 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Decentralized Routing Policies via Graph Attention-based Multi-Agent Reinforcement Learning in Lunar Delay-Tolerant Networks
Oct 23, 2025We present a fully decentralized routing framework for multi-robot exploration missions operating under the constraints of a Lunar Delay-Tolerant Network (LDTN). In this setting, autonomous rovers must relay collected data to a lander under intermittent connectivity and unknown mobility patterns. We formulate the problem as a Partially Observable Markov Decision Problem (POMDP) and propose a Graph Attention-based Multi-Agent Reinforcement Learning (GAT-MARL) policy that performs Centralized Training, Decentralized Execution (CTDE). Our method relies only on local observations and does not require global topology updates or packet replication, unlike classical approaches such as shortest path and controlled flooding-based algorithms. Through Monte Carlo simulations in randomized exploration environments, GAT-MARL provides higher delivery rates, no duplications, and fewer packet losses, and is able to leverage short-term mobility forecasts; offering a scalable solution for future space robotic systems for planetary exploration, as demonstrated by successful generalization to larger rover teams.
Microscaling Floating Point Formats for Large Language Models
Oct 02, 2025The increasing computational and memory demands of large language models (LLMs) necessitate innovative approaches to optimize resource usage without compromising performance. This paper leverages microscaling floating-point formats, a novel technique designed to address these challenges by reducing the storage and computational overhead associated with numerical representations in LLMs. Unlike traditional floating-point representations that allocate a dedicated scale for each value, microscaling employs a shared scale across a block of values, enabling compact one-byte floating-point representations while maintaining an extended dynamic range. We explore the application of microscaling in the context of 8-bit floating-point formats to significantly reduce memory footprint and computational costs. We tested several configurations of microscaling floats within the GPT-2 LLM architecture, demonstrating that microscaling data formats can achieve competitive accuracy during training and inference, proving its efficacy as a resource-efficient alternative for deploying LLMs at scale. The source code is publicly available at: https://github.com/unipi-dii-compressedarith/llm.c-sve
Planning, scheduling, and execution on the Moon: the CADRE technology demonstration mission
Feb 20, 2025NASA's Cooperative Autonomous Distributed Robotic Exploration (CADRE) mission, slated for flight to the Moon's Reiner Gamma region in 2025/2026, is designed to demonstrate multi-agent autonomous exploration of the Lunar surface and sub-surface. A team of three robots and a base station will autonomously explore a region near the lander, collecting the data required for 3D reconstruction of the surface with no human input; and then autonomously perform distributed sensing with multi-static ground penetrating radars (GPR), driving in formation while performing coordinated radar soundings to create a map of the subsurface. At the core of CADRE's software architecture is a novel autonomous, distributed planning, scheduling, and execution (PS&E) system. The system coordinates the robots' activities, planning and executing tasks that require multiple robots' participation while ensuring that each individual robot's thermal and power resources stay within prescribed bounds, and respecting ground-prescribed sleep-wake cycles. The system uses a centralized-planning, distributed-execution paradigm, and a leader election mechanism ensures robustness to failures of individual agents. In this paper, we describe the architecture of CADRE's PS&E system; discuss its design rationale; and report on verification and validation (V&V) testing of the system on CADRE's hardware in preparation for deployment on the Moon.
Stochastic Guidance of Buoyancy Controlled Vehicles under Ice Shelves using Ocean Currents
Jun 10, 2024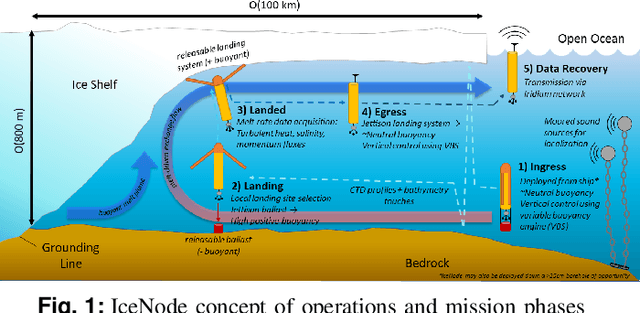

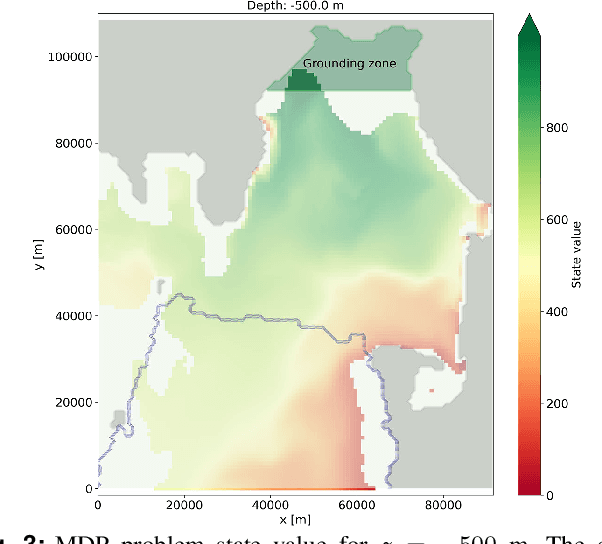
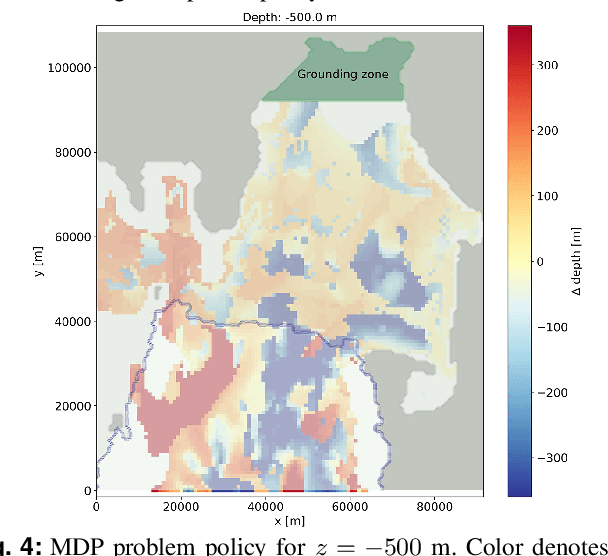
We propose a novel technique for guidance of buoyancy-controlled vehicles in uncertain under-ice ocean flows. In-situ melt rate measurements collected at the grounding zone of Antarctic ice shelves, where the ice shelf meets the underlying bedrock, are essential to constrain models of future sea level rise. Buoyancy-controlled vehicles, which control their vertical position in the water column through internal actuation but have no means of horizontal propulsion, offer an affordable and reliable platform for such in-situ data collection. However, reaching the grounding zone requires vehicles to traverse tens of kilometers under the ice shelf, with approximate position knowledge and no means of communication, in highly variable and uncertain ocean currents. To address this challenge, we propose a partially observable MDP approach that exploits model-based knowledge of the under-ice currents and, critically, of their uncertainty, to synthesize effective guidance policies. The approach uses approximate dynamic programming to model uncertainty in the currents, and QMDP to address localization uncertainty. Numerical experiments show that the policy can deliver up to 88.8% of underwater vehicles to the grounding zone -- a 33% improvement compared to state-of-the-art guidance techniques, and a 262% improvement over uncontrolled drifters. Collectively, these results show that model-based under-ice guidance is a highly promising technique for exploration of under-ice cavities, and has the potential to enable cost-effective and scalable access to these challenging and rarely observed environments.
Sound Heuristic Search Value Iteration for Undiscounted POMDPs with Reachability Objectives
Jun 05, 2024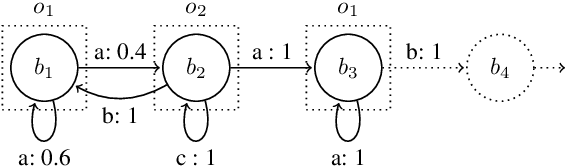
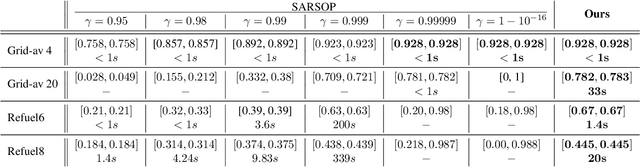
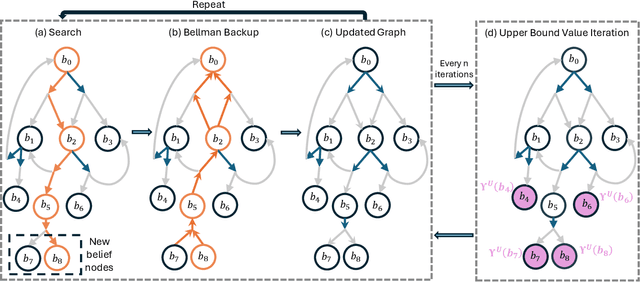
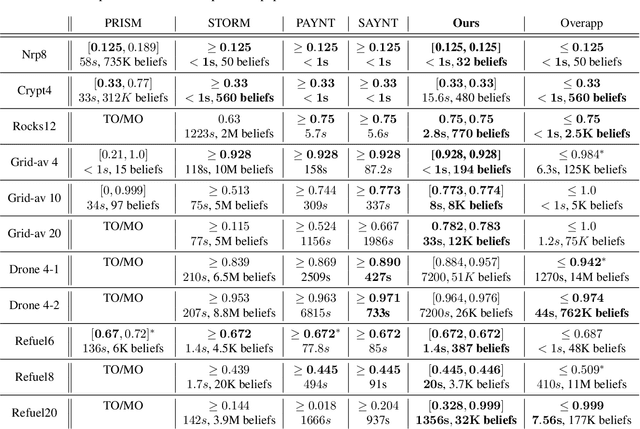
Partially Observable Markov Decision Processes (POMDPs) are powerful models for sequential decision making under transition and observation uncertainties. This paper studies the challenging yet important problem in POMDPs known as the (indefinite-horizon) Maximal Reachability Probability Problem (MRPP), where the goal is to maximize the probability of reaching some target states. This is also a core problem in model checking with logical specifications and is naturally undiscounted (discount factor is one). Inspired by the success of point-based methods developed for discounted problems, we study their extensions to MRPP. Specifically, we focus on trial-based heuristic search value iteration techniques and present a novel algorithm that leverages the strengths of these techniques for efficient exploration of the belief space (informed search via value bounds) while addressing their drawbacks in handling loops for indefinite-horizon problems. The algorithm produces policies with two-sided bounds on optimal reachability probabilities. We prove convergence to an optimal policy from below under certain conditions. Experimental evaluations on a suite of benchmarks show that our algorithm outperforms existing methods in almost all cases in both probability guarantees and computation time.
Recursively-Constrained Partially Observable Markov Decision Processes
Oct 15, 2023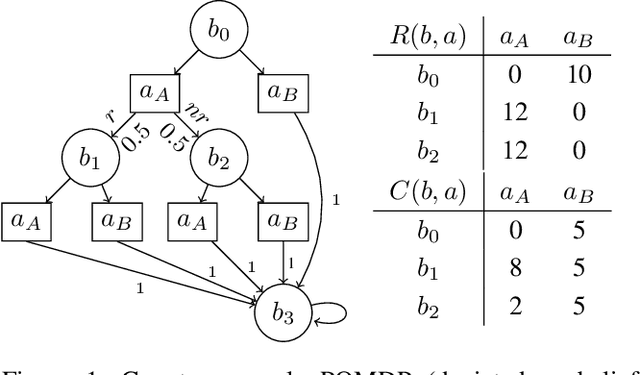
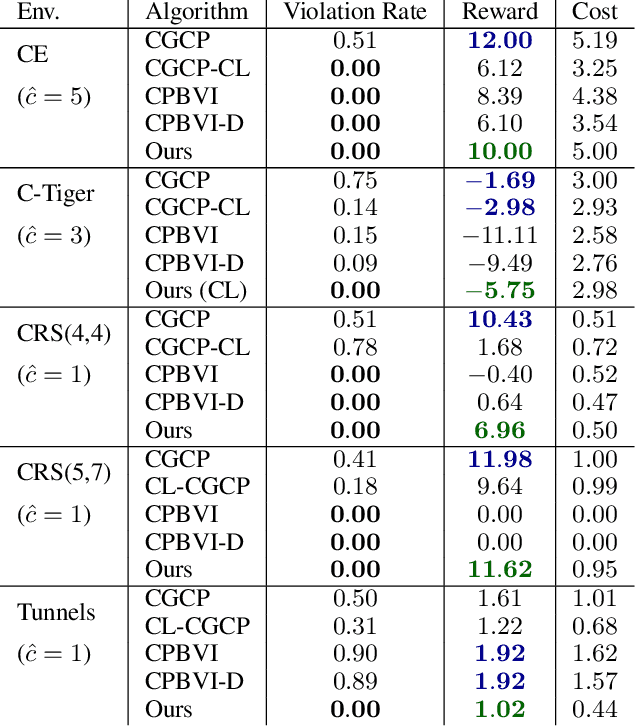
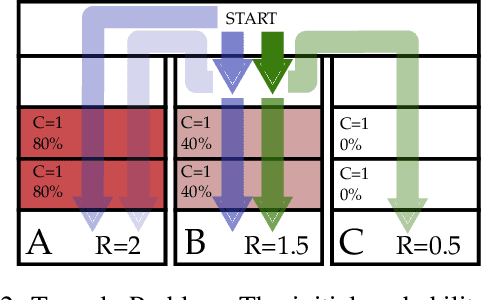
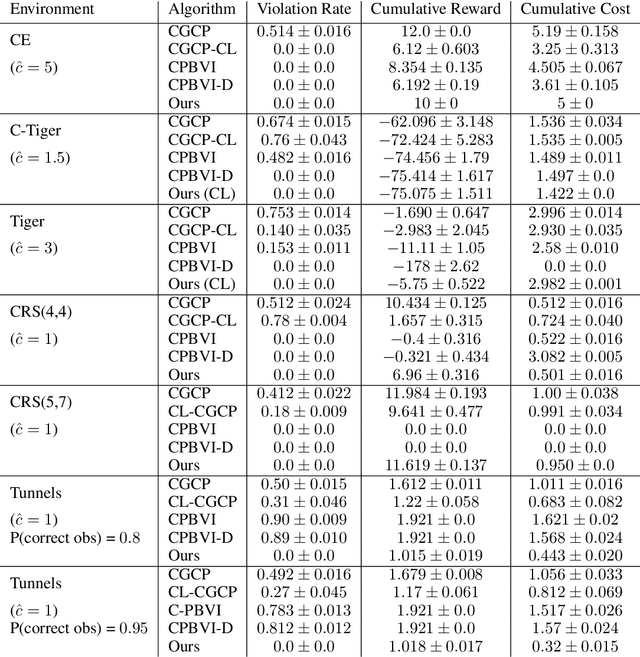
In many problems, it is desirable to optimize an objective function while imposing constraints on some other aspect of the problem. A Constrained Partially Observable Markov Decision Process (C-POMDP) allows modelling of such problems while subject to transition uncertainty and partial observability. Typically, the constraints in C-POMDPs enforce a threshold on expected cumulative costs starting from an initial state distribution. In this work, we first show that optimal C-POMDP policies may violate Bellman's principle of optimality and thus may exhibit pathological behaviors, which can be undesirable for many applications. To address this drawback, we introduce a new formulation, the Recursively-Constrained POMDP (RC-POMDP), that imposes additional history dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies, and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm that synthesizes optimal policies for RC-POMDPs. In our evaluations, we show that policies for RC-POMDPs produce more desirable behavior than policies for C-POMDPs and demonstrate the efficacy of our algorithm across a set of benchmark problems.
Compressed Real Numbers for AI: a case-study using a RISC-V CPU
Sep 11, 2023
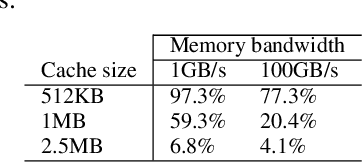

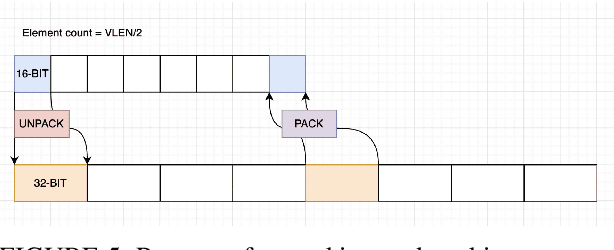
As recently demonstrated, Deep Neural Networks (DNN), usually trained using single precision IEEE 754 floating point numbers (binary32), can also work using lower precision. Therefore, 16-bit and 8-bit compressed format have attracted considerable attention. In this paper, we focused on two families of formats that have already achieved interesting results in compressing binary32 numbers in machine learning applications, without sensible degradation of the accuracy: bfloat and posit. Even if 16-bit and 8-bit bfloat/posit are routinely used for reducing the storage of the weights/biases of trained DNNs, the inference still often happens on the 32-bit FPU of the CPU (especially if GPUs are not available). In this paper we propose a way to decompress a tensor of bfloat/posits just before computations, i.e., after the compressed operands have been loaded within the vector registers of a vector capable CPU, in order to save bandwidth usage and increase cache efficiency. Finally, we show the architectural parameters and considerations under which this solution is advantageous with respect to the uncompressed one.
Optimizing pre-scheduled, intermittently-observed MDPs
May 16, 2023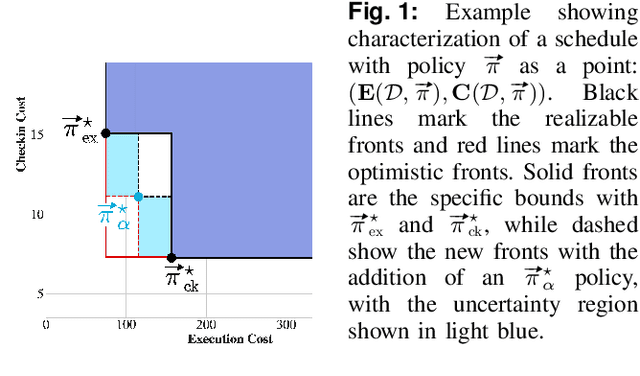
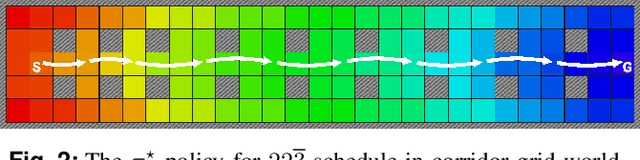
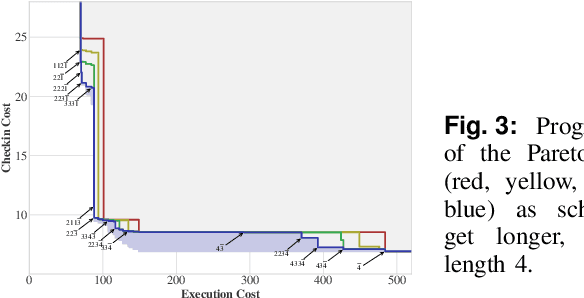

A challenging category of robotics problems arises when sensing incurs substantial costs. This paper examines settings in which a robot wishes to limit its observations of state, for instance, motivated by specific considerations of energy management, stealth, or implicit coordination. We formulate the problem of planning under uncertainty when the robot's observations are intermittent but their timing is known via a pre-declared schedule. After having established the appropriate notion of an optimal policy for such settings, we tackle the problem of joint optimization of the cumulative execution cost and the number of state observations, both in expectation under discounts. To approach this multi-objective optimization problem, we introduce an algorithm that can identify the Pareto front for a class of schedules that are advantageous in the discounted setting. The algorithm proceeds in an accumulative fashion, prepending additions to a working set of schedules and then computing incremental changes to the value functions. Because full exhaustive construction becomes computationally prohibitive for moderate-sized problems, we propose a filtering approach to prune the working set. Empirical results demonstrate that this filtering is effective at reducing computation while incurring only negligible reduction in quality. In summarizing our findings, we provide some characterization of the run-time vs quality trade-off involved.
Proximal Exploration of Venus Volcanism with Teams of Autonomous Buoyancy-Controlled Balloons
Mar 03, 2023

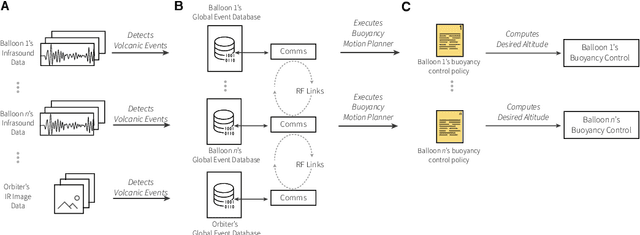

Altitude-controlled balloons hold great promise for performing high-priority scientific investigations of Venus's atmosphere and geological phenomena, including tectonic and volcanic activity, as demonstrated by a number of recent Earth-based experiments. In this paper, we explore a concept of operations where multiple autonomous, altitude-controlled balloons monitor explosive volcanic activity on Venus through infrasound microbarometers, and autonomously navigate the uncertain wind field to perform follow-on observations of detected events of interest. We propose a novel autonomous guidance technique for altitude-controlled balloons in Venus's uncertain wind field, and show the approach can result in an increase of up to 63% in the number of close-up observations of volcanic events compared to passive drifters, and a 16% increase compared to ground-in-the-loop guidance. The results are robust to uncertainty in the wind field, and hold across large changes in the frequency of explosive volcanic events, sensitivity of the microbarometer detectors, and numbers of aerial platforms.
Planning under periodic observations: bounds and bounding-based solutions
Aug 05, 2022We study planning problems faced by robots operating in uncertain environments with incomplete knowledge of state, and actions that are noisy and/or imprecise. This paper identifies a new problem sub-class that models settings in which information is revealed only intermittently through some exogenous process that provides state information periodically. Several practical domains fit this model, including the specific scenario that motivates our research: autonomous navigation of a planetary exploration rover augmented by remote imaging. With an eye to efficient specialized solution methods, we examine the structure of instances of this sub-class. They lead to Markov Decision Processes with exponentially large action-spaces but for which, as those actions comprise sequences of more atomic elements, one may establish performance bounds by comparing policies under different information assumptions. This provides a way in which to construct performance bounds systematically. Such bounds are useful because, in conjunction with the insights they confer, they can be employed in bounding-based methods to obtain high-quality solutions efficiently; the empirical results we present demonstrate their effectiveness for the considered problems. The foregoing has also alluded to the distinctive role that time plays for these problems -- more specifically: time until information is revealed -- and we uncover and discuss several interesting subtleties in this regard.