 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera
Oct 06, 2019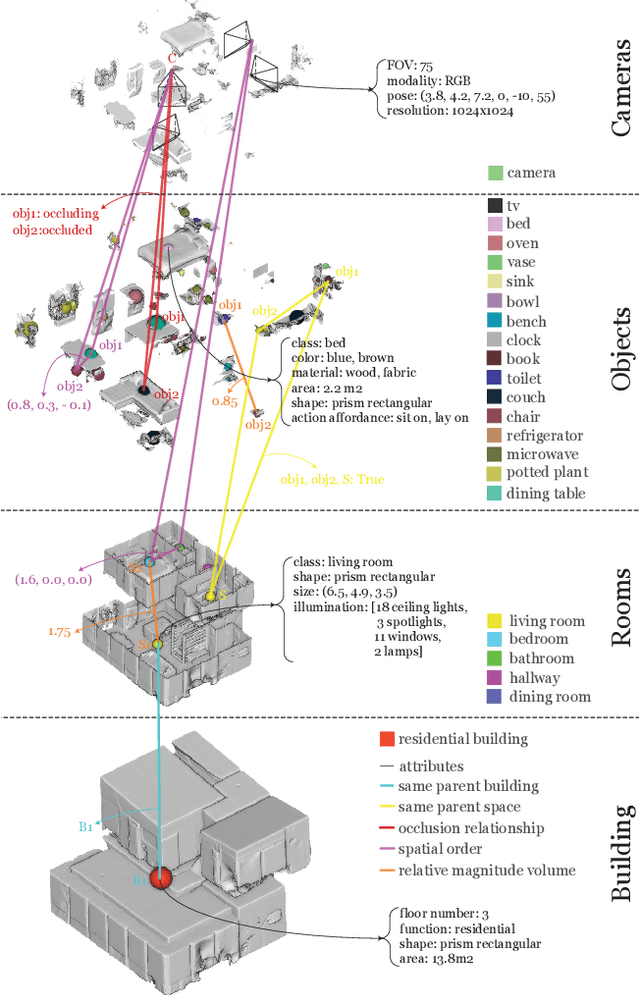

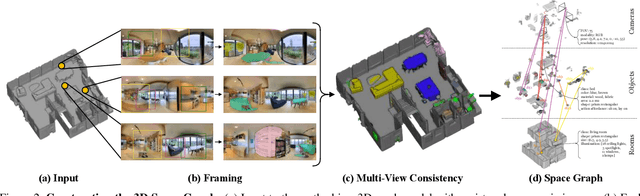
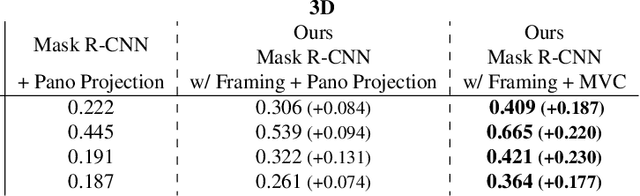
A comprehensive semantic understanding of a scene is important for many applications - but in what space should diverse semantic information (e.g., objects, scene categories, material types, texture, etc.) be grounded and what should be its structure? Aspiring to have one unified structure that hosts diverse types of semantics, we follow the Scene Graph paradigm in 3D, generating a 3D Scene Graph. Given a 3D mesh and registered panoramic images, we construct a graph that spans the entire building and includes semantics on objects (e.g., class, material, and other attributes), rooms (e.g., scene category, volume, etc.) and cameras (e.g., location, etc.), as well as the relationships among these entities. However, this process is prohibitively labor heavy if done manually. To alleviate this we devise a semi-automatic framework that employs existing detection methods and enhances them using two main constraints: I. framing of query images sampled on panoramas to maximize the performance of 2D detectors, and II. multi-view consistency enforcement across 2D detections that originate in different camera locations.
Which Tasks Should Be Learned Together in Multi-task Learning?
May 21, 2019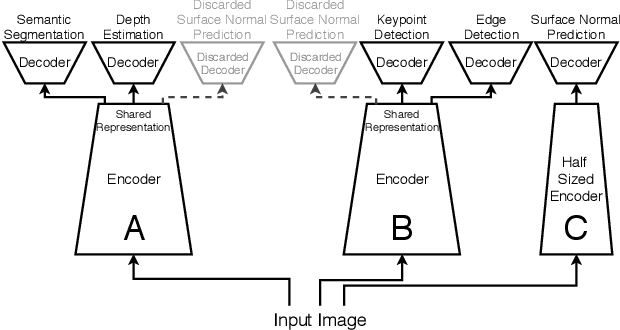
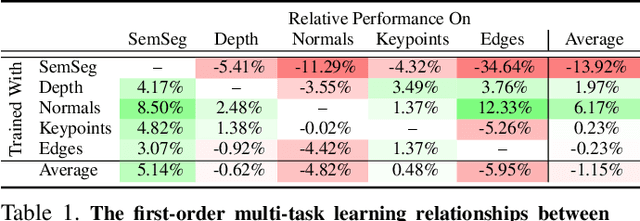
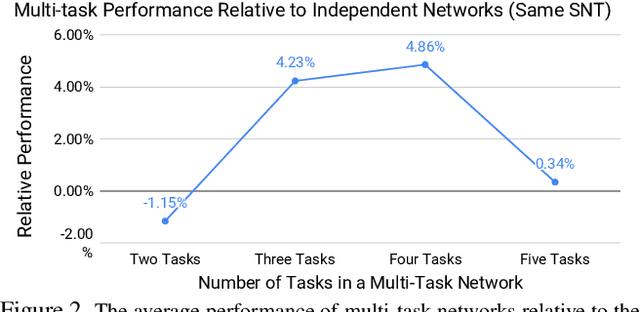

Many computer vision applications require solving multiple tasks in real-time. A neural network can be trained to solve multiple tasks simultaneously using `multi-task learning'. This saves computation at inference time as only a single network needs to be evaluated. Unfortunately, this often leads to inferior overall performance as task objectives compete, which consequently poses the question: which tasks should and should not be learned together in one network when employing multi-task learning? We systematically study task cooperation and competition and propose a framework for assigning tasks to a few neural networks such that cooperating tasks are computed by the same neural network, while competing tasks are computed by different networks. Our framework offers a time-accuracy trade-off and can produce better accuracy using less inference time than not only a single large multi-task neural network but also many single-task networks.
Mid-Level Visual Representations Improve Generalization and Sample Efficiency for Learning Active Tasks
Dec 31, 2018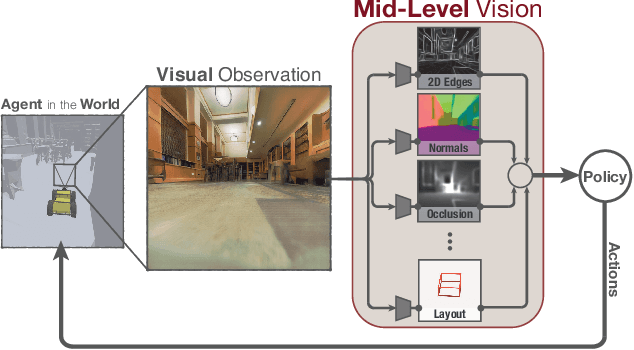
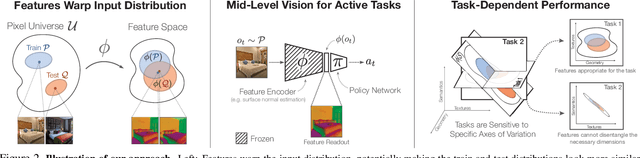
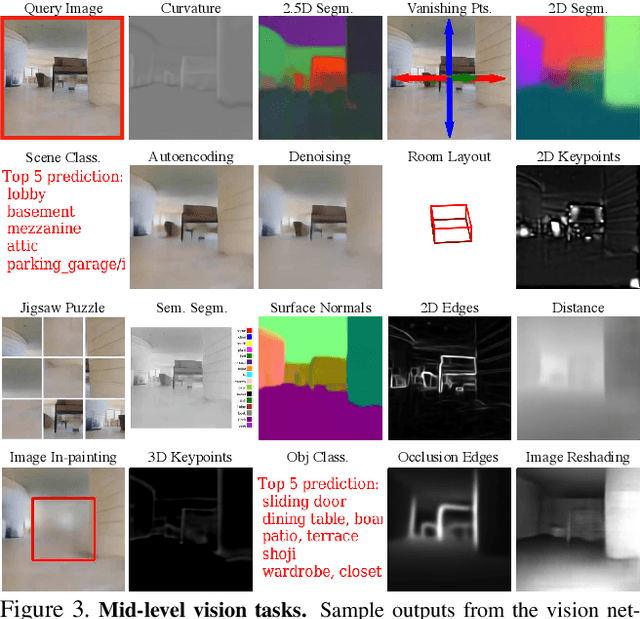
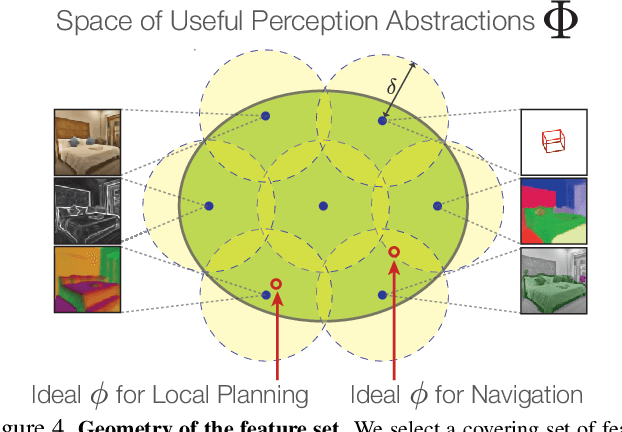
One of the ultimate promises of computer vision is to help robotic agents perform active tasks, like delivering packages or doing household chores. However, the conventional approach to solving "vision" is to define a set of offline recognition problems (e.g. object detection) and solve those first. This approach faces a challenge from the recent rise of Deep Reinforcement Learning frameworks that learn active tasks from scratch using images as input. This poses a set of fundamental questions: what is the role of computer vision if everything can be learned from scratch? Could intermediate vision tasks actually be useful for performing arbitrary downstream active tasks? We show that proper use of mid-level perception confers significant advantages over training from scratch. We implement a perception module as a set of mid-level visual representations and demonstrate that learning active tasks with mid-level features is significantly more sample-efficient than scratch and able to generalize in situations where the from-scratch approach fails. However, we show that realizing these gains requires careful selection of the particular mid-level features for each downstream task. Finally, we put forth a simple and efficient perception module based on the results of our study, which can be adopted as a rather generic perception module for active frameworks.
On Evaluation of Embodied Navigation Agents
Jul 18, 2018Skillful mobile operation in three-dimensional environments is a primary topic of study in Artificial Intelligence. The past two years have seen a surge of creative work on navigation. This creative output has produced a plethora of sometimes incompatible task definitions and evaluation protocols. To coordinate ongoing and future research in this area, we have convened a working group to study empirical methodology in navigation research. The present document summarizes the consensus recommendations of this working group. We discuss different problem statements and the role of generalization, present evaluation measures, and provide standard scenarios that can be used for benchmarking.
Generic 3D Representation via Pose Estimation and Matching
Oct 23, 2017



Though a large body of computer vision research has investigated developing generic semantic representations, efforts towards developing a similar representation for 3D has been limited. In this paper, we learn a generic 3D representation through solving a set of foundational proxy 3D tasks: object-centric camera pose estimation and wide baseline feature matching. Our method is based upon the premise that by providing supervision over a set of carefully selected foundational tasks, generalization to novel tasks and abstraction capabilities can be achieved. We empirically show that the internal representation of a multi-task ConvNet trained to solve the above core problems generalizes to novel 3D tasks (e.g., scene layout estimation, object pose estimation, surface normal estimation) without the need for fine-tuning and shows traits of abstraction abilities (e.g., cross-modality pose estimation). In the context of the core supervised tasks, we demonstrate our representation achieves state-of-the-art wide baseline feature matching results without requiring apriori rectification (unlike SIFT and the majority of learned features). We also show 6DOF camera pose estimation given a pair local image patches. The accuracy of both supervised tasks come comparable to humans. Finally, we contribute a large-scale dataset composed of object-centric street view scenes along with point correspondences and camera pose information, and conclude with a discussion on the learned representation and open research questions.
* Published in ECCV16. See the project website http://3drepresentation.stanford.edu/ and dataset website https://github.com/amir32002/3D_Street_View
Feedback Networks
Aug 20, 2017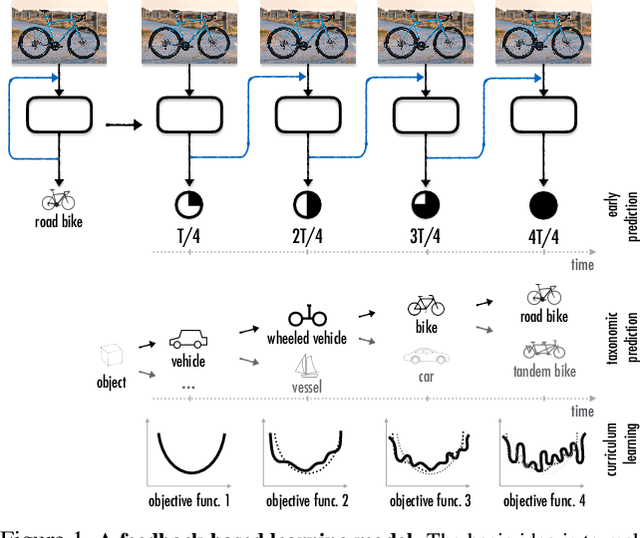
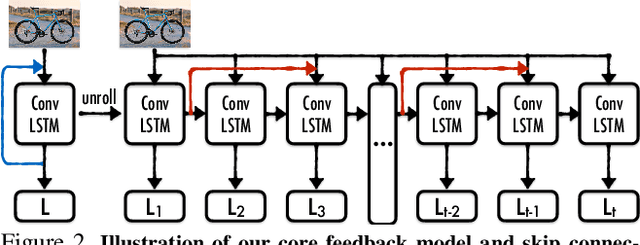
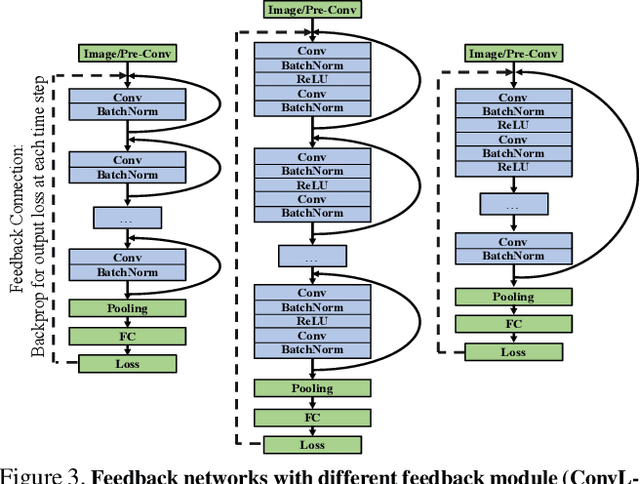
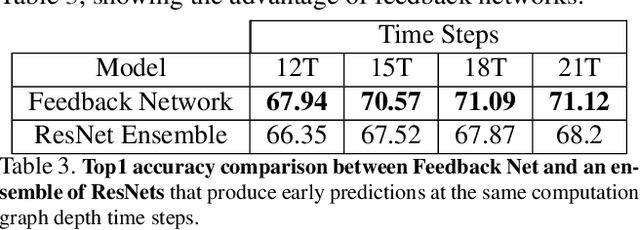
Currently, the most successful learning models in computer vision are based on learning successive representations followed by a decision layer. This is usually actualized through feedforward multilayer neural networks, e.g. ConvNets, where each layer forms one of such successive representations. However, an alternative that can achieve the same goal is a feedback based approach in which the representation is formed in an iterative manner based on a feedback received from previous iteration's output. We establish that a feedback based approach has several fundamental advantages over feedforward: it enables making early predictions at the query time, its output naturally conforms to a hierarchical structure in the label space (e.g. a taxonomy), and it provides a new basis for Curriculum Learning. We observe that feedback networks develop a considerably different representation compared to feedforward counterparts, in line with the aforementioned advantages. We put forth a general feedback based learning architecture with the endpoint results on par or better than existing feedforward networks with the addition of the above advantages. We also investigate several mechanisms in feedback architectures (e.g. skip connections in time) and design choices (e.g. feedback length). We hope this study offers new perspectives in quest for more natural and practical learning models.
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Apr 06, 2017
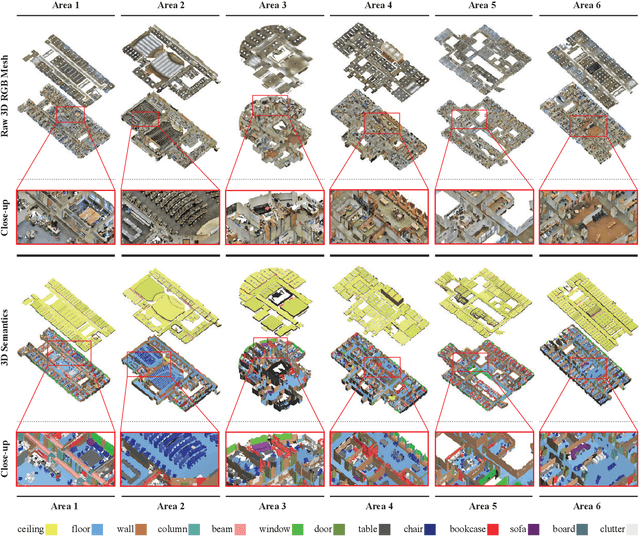
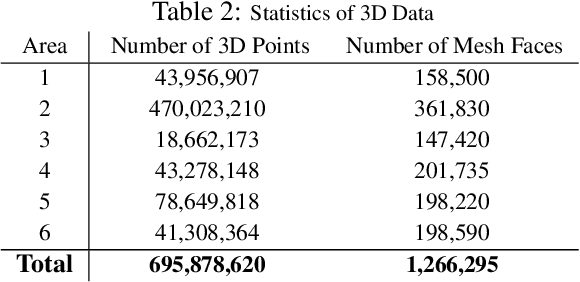
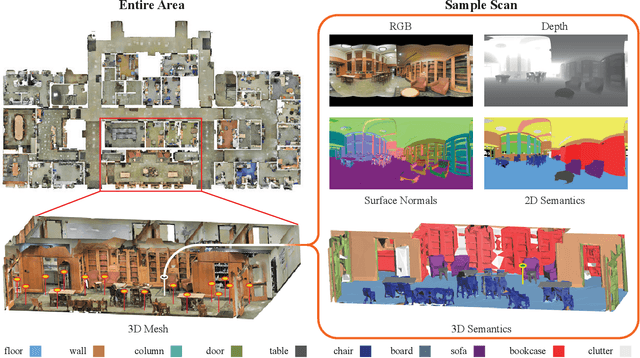
We present a dataset of large-scale indoor spaces that provides a variety of mutually registered modalities from 2D, 2.5D and 3D domains, with instance-level semantic and geometric annotations. The dataset covers over 6,000m2 and contains over 70,000 RGB images, along with the corresponding depths, surface normals, semantic annotations, global XYZ images (all in forms of both regular and 360{\deg} equirectangular images) as well as camera information. It also includes registered raw and semantically annotated 3D meshes and point clouds. The dataset enables development of joint and cross-modal learning models and potentially unsupervised approaches utilizing the regularities present in large-scale indoor spaces. The dataset is available here: http://3Dsemantics.stanford.edu/
The THUMOS Challenge on Action Recognition for Videos "in the Wild"
Apr 21, 2016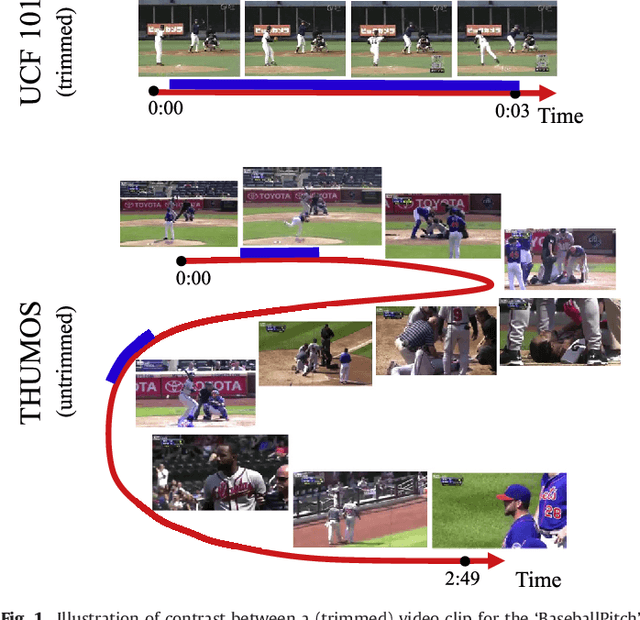
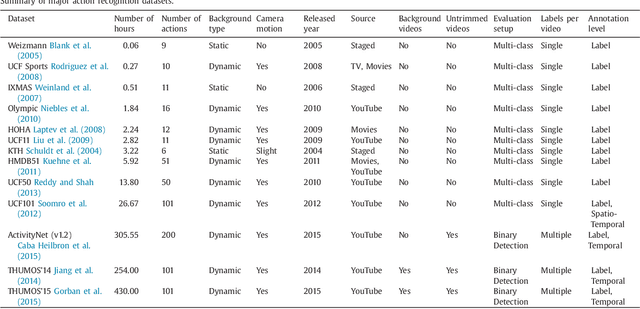
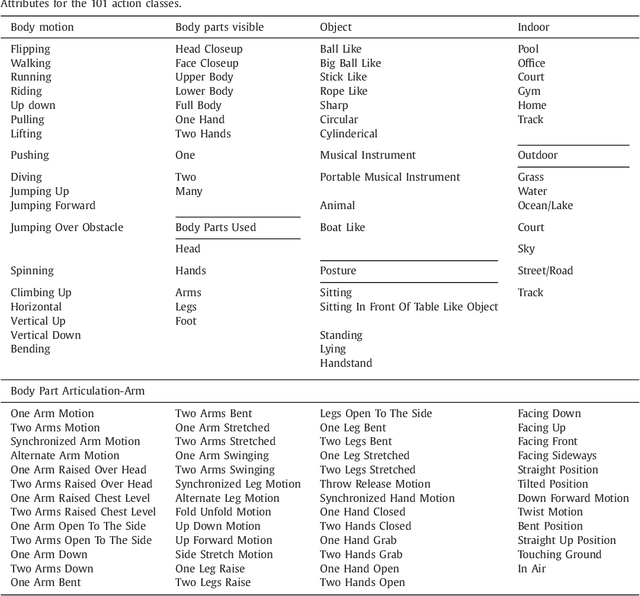
Automatically recognizing and localizing wide ranges of human actions has crucial importance for video understanding. Towards this goal, the THUMOS challenge was introduced in 2013 to serve as a benchmark for action recognition. Until then, video action recognition, including THUMOS challenge, had focused primarily on the classification of pre-segmented (i.e., trimmed) videos, which is an artificial task. In THUMOS 2014, we elevated action recognition to a more practical level by introducing temporally untrimmed videos. These also include `background videos' which share similar scenes and backgrounds as action videos, but are devoid of the specific actions. The three editions of the challenge organized in 2013--2015 have made THUMOS a common benchmark for action classification and detection and the annual challenge is widely attended by teams from around the world. In this paper we describe the THUMOS benchmark in detail and give an overview of data collection and annotation procedures. We present the evaluation protocols used to quantify results in the two THUMOS tasks of action classification and temporal detection. We also present results of submissions to the THUMOS 2015 challenge and review the participating approaches. Additionally, we include a comprehensive empirical study evaluating the differences in action recognition between trimmed and untrimmed videos, and how well methods trained on trimmed videos generalize to untrimmed videos. We conclude by proposing several directions and improvements for future THUMOS challenges.
Structural-RNN: Deep Learning on Spatio-Temporal Graphs
Apr 11, 2016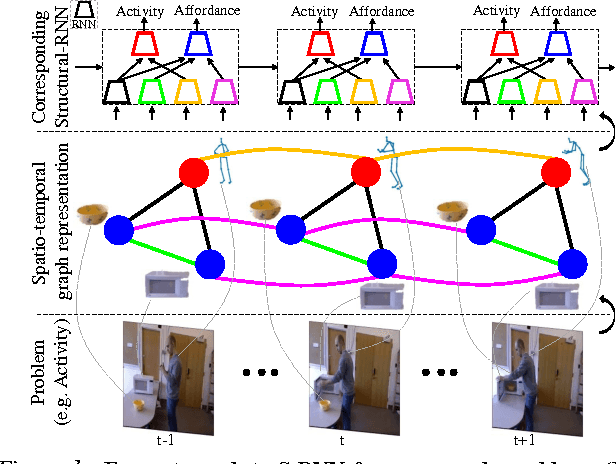
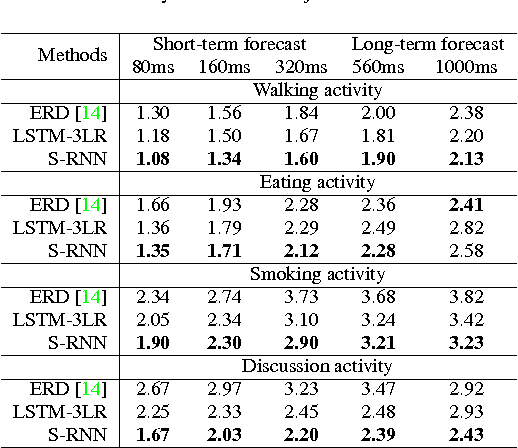
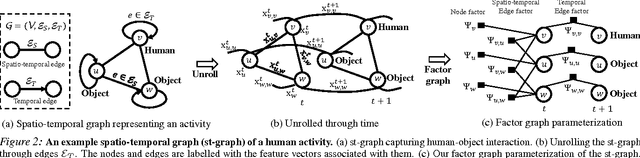
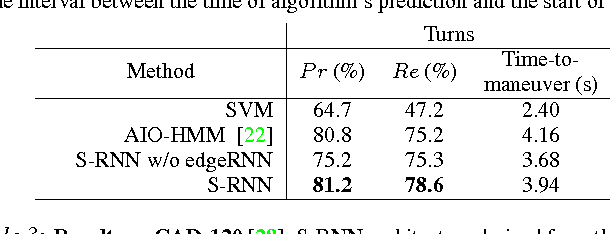
Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks~(RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower new approaches to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks.