 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Analysis of POMDP Policies to Observation Perturbations
Apr 23, 2026Policies for Partially Observable Markov Decision Processes (POMDPs) are often designed using a nominal system model. In practice, this model can deviate from the true system during deployment due to factors such as calibration drift or sensor degradation, leading to unexpected performance degradation. This work studies policy robustness against deviations in the POMDP observation model. We introduce the Policy Observation Robustness Problem: to determine the maximum tolerable deviation in a POMDP's observation model that guarantees the policy's value remains above a specified threshold. We analyze two variants: the sticky variant, where deviations are dependent on state and actions, and the non-sticky variant, where they can be history-dependent. We show that the Policy Observation Robustness Problem can be formulated as a bi-level optimization problem in which the inner optimization is monotonic in the size of the observation deviation. This enables efficient solutions using root-finding algorithms in the outer optimization. For the non-sticky variant, we show that when policies are represented with finite-state controllers (FSCs) it is sufficient to consider observations which depend on nodes in the FSC rather than full histories. We present Robust Interval Search, an algorithm with soundness and convergence guarantees, for both the sticky and non-sticky variants. We show this algorithm has polynomial time complexity in the non-sticky variant and at most exponential time complexity in the sticky variant. We provide experimental results validating and demonstrating the scalability of implementations of Robust Interval Search to POMDP problems with tens of thousands of states. We also provide case studies from robotics and operations research which demonstrate the practical utility of the problem and algorithms.
Sampling-based Task and Kinodynamic Motion Planning under Semantic Uncertainty
Apr 01, 2026This paper tackles the problem of integrated task and kinodynamic motion planning in uncertain environments. We consider a robot with nonlinear dynamics tasked with a Linear Temporal Logic over finite traces ($\ltlf$) specification operating in a partially observable environment. Specifically, the uncertainty is in the semantic labels of the environment. We show how the problem can be modeled as a Partially Observable Stochastic Hybrid System that captures the robot dynamics, $\ltlf$ task, and uncertainty in the environment state variables. We propose an anytime algorithm that takes advantage of the structure of the hybrid system, and combines the effectiveness of decision-making techniques and sampling-based motion planning. We prove the soundness and asymptotic optimality of the algorithm. Results show the efficacy of our algorithm in uncertain environments, and that it consistently outperforms baseline methods.
Leveraging the Value of Information in POMDP Planning
Apr 01, 2026Partially observable Markov decision processes (POMDPs) offer a principled formalism for planning under state and transition uncertainty. Despite advances made towards solving large POMDPs, obtaining performant policies under limited planning time remains a major challenge due to the curse of dimensionality and the curse of history. For many POMDP problems, the value of information (VOI) - the expected performance gain from reasoning about observations - varies over the belief space. We introduce a dynamic programming framework that exploits this structure by conditionally processing observations based on the value of information at each belief. Building on this framework, we propose Value of Information Monte Carlo planning (VOIMCP), a Monte Carlo Tree Search algorithm that allocates computational effort more efficiently by selectively disregarding observation information when the VOI is low, avoiding unnecessary branching of observations. We provide theoretical guarantees on the near-optimality of our VOI reasoning framework and derive non-asymptotic convergence bounds for VOIMCP. Simulation evaluations demonstrate that VOIMCP outperforms baselines on several POMDP benchmarks.
Kino-PAX$^+$: Near-Optimal Massively Parallel Kinodynamic Sampling-based Motion Planner
Feb 02, 2026Sampling-based motion planners (SBMPs) are widely used for robot motion planning with complex kinodynamic constraints in high-dimensional spaces, yet they struggle to achieve \emph{real-time} performance due to their serial computation design. Recent efforts to parallelize SBMPs have achieved significant speedups in finding feasible solutions; however, they provide no guarantees of optimizing an objective function. We introduce Kino-PAX$^{+}$, a massively parallel kinodynamic SBMP with asymptotic near-optimal guarantees. Kino-PAX$^{+}$ builds a sparse tree of dynamically feasible trajectories by decomposing traditionally serial operations into three massively parallel subroutines. The algorithm focuses computation on the most promising nodes within local neighborhoods for propagation and refinement, enabling rapid improvement of solution cost. We prove that, while maintaining probabilistic $δ$-robust completeness, this focus on promising nodes ensures asymptotic $δ$-robust near-optimality. Our results show that Kino-PAX$^{+}$ finds solutions up to three orders of magnitude faster than existing serial methods and achieves lower solution costs than a state-of-the-art GPU-based planner.
Kino-PAX: Highly Parallel Kinodynamic Sampling-based Planner
Sep 10, 2024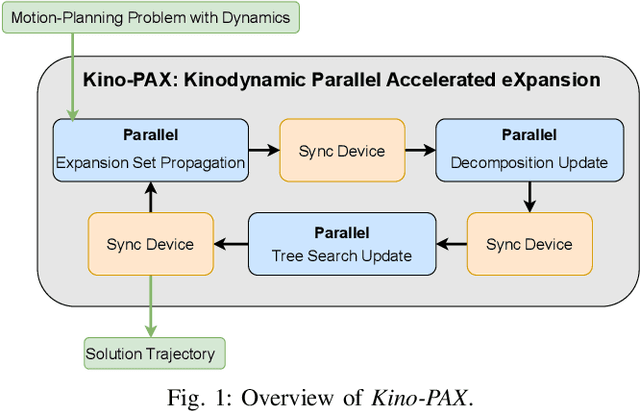
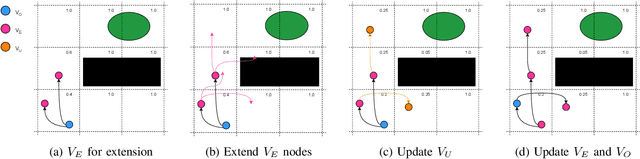
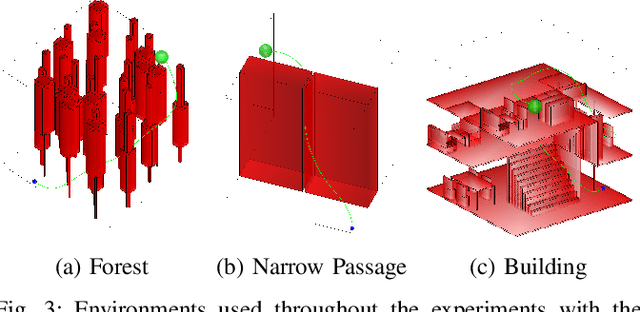
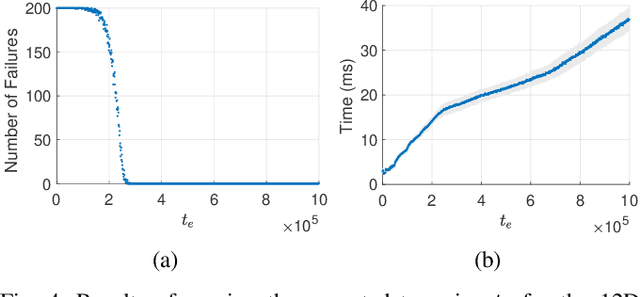
Sampling-based motion planners (SBMPs) are effective for planning with complex kinodynamic constraints in high-dimensional spaces, but they still struggle to achieve real-time performance, which is mainly due to their serial computation design. We present Kinodynamic Parallel Accelerated eXpansion (Kino-PAX), a novel highly parallel kinodynamic SBMP designed for parallel devices such as GPUs. Kino-PAX grows a tree of trajectory segments directly in parallel. Our key insight is how to decompose the iterative tree growth process into three massively parallel subroutines. Kino-PAX is designed to align with the parallel device execution hierarchies, through ensuring that threads are largely independent, share equal workloads, and take advantage of low-latency resources while minimizing high-latency data transfers and process synchronization. This design results in a very efficient GPU implementation. We prove that Kino-PAX is probabilistically complete and analyze its scalability with compute hardware improvements. Empirical evaluations demonstrate solutions in the order of 10 ms on a desktop GPU and in the order of 100 ms on an embedded GPU, representing up to 1000 times improvement compared to coarse-grained CPU parallelization of state-of-the-art sequential algorithms over a range of complex environments and systems.
Beyond Winning Strategies: Admissible and Admissible Winning Strategies for Quantitative Reachability Games
Aug 23, 2024Classical reactive synthesis approaches aim to synthesize a reactive system that always satisfies a given specifications. These approaches often reduce to playing a two-player zero-sum game where the goal is to synthesize a winning strategy. However, in many pragmatic domains, such as robotics, a winning strategy does not always exist, yet it is desirable for the system to make an effort to satisfy its requirements instead of "giving up". To this end, this paper investigates the notion of admissible strategies, which formalize "doing-your-best", in quantitative reachability games. We show that, unlike the qualitative case, quantitative admissible strategies are history-dependent even for finite payoff functions, making synthesis a challenging task. In addition, we prove that admissible strategies always exist but may produce undesirable optimistic behaviors. To mitigate this, we propose admissible winning strategies, which enforce the best possible outcome while being admissible. We show that both strategies always exist but are not memoryless. We provide necessary and sufficient conditions for the existence of both strategies and propose synthesis algorithms. Finally, we illustrate the strategies on gridworld and robot manipulator domains.
Sound Heuristic Search Value Iteration for Undiscounted POMDPs with Reachability Objectives
Jun 05, 2024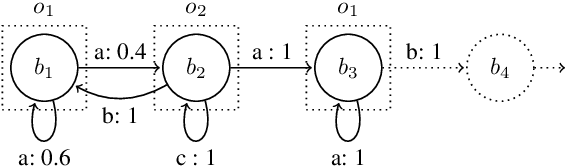
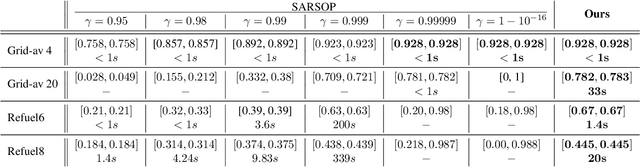
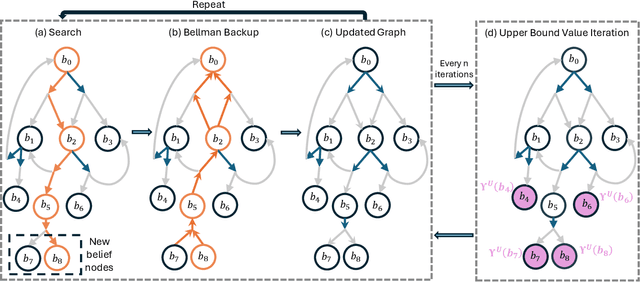
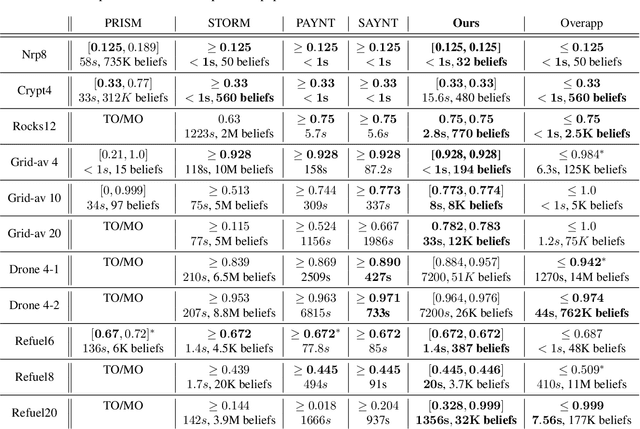
Partially Observable Markov Decision Processes (POMDPs) are powerful models for sequential decision making under transition and observation uncertainties. This paper studies the challenging yet important problem in POMDPs known as the (indefinite-horizon) Maximal Reachability Probability Problem (MRPP), where the goal is to maximize the probability of reaching some target states. This is also a core problem in model checking with logical specifications and is naturally undiscounted (discount factor is one). Inspired by the success of point-based methods developed for discounted problems, we study their extensions to MRPP. Specifically, we focus on trial-based heuristic search value iteration techniques and present a novel algorithm that leverages the strengths of these techniques for efficient exploration of the belief space (informed search via value bounds) while addressing their drawbacks in handling loops for indefinite-horizon problems. The algorithm produces policies with two-sided bounds on optimal reachability probabilities. We prove convergence to an optimal policy from below under certain conditions. Experimental evaluations on a suite of benchmarks show that our algorithm outperforms existing methods in almost all cases in both probability guarantees and computation time.
Recursively-Constrained Partially Observable Markov Decision Processes
Oct 15, 2023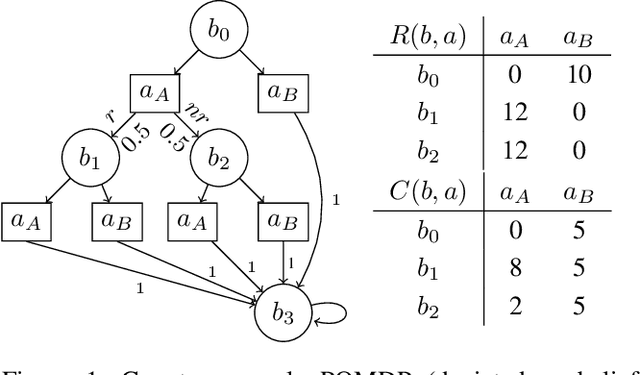
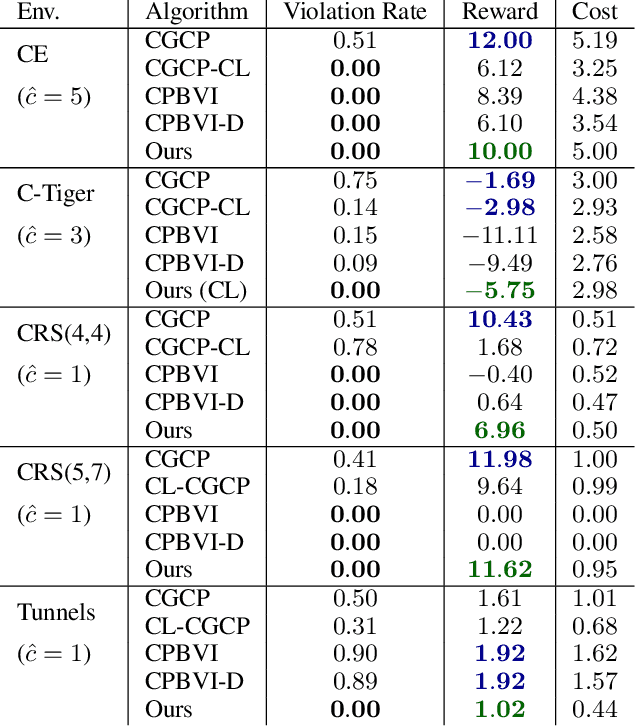
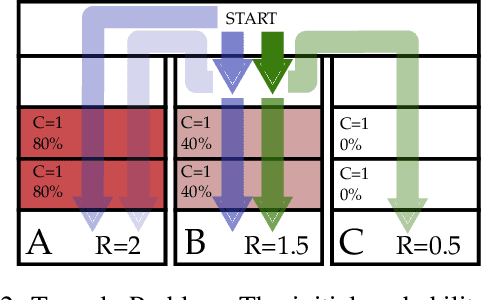
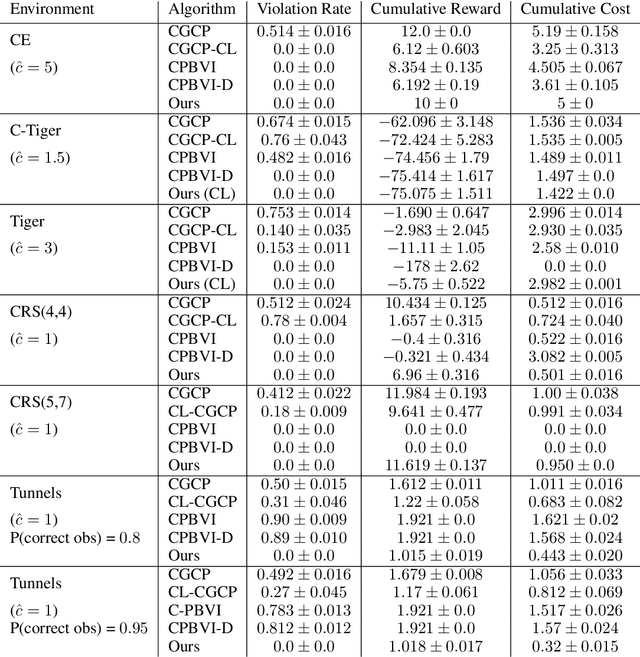
In many problems, it is desirable to optimize an objective function while imposing constraints on some other aspect of the problem. A Constrained Partially Observable Markov Decision Process (C-POMDP) allows modelling of such problems while subject to transition uncertainty and partial observability. Typically, the constraints in C-POMDPs enforce a threshold on expected cumulative costs starting from an initial state distribution. In this work, we first show that optimal C-POMDP policies may violate Bellman's principle of optimality and thus may exhibit pathological behaviors, which can be undesirable for many applications. To address this drawback, we introduce a new formulation, the Recursively-Constrained POMDP (RC-POMDP), that imposes additional history dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies, and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm that synthesizes optimal policies for RC-POMDPs. In our evaluations, we show that policies for RC-POMDPs produce more desirable behavior than policies for C-POMDPs and demonstrate the efficacy of our algorithm across a set of benchmark problems.
Sampling-based Reactive Synthesis for Nondeterministic Hybrid Systems
Apr 14, 2023
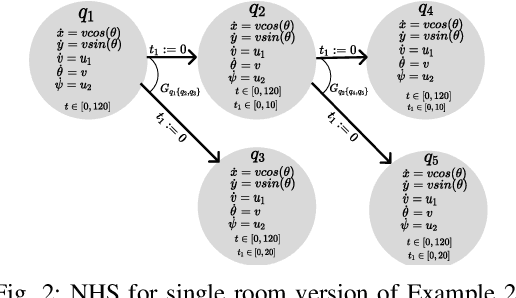
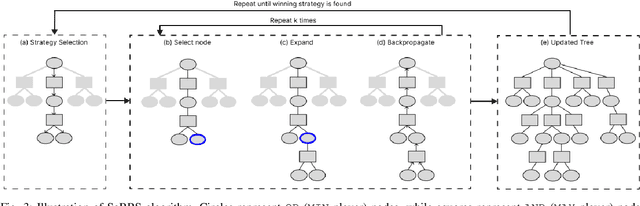
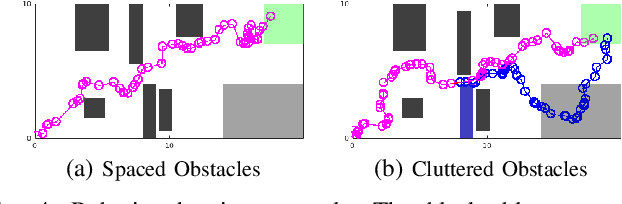
This paper introduces a sampling-based strategy synthesis algorithm for nondeterministic hybrid systems with complex continuous dynamics under temporal and reachability constraints. We view the evolution of the hybrid system as a two-player game, where the nondeterminism is an adversarial player whose objective is to prevent achieving temporal and reachability goals. The aim is to synthesize a winning strategy -- a reactive (robust) strategy that guarantees the satisfaction of the goals under all possible moves of the adversarial player. The approach is based on growing a (search) game-tree in the hybrid space by combining a sampling-based planning method with a novel bandit-based technique to select and improve on partial strategies. We provide conditions under which the algorithm is probabilistically complete, i.e., if a winning strategy exists, the algorithm will almost surely find it. The case studies and benchmark results show that the algorithm is general and consistently outperforms the state of the art.
Planning with SiMBA: Motion Planning under Uncertainty for Temporal Goals using Simplified Belief Guides
Oct 18, 2022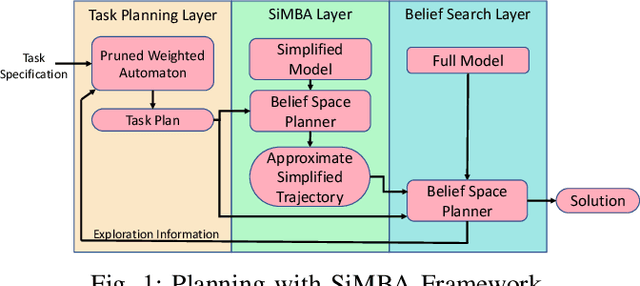
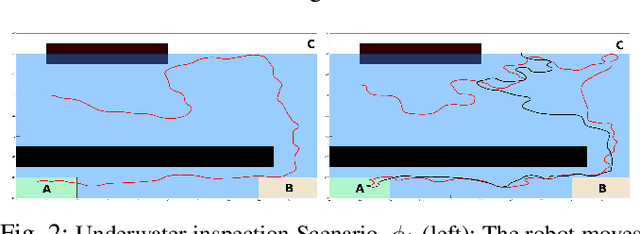
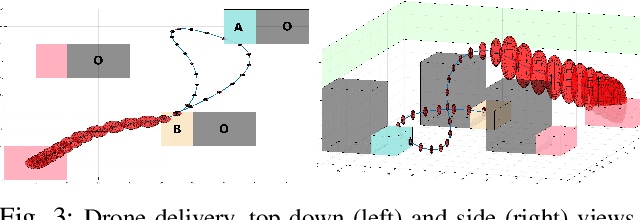

This paper presents a new multi-layered algorithm for motion planning under motion and sensing uncertainties for Linear Temporal Logic specifications. We propose a technique to guide a sampling-based search tree in the combined task and belief space using trajectories from a simplified model of the system, to make the problem computationally tractable. Our method eliminates the need to construct fine and accurate finite abstractions. We prove correctness and probabilistic completeness of our algorithm, and illustrate the benefits of our approach on several case studies. Our results show that guidance with a simplified belief space model allows for significant speed-up in planning for complex specifications.