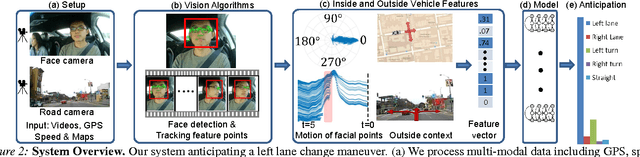
Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. In this work we propose a vehicular sensor-rich platform and learning algorithms for maneuver anticipation. For this purpose we equip a car with cameras, Global Positioning System (GPS), and a computing device to capture the driving context from both inside and outside of the car. In order to anticipate maneuvers, we propose a sensory-fusion deep learning architecture which jointly learns to anticipate and fuse multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We propose a novel training procedure which allows the network to predict the future given only a partial temporal context. We introduce a diverse data set with 1180 miles of natural freeway and city driving, and show that we can anticipate maneuvers 3.5 seconds before they occur in real-time with a precision and recall of 90.5\% and 87.4\% respectively.
Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models
Sep 19, 2015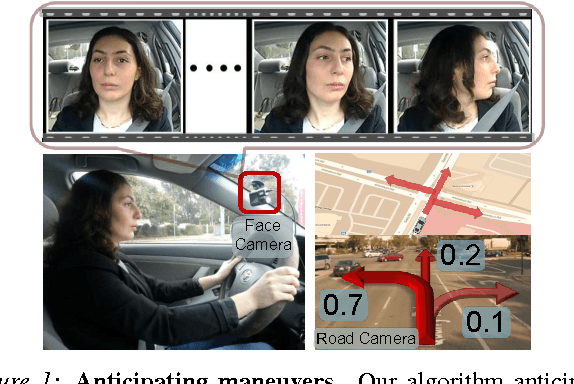
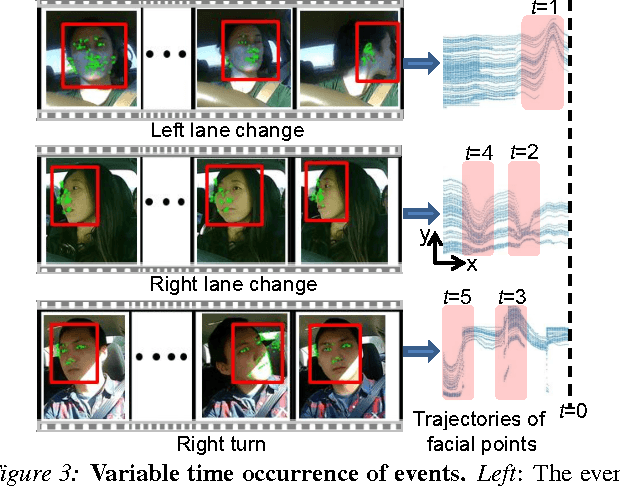
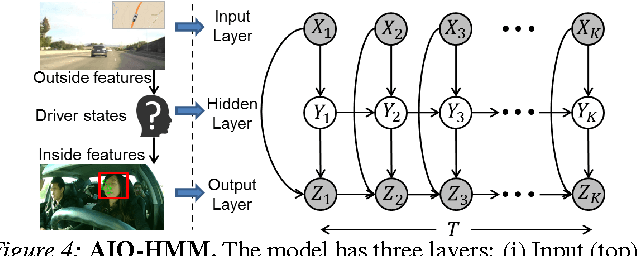
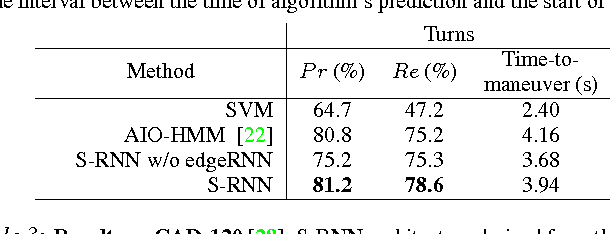
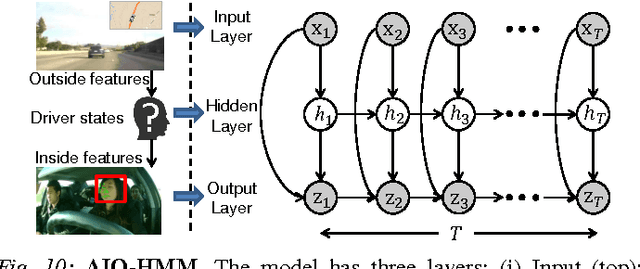
Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. In this work we anticipate driving maneuvers a few seconds before they occur. For this purpose we equip a car with cameras and a computing device to capture the driving context from both inside and outside of the car. We propose an Autoregressive Input-Output HMM to model the contextual information alongwith the maneuvers. We evaluate our approach on a diverse data set with 1180 miles of natural freeway and city driving and show that we can anticipate maneuvers 3.5 seconds before they occur with over 80\% F1-score in real-time.
Recurrent Neural Networks for Driver Activity Anticipation via Sensory-Fusion Architecture
Sep 16, 2015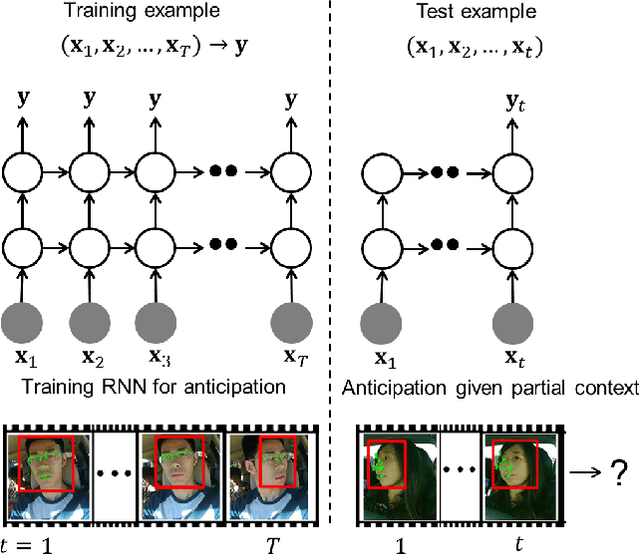

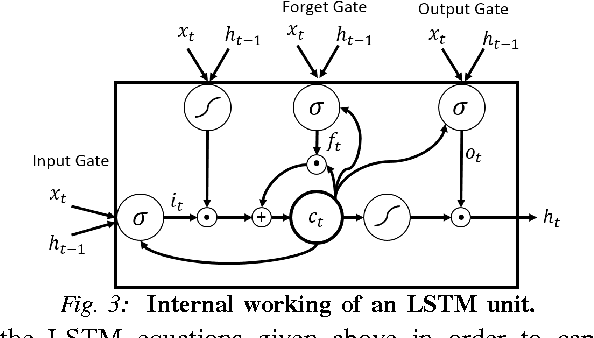
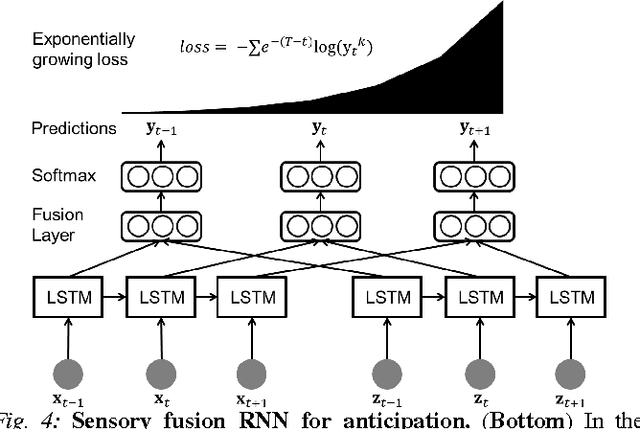
Anticipating the future actions of a human is a widely studied problem in robotics that requires spatio-temporal reasoning. In this work we propose a deep learning approach for anticipation in sensory-rich robotics applications. We introduce a sensory-fusion architecture which jointly learns to anticipate and fuse information from multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We train our architecture in a sequence-to-sequence prediction manner, and it explicitly learns to predict the future given only a partial temporal context. We further introduce a novel loss layer for anticipation which prevents over-fitting and encourages early anticipation. We use our architecture to anticipate driving maneuvers several seconds before they happen on a natural driving data set of 1180 miles. The context for maneuver anticipation comes from multiple sensors installed on the vehicle. Our approach shows significant improvement over the state-of-the-art in maneuver anticipation by increasing the precision from 77.4% to 90.5% and recall from 71.2% to 87.4%.