 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Counterfactual Paths for Contrastive Explanations of POMDP Policies
Mar 28, 2024


As humans come to rely on autonomous systems more, ensuring the transparency of such systems is important to their continued adoption. Explainable Artificial Intelligence (XAI) aims to reduce confusion and foster trust in systems by providing explanations of agent behavior. Partially observable Markov decision processes (POMDPs) provide a flexible framework capable of reasoning over transition and state uncertainty, while also being amenable to explanation. This work investigates the use of user-provided counterfactuals to generate contrastive explanations of POMDP policies. Feature expectations are used as a means of contrasting the performance of these policies. We demonstrate our approach in a Search and Rescue (SAR) setting. We analyze and discuss the associated challenges through two case studies.
Recursively-Constrained Partially Observable Markov Decision Processes
Oct 15, 2023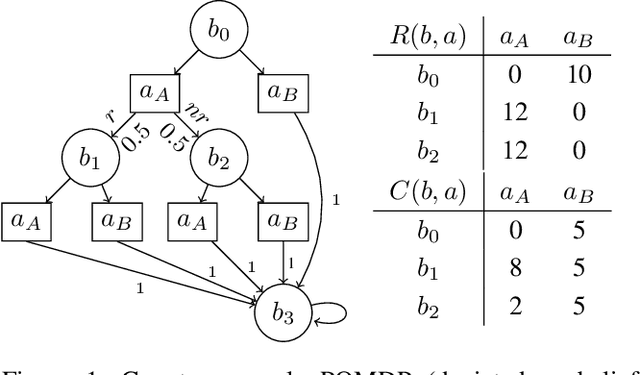
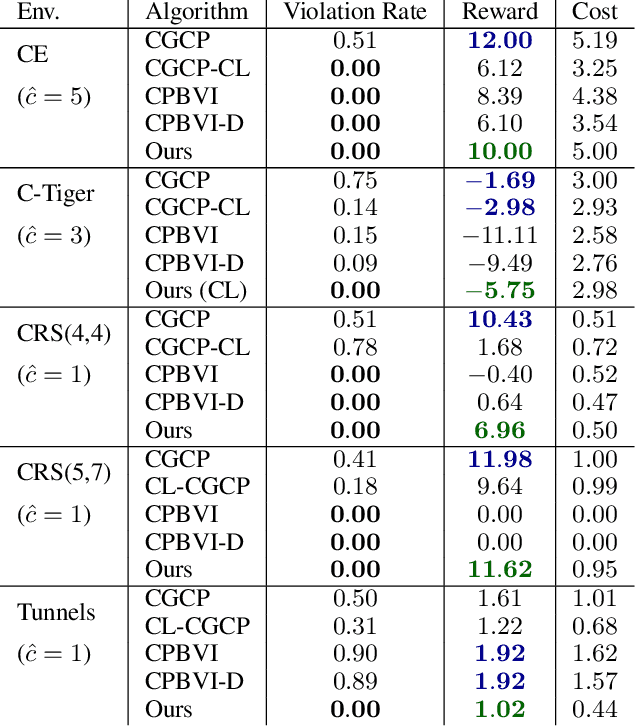
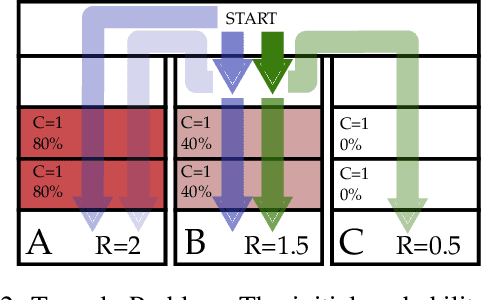
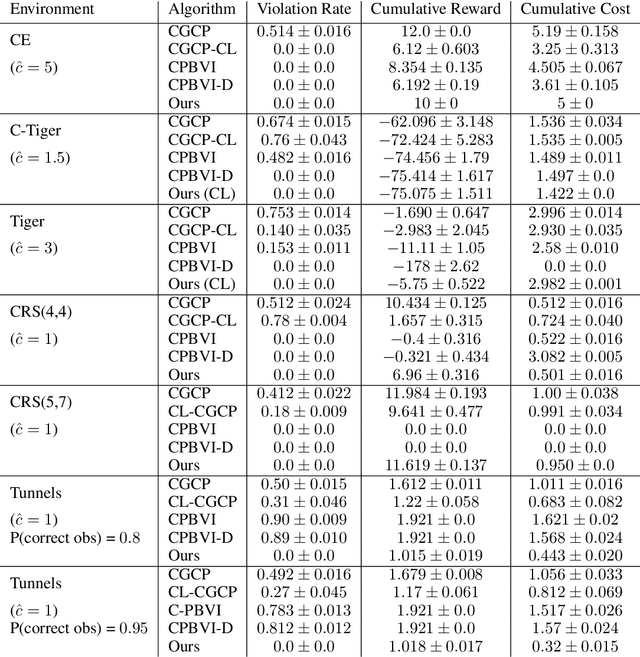
In many problems, it is desirable to optimize an objective function while imposing constraints on some other aspect of the problem. A Constrained Partially Observable Markov Decision Process (C-POMDP) allows modelling of such problems while subject to transition uncertainty and partial observability. Typically, the constraints in C-POMDPs enforce a threshold on expected cumulative costs starting from an initial state distribution. In this work, we first show that optimal C-POMDP policies may violate Bellman's principle of optimality and thus may exhibit pathological behaviors, which can be undesirable for many applications. To address this drawback, we introduce a new formulation, the Recursively-Constrained POMDP (RC-POMDP), that imposes additional history dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies, and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm that synthesizes optimal policies for RC-POMDPs. In our evaluations, we show that policies for RC-POMDPs produce more desirable behavior than policies for C-POMDPs and demonstrate the efficacy of our algorithm across a set of benchmark problems.
Human-Centered Autonomy for UAS Target Search
Sep 18, 2023



Current methods of deploying robots that operate in dynamic, uncertain environments, such as Uncrewed Aerial Systems in search \& rescue missions, require nearly continuous human supervision for vehicle guidance and operation. These methods do not consider high-level mission context resulting in cumbersome manual operation or inefficient exhaustive search patterns. We present a human-centered autonomous framework that infers geospatial mission context through dynamic feature sets, which then guides a probabilistic target search planner. Operators provide a set of diverse inputs, including priority definition, spatial semantic information about ad-hoc geographical areas, and reference waypoints, which are probabilistically fused with geographical database information and condensed into a geospatial distribution representing an operator's preferences over an area. An online, POMDP-based planner, optimized for target searching, is augmented with this reward map to generate an operator-constrained policy. Our results, simulated based on input from five professional rescuers, display effective task mental model alignment, 18\% more victim finds, and 15 times more efficient guidance plans then current operational methods.
Investigation of risk-aware MDP and POMDP contingency management autonomy for UAS
Apr 03, 2023Unmanned aircraft systems (UAS) are being increasingly adopted for various applications. The risk UAS poses to people and property must be kept to acceptable levels. This paper proposes risk-aware contingency management autonomy to prevent an accident in the event of component malfunction, specifically propulsion unit failure and/or battery degradation. The proposed autonomy is modeled as a Markov Decision Process (MDP) whose solution is a contingency management policy that appropriately executes emergency landing, flight termination or continuation of planned flight actions. Motivated by the potential for errors in fault/failure indicators, partial observability of the MDP state space is investigated. The performance of optimal policies is analyzed over varying observability conditions in a high-fidelity simulator. Results indicate that both partially observable MDP (POMDP) and maximum a posteriori MDP policies performed similarly over different state observability criteria, given the nearly deterministic state transition model.