 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Generalized People Diversity: Learning a Human Perception-Aligned Diversity Representation for People Images
Jan 25, 2024



Capturing the diversity of people in images is challenging: recent literature tends to focus on diversifying one or two attributes, requiring expensive attribute labels or building classifiers. We introduce a diverse people image ranking method which more flexibly aligns with human notions of people diversity in a less prescriptive, label-free manner. The Perception-Aligned Text-derived Human representation Space (PATHS) aims to capture all or many relevant features of people-related diversity, and, when used as the representation space in the standard Maximal Marginal Relevance (MMR) ranking algorithm, is better able to surface a range of types of people-related diversity (e.g. disability, cultural attire). PATHS is created in two stages. First, a text-guided approach is used to extract a person-diversity representation from a pre-trained image-text model. Then this representation is fine-tuned on perception judgments from human annotators so that it captures the aspects of people-related similarity that humans find most salient. Empirical results show that the PATHS method achieves diversity better than baseline methods, according to side-by-side ratings from human annotators.
Consensus and Subjectivity of Skin Tone Annotation for ML Fairness
May 16, 2023



Recent advances in computer vision fairness have relied on datasets augmented with perceived attribute signals (e.g. gender presentation, skin tone, and age) and benchmarks enabled by these datasets. Typically labels for these tasks come from human annotators. However, annotating attribute signals, especially skin tone, is a difficult and subjective task. Perceived skin tone is affected by technical factors, like lighting conditions, and social factors that shape an annotator's lived experience. This paper examines the subjectivity of skin tone annotation through a series of annotation experiments using the Monk Skin Tone (MST) scale, a small pool of professional photographers, and a much larger pool of trained crowdsourced annotators. Our study shows that annotators can reliably annotate skin tone in a way that aligns with an expert in the MST scale, even under challenging environmental conditions. We also find evidence that annotators from different geographic regions rely on different mental models of MST categories resulting in annotations that systematically vary across regions. Given this, we advise practitioners to use a diverse set of annotators and a higher replication count for each image when annotating skin tone for fairness research.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
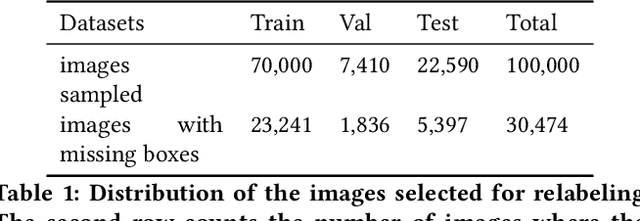
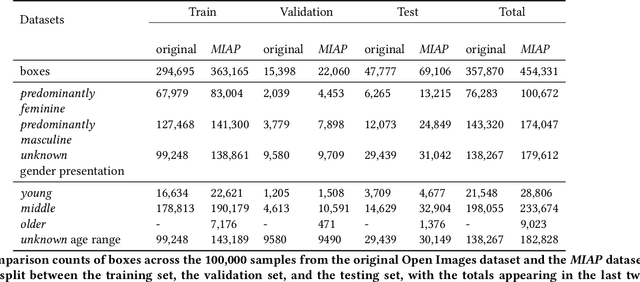
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


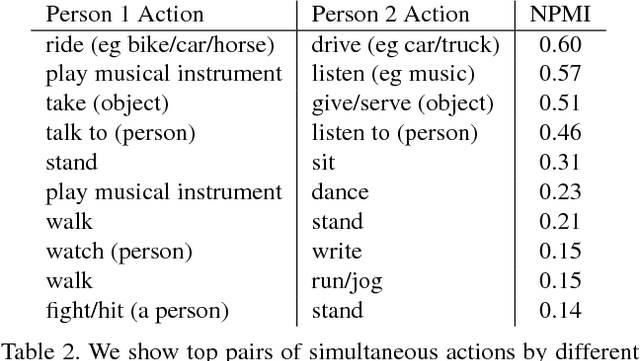
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.
Motion Prediction Under Multimodality with Conditional Stochastic Networks
May 05, 2017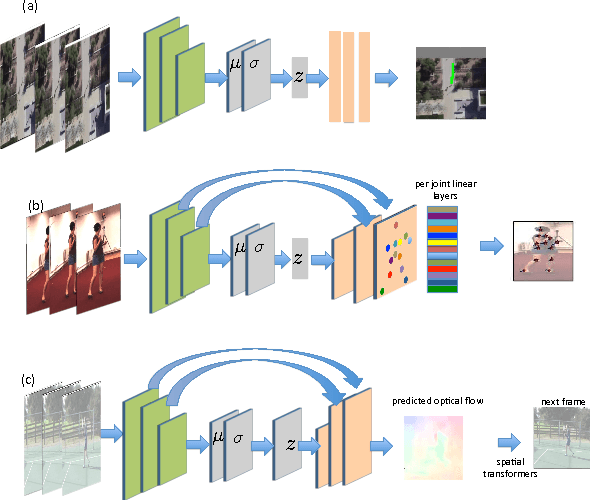
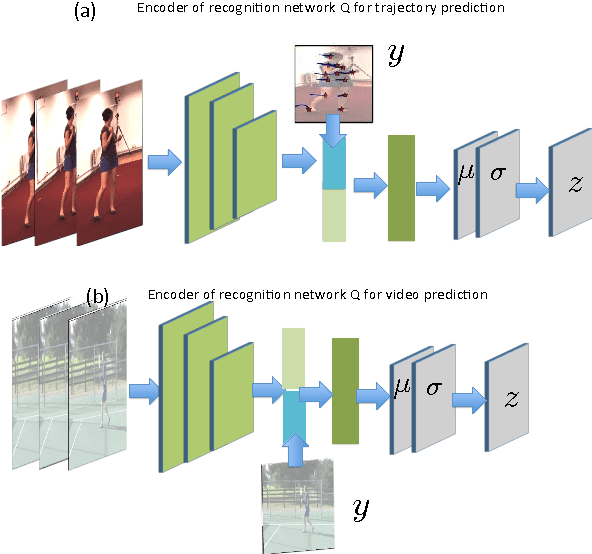

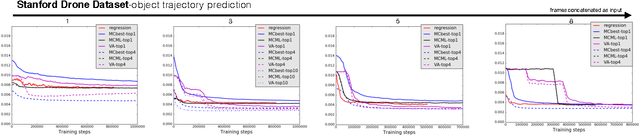
Given a visual history, multiple future outcomes for a video scene are equally probable, in other words, the distribution of future outcomes has multiple modes. Multimodality is notoriously hard to handle by standard regressors or classifiers: the former regress to the mean and the latter discretize a continuous high dimensional output space. In this work, we present stochastic neural network architectures that handle such multimodality through stochasticity: future trajectories of objects, body joints or frames are represented as deep, non-linear transformations of random (as opposed to deterministic) variables. Such random variables are sampled from simple Gaussian distributions whose means and variances are parametrized by the output of convolutional encoders over the visual history. We introduce novel convolutional architectures for predicting future body joint trajectories that outperform fully connected alternatives \cite{DBLP:journals/corr/WalkerDGH16}. We introduce stochastic spatial transformers through optical flow warping for predicting future frames, which outperform their deterministic equivalents \cite{DBLP:journals/corr/PatrauceanHC15}. Training stochastic networks involves an intractable marginalization over stochastic variables. We compare various training schemes that handle such marginalization through a) straightforward sampling from the prior, b) conditional variational autoencoders \cite{NIPS2015_5775,DBLP:journals/corr/WalkerDGH16}, and, c) a proposed K-best-sample loss that penalizes the best prediction under a fixed "prediction budget". We show experimental results on object trajectory prediction, human body joint trajectory prediction and video prediction under varying future uncertainty, validating quantitatively and qualitatively our architectural choices and training schemes.
SfM-Net: Learning of Structure and Motion from Video
Apr 25, 2017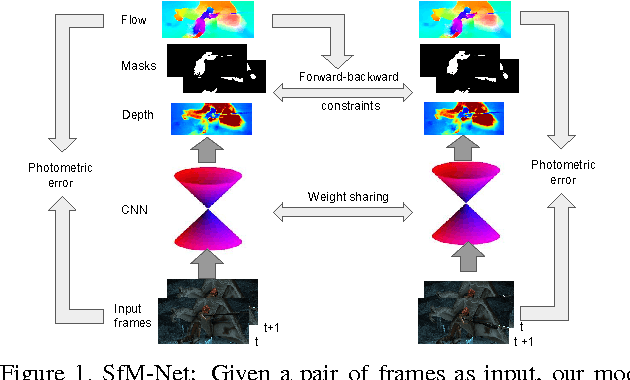
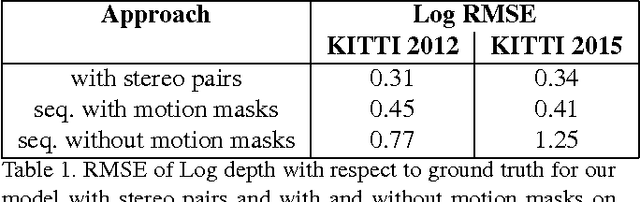
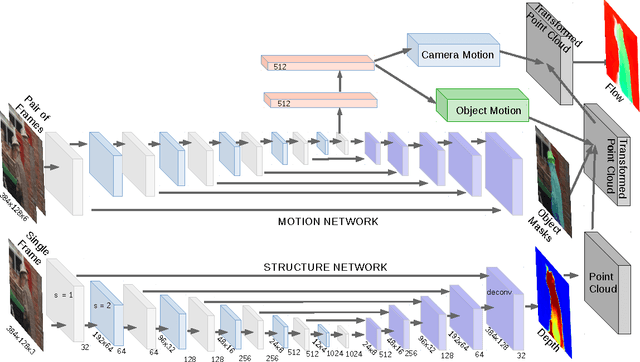
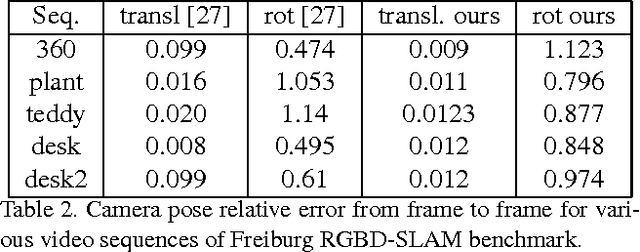
We propose SfM-Net, a geometry-aware neural network for motion estimation in videos that decomposes frame-to-frame pixel motion in terms of scene and object depth, camera motion and 3D object rotations and translations. Given a sequence of frames, SfM-Net predicts depth, segmentation, camera and rigid object motions, converts those into a dense frame-to-frame motion field (optical flow), differentiably warps frames in time to match pixels and back-propagates. The model can be trained with various degrees of supervision: 1) self-supervised by the re-projection photometric error (completely unsupervised), 2) supervised by ego-motion (camera motion), or 3) supervised by depth (e.g., as provided by RGBD sensors). SfM-Net extracts meaningful depth estimates and successfully estimates frame-to-frame camera rotations and translations. It often successfully segments the moving objects in the scene, even though such supervision is never provided.
Recovering Spatiotemporal Correspondence between Deformable Objects by Exploiting Consistent Foreground Motion in Video
Aug 16, 2016

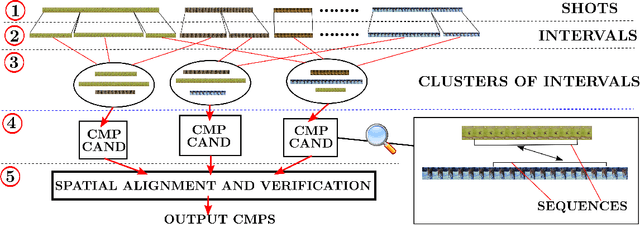
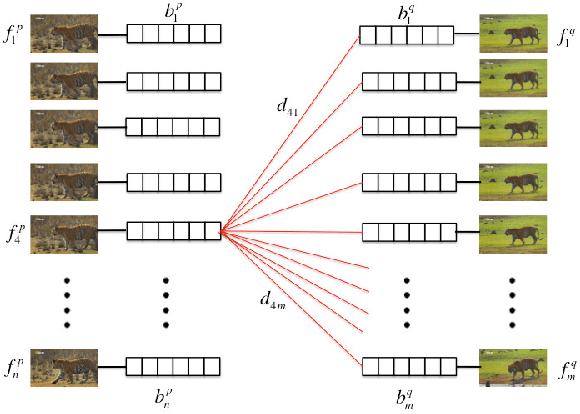
Given unstructured videos of deformable objects, we automatically recover spatiotemporal correspondences to map one object to another (such as animals in the wild). While traditional methods based on appearance fail in such challenging conditions, we exploit consistency in object motion between instances. Our approach discovers pairs of short video intervals where the object moves in a consistent manner and uses these candidates as seeds for spatial alignment. We model the spatial correspondence between the point trajectories on the object in one interval to those in the other using a time-varying Thin Plate Spline deformation model. On a large dataset of tiger and horse videos, our method automatically aligns thousands of pairs of frames to a high accuracy, and outperforms the popular SIFT Flow algorithm.
Behavior Discovery and Alignment of Articulated Object Classes from Unstructured Video
Aug 11, 2016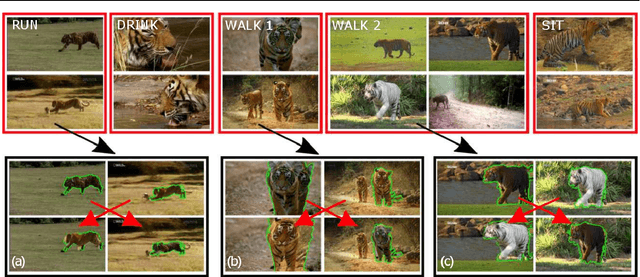
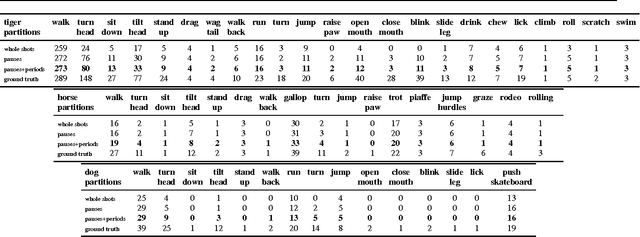
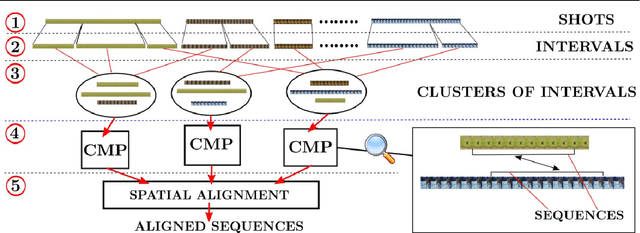
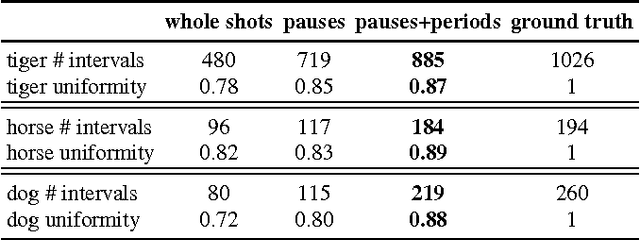
We propose an automatic system for organizing the content of a collection of unstructured videos of an articulated object class (e.g. tiger, horse). By exploiting the recurring motion patterns of the class across videos, our system: 1) identifies its characteristic behaviors; and 2) recovers pixel-to-pixel alignments across different instances. Our system can be useful for organizing video collections for indexing and retrieval. Moreover, it can be a platform for learning the appearance or behaviors of object classes from Internet video. Traditional supervised techniques cannot exploit this wealth of data directly, as they require a large amount of time-consuming manual annotations. The behavior discovery stage generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, clustered by type. It relies on our novel motion representation for articulated motion based on the displacement of ordered pairs of trajectories (PoTs). The alignment stage aligns hundreds of instances of the class to a great accuracy despite considerable appearance variations (e.g. an adult tiger and a cub). It uses a flexible Thin Plate Spline deformation model that can vary through time. We carefully evaluate each step of our system on a new, fully annotated dataset. On behavior discovery, we outperform the state-of-the-art Improved DTF descriptor. On spatial alignment, we outperform the popular SIFT Flow algorithm.
* 19 pages, 19 figure, 3 tables. arXiv admin note: substantial text overlap with arXiv:1411.7883
Articulated motion discovery using pairs of trajectories
Apr 24, 2015
We propose an unsupervised approach for discovering characteristic motion patterns in videos of highly articulated objects performing natural, unscripted behaviors, such as tigers in the wild. We discover consistent patterns in a bottom-up manner by analyzing the relative displacements of large numbers of ordered trajectory pairs through time, such that each trajectory is attached to a different moving part on the object. The pairs of trajectories descriptor relies entirely on motion and is more discriminative than state-of-the-art features that employ single trajectories. Our method generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, and clusters them by type (e.g., running, turning head, drinking water). We present experiments on two datasets: dogs from YouTube-Objects and a new dataset of National Geographic tiger videos. Results confirm that our proposed descriptor outperforms existing appearance- and trajectory-based descriptors (e.g., HOG and DTFs) on both datasets and enables us to segment unconstrained animal video into intervals containing single behaviors.