 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMAGE: Detecting Adversarially Modified AI Generated Text
Jan 06, 2025AI humanizers are a new class of online software tools meant to paraphrase and rewrite AI-generated text in a way that allows them to evade AI detection software. We study 19 AI humanizer and paraphrasing tools and qualitatively assess their effects and faithfulness in preserving the meaning of the original text. We show that many existing AI detectors fail to detect humanized text. Finally, we demonstrate a robust model that can detect humanized AI text while maintaining a low false positive rate using a data-centric augmentation approach. We attack our own detector, training our own fine-tuned model optimized against our detector's predictions, and show that our detector's cross-humanizer generalization is sufficient to remain robust to this attack.
Technical Report on the Checkfor.ai AI-Generated Text Classifier
Feb 26, 2024



We present the CheckforAI text classifier, a transformer-based neural network trained to distinguish text written by large language models from text written by humans. CheckforAI outperforms zero-shot methods such as DetectGPT as well as leading commercial AI detection tools with over 9 times lower error rates on a comprehensive benchmark comprised of ten text domains (student writing, creative writing, scientific writing, books, encyclopedias, news, email, scientific papers, short-form Q&A) and 8 open- and closed-source large language models. We propose a training algorithm, hard negative mining with synthetic mirrors, that enables our classifier to achieve orders of magnitude lower false positive rates on high-data domains such as reviews. Finally, we show that CheckforAI is not biased against nonnative English speakers and generalizes to domains and models unseen during training.
Learning to Navigate Using Mid-Level Visual Priors
Dec 23, 2019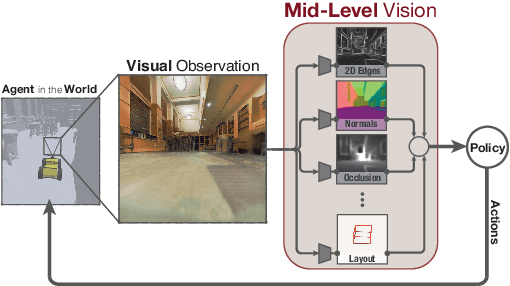
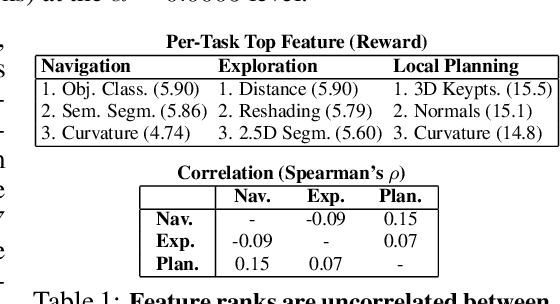

How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. navigating a complex environment)? What are the consequences of not utilizing such visual priors in learning? We study these questions by integrating a generic perceptual skill set (a distance estimator, an edge detector, etc.) within a reinforcement learning framework (see Fig. 1). This skill set ("mid-level vision") provides the policy with a more processed state of the world compared to raw images. Our large-scale study demonstrates that using mid-level vision results in policies that learn faster, generalize better, and achieve higher final performance, when compared to learning from scratch and/or using state-of-the-art visual and non-visual representation learning methods. We show that conventional computer vision objectives are particularly effective in this regard and can be conveniently integrated into reinforcement learning frameworks. Finally, we found that no single visual representation was universally useful for all downstream tasks, hence we computationally derive a task-agnostic set of representations optimized to support arbitrary downstream tasks.
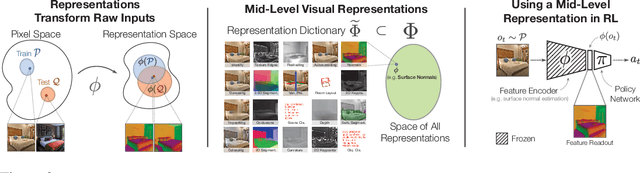
Mid-Level Visual Representations Improve Generalization and Sample Efficiency for Learning Active Tasks
Dec 31, 2018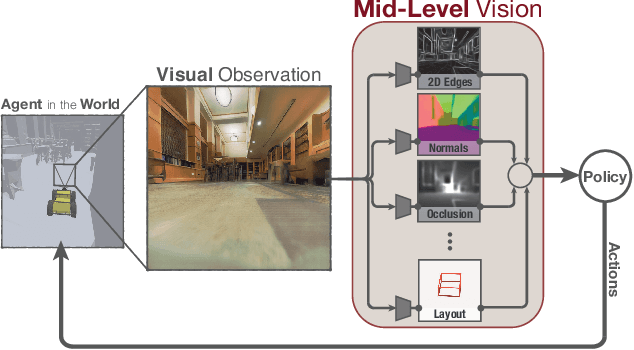
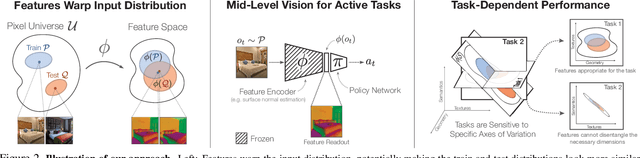
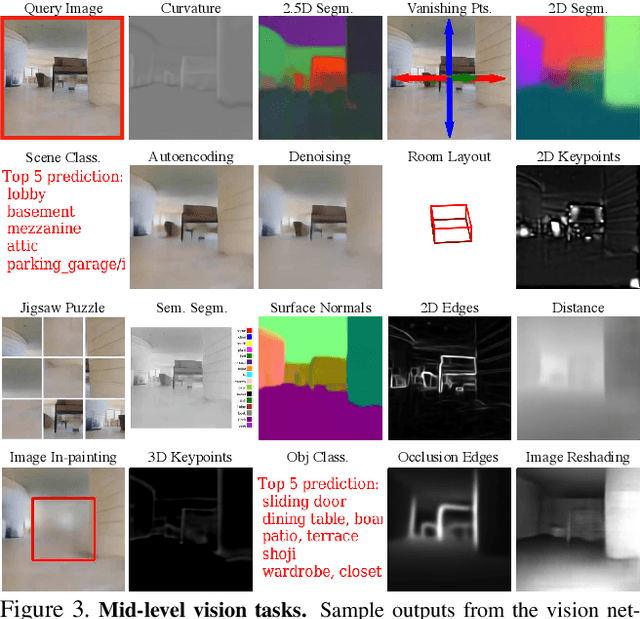
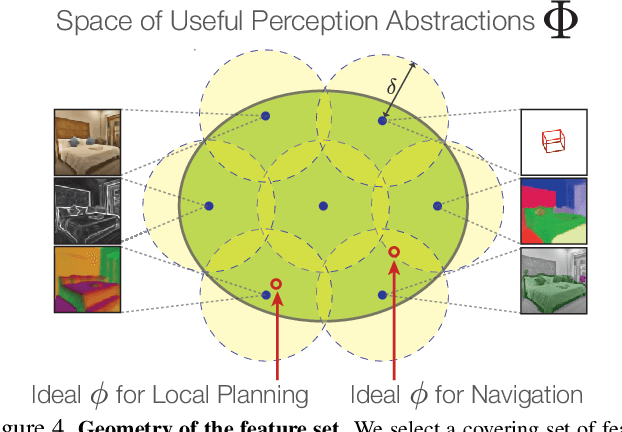
One of the ultimate promises of computer vision is to help robotic agents perform active tasks, like delivering packages or doing household chores. However, the conventional approach to solving "vision" is to define a set of offline recognition problems (e.g. object detection) and solve those first. This approach faces a challenge from the recent rise of Deep Reinforcement Learning frameworks that learn active tasks from scratch using images as input. This poses a set of fundamental questions: what is the role of computer vision if everything can be learned from scratch? Could intermediate vision tasks actually be useful for performing arbitrary downstream active tasks? We show that proper use of mid-level perception confers significant advantages over training from scratch. We implement a perception module as a set of mid-level visual representations and demonstrate that learning active tasks with mid-level features is significantly more sample-efficient than scratch and able to generalize in situations where the from-scratch approach fails. However, we show that realizing these gains requires careful selection of the particular mid-level features for each downstream task. Finally, we put forth a simple and efficient perception module based on the results of our study, which can be adopted as a rather generic perception module for active frameworks.