 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture
Jan 05, 2016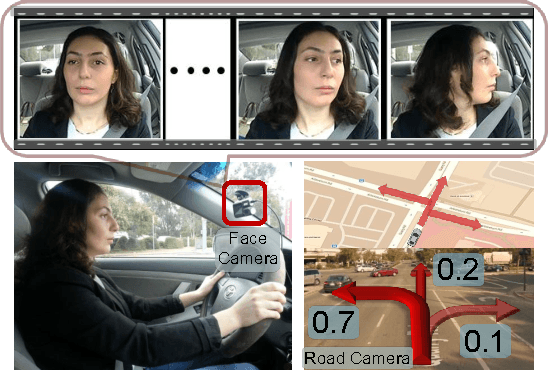

Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. In this work we propose a vehicular sensor-rich platform and learning algorithms for maneuver anticipation. For this purpose we equip a car with cameras, Global Positioning System (GPS), and a computing device to capture the driving context from both inside and outside of the car. In order to anticipate maneuvers, we propose a sensory-fusion deep learning architecture which jointly learns to anticipate and fuse multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We propose a novel training procedure which allows the network to predict the future given only a partial temporal context. We introduce a diverse data set with 1180 miles of natural freeway and city driving, and show that we can anticipate maneuvers 3.5 seconds before they occur in real-time with a precision and recall of 90.5\% and 87.4\% respectively.
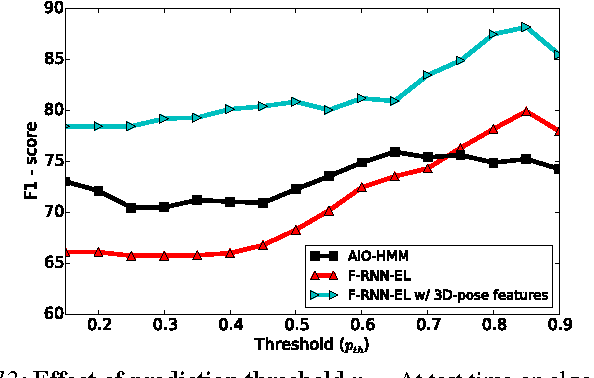
Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models
Sep 19, 2015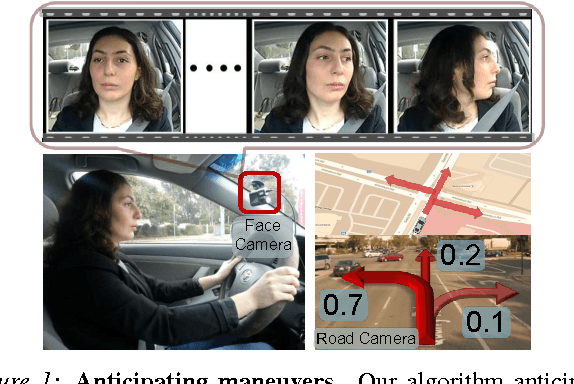
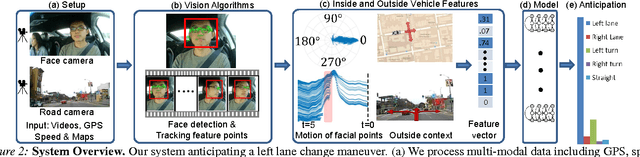
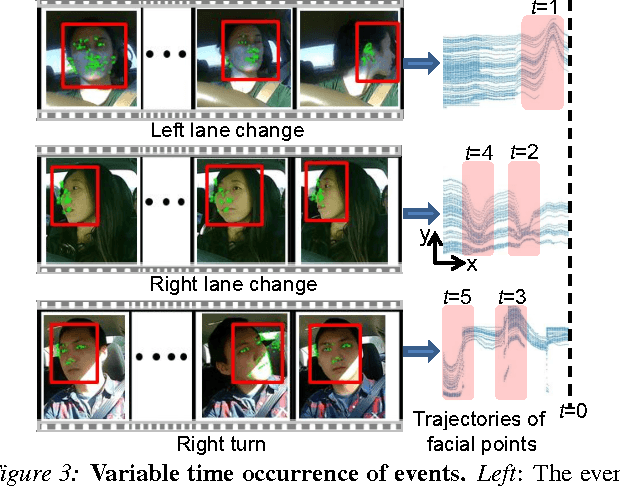
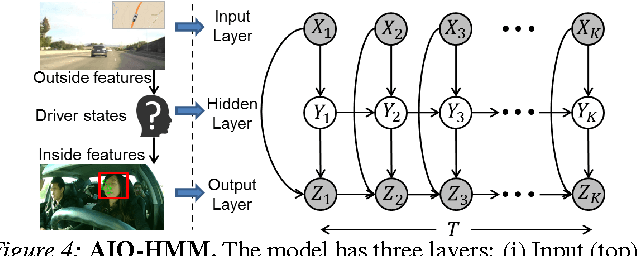
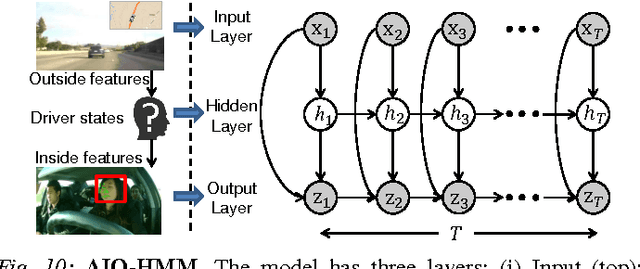
Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. In this work we anticipate driving maneuvers a few seconds before they occur. For this purpose we equip a car with cameras and a computing device to capture the driving context from both inside and outside of the car. We propose an Autoregressive Input-Output HMM to model the contextual information alongwith the maneuvers. We evaluate our approach on a diverse data set with 1180 miles of natural freeway and city driving and show that we can anticipate maneuvers 3.5 seconds before they occur with over 80\% F1-score in real-time.