 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairedGTA: Generating Driving Datasets for Controlled Photometric Shift Analysis
May 31, 2026Evaluating the performance of visual perception systems for autonomous driving is essential to ensure reliable operation across diverse environmental scenarios. Ideally, a balanced and fair analysis across different adverse conditions would require perfectly paired images of the same scene under different weather or illumination changes. This would allow evaluating the effect of photometric shifts independently of geometry and semantic changes. Unfortunately, real-world datasets rarely provide images of the same scene under different environmental conditions, because, normally, camera pose, traffic, and locations of dynamic objects (vehicles, pedestrians, etc.) vary over time, thus yielding only coarsely paired data. To address this challenge, this work introduces a data generation framework based on a high-fidelity game engine for extracting perfectly paired images. By leveraging software APIs that communicate with the GTA game engine, the framework modifies illumination and weather conditions while preserving scene geometry, camera pose, and the identity and placement of dynamic objects. For each sampled location, it procedurally instantiates dynamic entities and renders pixel-aligned images under diverse adverse conditions. The benefit of the proposed generation framework in driving scenarios is demonstrated through a systematic analysis of semantic segmentation models, whose output degradation can be attributed more directly to photometric shifts rather than to uncontrolled semantic or geometric factors.
Microscaling Floating Point Formats for Large Language Models
Oct 02, 2025The increasing computational and memory demands of large language models (LLMs) necessitate innovative approaches to optimize resource usage without compromising performance. This paper leverages microscaling floating-point formats, a novel technique designed to address these challenges by reducing the storage and computational overhead associated with numerical representations in LLMs. Unlike traditional floating-point representations that allocate a dedicated scale for each value, microscaling employs a shared scale across a block of values, enabling compact one-byte floating-point representations while maintaining an extended dynamic range. We explore the application of microscaling in the context of 8-bit floating-point formats to significantly reduce memory footprint and computational costs. We tested several configurations of microscaling floats within the GPT-2 LLM architecture, demonstrating that microscaling data formats can achieve competitive accuracy during training and inference, proving its efficacy as a resource-efficient alternative for deploying LLMs at scale. The source code is publicly available at: https://github.com/unipi-dii-compressedarith/llm.c-sve
Informed deep hierarchical classification: a non-standard analysis inspired approach
Sep 25, 2024This work proposes a novel approach to the deep hierarchical classification task, i.e., the problem of classifying data according to multiple labels organized in a rigid parent-child structure. It consists in a multi-output deep neural network equipped with specific projection operators placed before each output layer. The design of such an architecture, called lexicographic hybrid deep neural network (LH-DNN), has been possible by combining tools from different and quite distant research fields: lexicographic multi-objective optimization, non-standard analysis, and deep learning. To assess the efficacy of the approach, the resulting network is compared against the B-CNN, a convolutional neural network tailored for hierarchical classification tasks, on the CIFAR10, CIFAR100 (where it has been originally and recently proposed before being adopted and tuned for multiple real-world applications) and Fashion-MNIST benchmarks. Evidence states that an LH-DNN can achieve comparable if not superior performance, especially in the learning of the hierarchical relations, in the face of a drastic reduction of the learning parameters, training epochs, and computational time, without the need for ad-hoc loss functions weighting values.
Compressed Real Numbers for AI: a case-study using a RISC-V CPU
Sep 11, 2023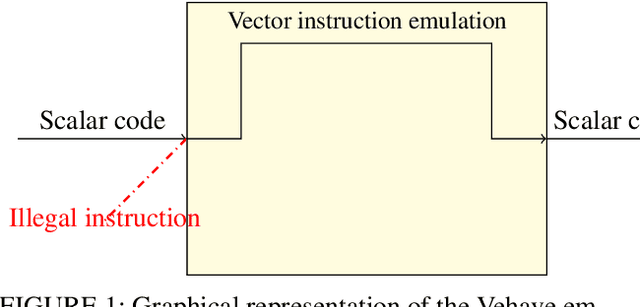
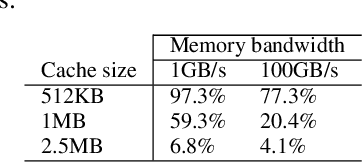

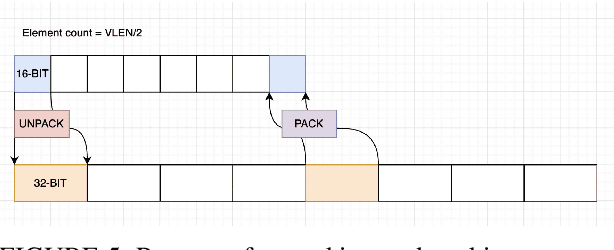
As recently demonstrated, Deep Neural Networks (DNN), usually trained using single precision IEEE 754 floating point numbers (binary32), can also work using lower precision. Therefore, 16-bit and 8-bit compressed format have attracted considerable attention. In this paper, we focused on two families of formats that have already achieved interesting results in compressing binary32 numbers in machine learning applications, without sensible degradation of the accuracy: bfloat and posit. Even if 16-bit and 8-bit bfloat/posit are routinely used for reducing the storage of the weights/biases of trained DNNs, the inference still often happens on the 32-bit FPU of the CPU (especially if GPUs are not available). In this paper we propose a way to decompress a tensor of bfloat/posits just before computations, i.e., after the compressed operands have been loaded within the vector registers of a vector capable CPU, in order to save bandwidth usage and increase cache efficiency. Finally, we show the architectural parameters and considerations under which this solution is advantageous with respect to the uncompressed one.