 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Preferences for Manipulation Tasks from Online Coactive Feedback
Paper and Code
Jan 05, 2016
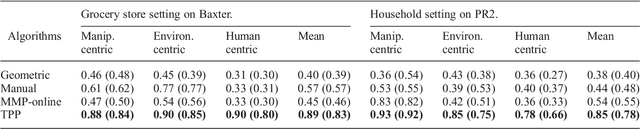

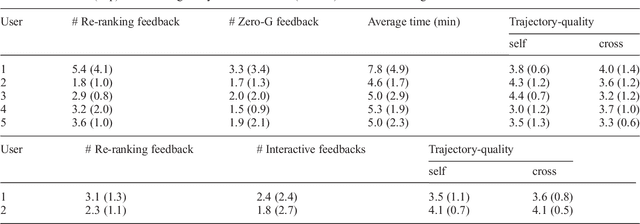
We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than simple geometric constraints on trajectories; they are rather governed by the surrounding context of various objects and human interactions in the environment. We propose a coactive online learning framework for teaching preferences in contextually rich environments. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this coactive preference feedback can be more easily elicited than demonstrations of optimal trajectories. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We implement our algorithm on two high degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings -- household chores and grocery store checkout -- and show that users are able to train the robot with just a few feedbacks (taking only a few minutes).\footnote{Parts of this work has been published at NIPS and ISRR conferences~\citep{Jain13,Jain13b}. This journal submission presents a consistent full paper, and also includes the proof of regret bounds, more details of the robotic system, and a thorough related work.}