 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Real Numbers for AI: a case-study using a RISC-V CPU
Sep 11, 2023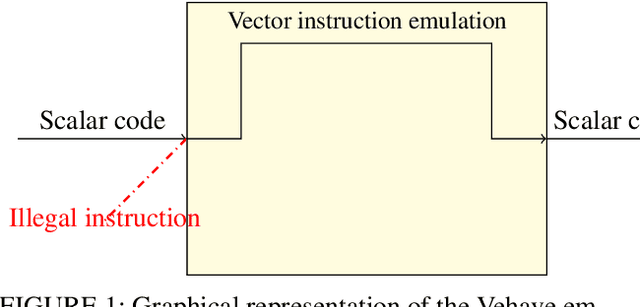
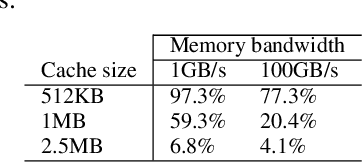

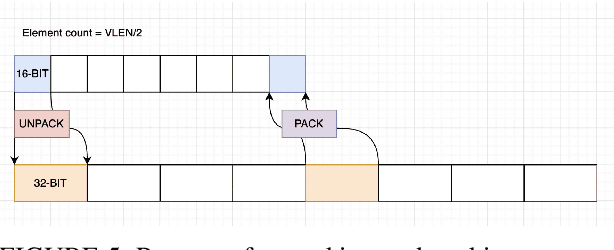
As recently demonstrated, Deep Neural Networks (DNN), usually trained using single precision IEEE 754 floating point numbers (binary32), can also work using lower precision. Therefore, 16-bit and 8-bit compressed format have attracted considerable attention. In this paper, we focused on two families of formats that have already achieved interesting results in compressing binary32 numbers in machine learning applications, without sensible degradation of the accuracy: bfloat and posit. Even if 16-bit and 8-bit bfloat/posit are routinely used for reducing the storage of the weights/biases of trained DNNs, the inference still often happens on the 32-bit FPU of the CPU (especially if GPUs are not available). In this paper we propose a way to decompress a tensor of bfloat/posits just before computations, i.e., after the compressed operands have been loaded within the vector registers of a vector capable CPU, in order to save bandwidth usage and increase cache efficiency. Finally, we show the architectural parameters and considerations under which this solution is advantageous with respect to the uncompressed one.
VALUE: Large Scale Voting-based Automatic Labelling for Urban Environments
Jun 05, 2020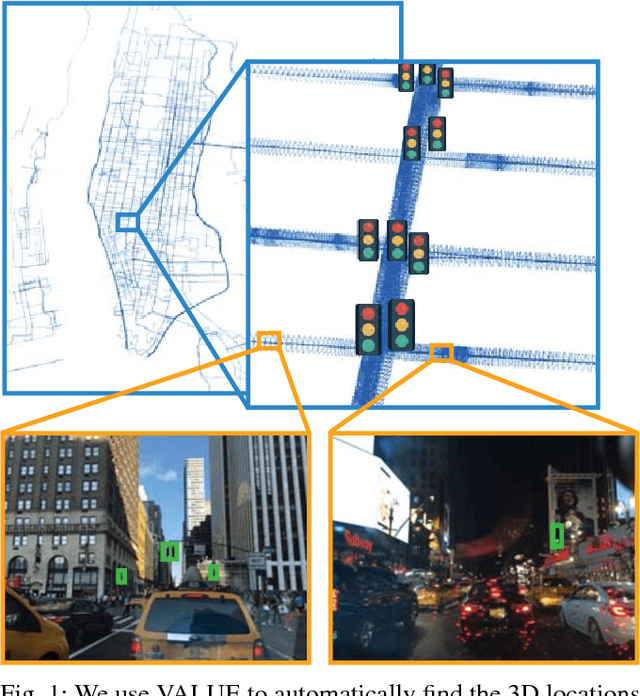
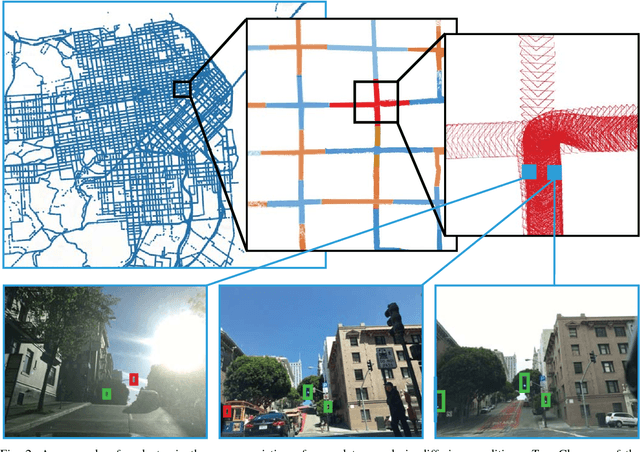
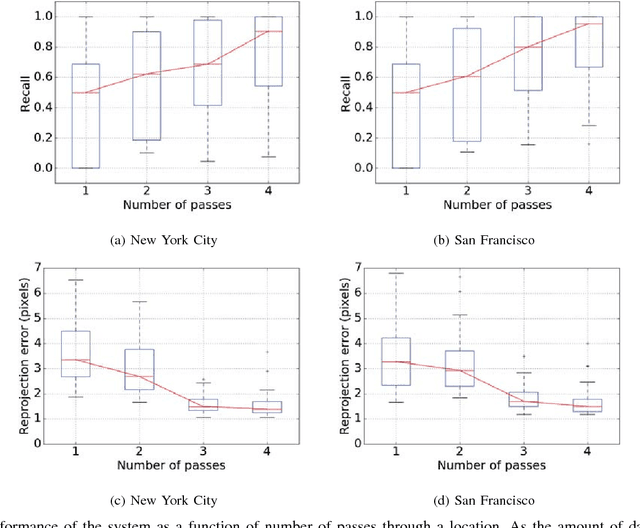

This paper presents a simple and robust method for the automatic localisation of static 3D objects in large-scale urban environments. By exploiting the potential to merge a large volume of noisy but accurately localised 2D image data, we achieve superior performance in terms of both robustness and accuracy of the recovered 3D information. The method is based on a simple distributed voting schema which can be fully distributed and parallelised to scale to large-scale scenarios. To evaluate the method we collected city-scale data sets from New York City and San Francisco consisting of almost 400k images spanning the area of 40 km$^2$ and used it to accurately recover the 3D positions of traffic lights. We demonstrate a robust performance and also show that the solution improves in quality over time as the amount of data increases.
Robust and Subject-Independent Driving Manoeuvre Anticipation through Domain-Adversarial Recurrent Neural Networks
Feb 26, 2019



Through deep learning and computer vision techniques, driving manoeuvres can be predicted accurately a few seconds in advance. Even though adapting a learned model to new drivers and different vehicles is key for robust driver-assistance systems, this problem has received little attention so far. This work proposes to tackle this challenge through domain adaptation, a technique closely related to transfer learning. A proof of concept for the application of a Domain-Adversarial Recurrent Neural Network (DA-RNN) to multi-modal time series driving data is presented, in which domain-invariant features are learned by maximizing the loss of an auxiliary domain classifier. Our implementation is evaluated using a leave-one-driver-out approach on individual drivers from the Brain4Cars dataset, as well as using a new dataset acquired through driving simulations, yielding an average increase in performance of 30% and 114% respectively compared to no adaptation. We also show the importance of fine-tuning sections of the network to optimise the extraction of domain-independent features. The results demonstrate the applicability of the approach to driver-assistance systems as well as training and simulation environments.
* 40 pages, 4 figures. Published online in Robotics and Autonomous Systems