 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMRNNs: An Efficient Method for Interpretable Dense Retrieval via Embedding Modulation
Jan 27, 2026Interpretability in black-box dense retrievers remains a central challenge in Retrieval-Augmented Generation (RAG). Understanding how queries and documents semantically interact is critical for diagnosing retrieval behavior and improving model design. However, existing dense retrievers rely on static embeddings for both queries and documents, which obscures this bidirectional relationship. Post-hoc approaches such as re-rankers are computationally expensive, add inference latency, and still fail to reveal the underlying semantic alignment. To address these limitations, we propose Interpretable Modular Retrieval Neural Networks (IMRNNs), a lightweight framework that augments any dense retriever with dynamic, bidirectional modulation at inference time. IMRNNs employ two independent adapters: one conditions document embeddings on the current query, while the other refines the query embedding using corpus-level feedback from initially retrieved documents. This iterative modulation process enables the model to adapt representations dynamically and expose interpretable semantic dependencies between queries and documents. Empirically, IMRNNs not only enhance interpretability but also improve retrieval effectiveness. Across seven benchmark datasets, applying our method to standard dense retrievers yields average gains of +6.35% nDCG, +7.14% recall, and +7.04% MRR over state-of-the-art baselines. These results demonstrate that incorporating interpretability-driven modulation can both explain and enhance retrieval in RAG systems.
Neurosymbolic Retrievers for Retrieval-augmented Generation
Jan 08, 2026Retrieval Augmented Generation (RAG) has made significant strides in overcoming key limitations of large language models, such as hallucination, lack of contextual grounding, and issues with transparency. However, traditional RAG systems consist of three interconnected neural components - the retriever, re-ranker, and generator - whose internal reasoning processes remain opaque. This lack of transparency complicates interpretability, hinders debugging efforts, and erodes trust, especially in high-stakes domains where clear decision-making is essential. To address these challenges, we introduce the concept of Neurosymbolic RAG, which integrates symbolic reasoning using a knowledge graph with neural retrieval techniques. This new framework aims to answer two primary questions: (a) Can retrievers provide a clear and interpretable basis for document selection? (b) Can symbolic knowledge enhance the clarity of the retrieval process? We propose three methods to improve this integration. First is MAR (Knowledge Modulation Aligned Retrieval) that employs modulation networks to refine query embeddings using interpretable symbolic features, thereby making document matching more explicit. Second, KG-Path RAG enhances queries by traversing knowledge graphs to improve overall retrieval quality and interpretability. Lastly, Process Knowledge-infused RAG utilizes domain-specific tools to reorder retrieved content based on validated workflows. Preliminary results from mental health risk assessment tasks indicate that this neurosymbolic approach enhances both transparency and overall performance
Ranking Free RAG: Replacing Re-ranking with Selection in RAG for Sensitive Domains
May 21, 2025Traditional Retrieval-Augmented Generation (RAG) pipelines rely on similarity-based retrieval and re-ranking, which depend on heuristics such as top-k, and lack explainability, interpretability, and robustness against adversarial content. To address this gap, we propose a novel method METEORA that replaces re-ranking in RAG with a rationale-driven selection approach. METEORA operates in two stages. First, a general-purpose LLM is preference-tuned to generate rationales conditioned on the input query using direct preference optimization. These rationales guide the evidence chunk selection engine, which selects relevant chunks in three stages: pairing individual rationales with corresponding retrieved chunks for local relevance, global selection with elbow detection for adaptive cutoff, and context expansion via neighboring chunks. This process eliminates the need for top-k heuristics. The rationales are also used for consistency check using a Verifier LLM to detect and filter poisoned or misleading content for safe generation. The framework provides explainable and interpretable evidence flow by using rationales consistently across both selection and verification. Our evaluation across six datasets spanning legal, financial, and academic research domains shows that METEORA improves generation accuracy by 33.34% while using approximately 50% fewer chunks than state-of-the-art re-ranking methods. In adversarial settings, METEORA significantly improves the F1 score from 0.10 to 0.44 over the state-of-the-art perplexity-based defense baseline, demonstrating strong resilience to poisoning attacks. Code available at: https://anonymous.4open.science/r/METEORA-DC46/README.md
Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Dec 24, 2024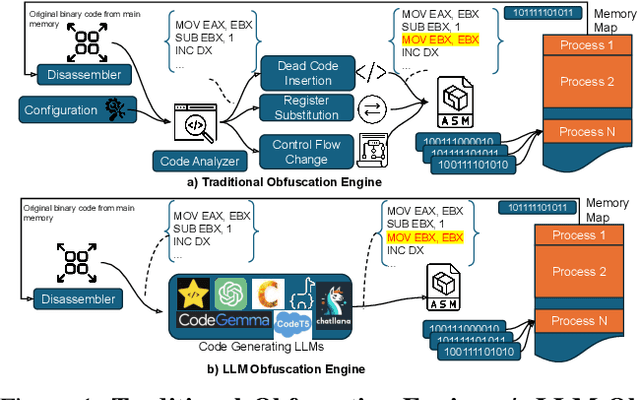


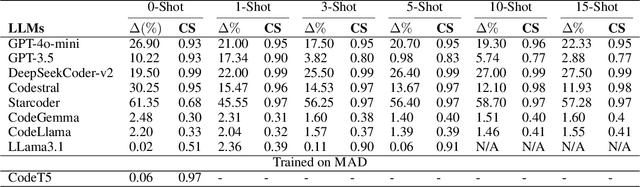
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
REASONS: A benchmark for REtrieval and Automated citationS Of scieNtific Sentences using Public and Proprietary LLMs
May 03, 2024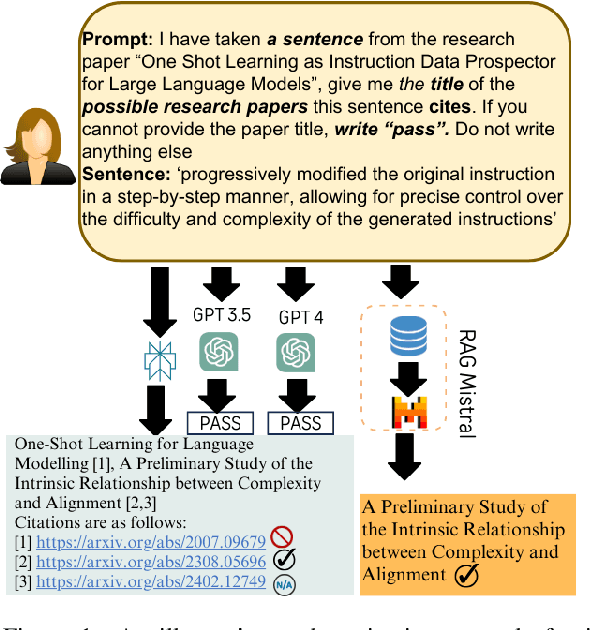
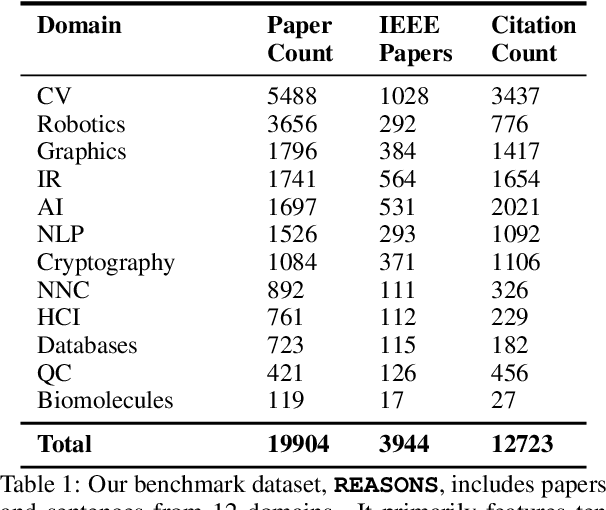
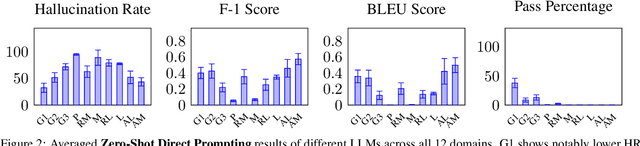
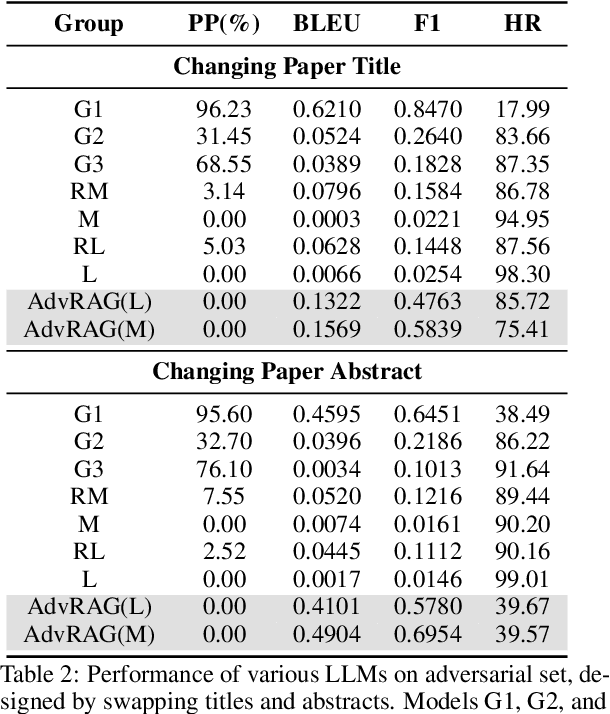
Automatic citation generation for sentences in a document or report is paramount for intelligence analysts, cybersecurity, news agencies, and education personnel. In this research, we investigate whether large language models (LLMs) are capable of generating references based on two forms of sentence queries: (a) Direct Queries, LLMs are asked to provide author names of the given research article, and (b) Indirect Queries, LLMs are asked to provide the title of a mentioned article when given a sentence from a different article. To demonstrate where LLM stands in this task, we introduce a large dataset called REASONS comprising abstracts of the 12 most popular domains of scientific research on arXiv. From around 20K research articles, we make the following deductions on public and proprietary LLMs: (a) State-of-the-art, often called anthropomorphic GPT-4 and GPT-3.5, suffers from high pass percentage (PP) to minimize the hallucination rate (HR). When tested with Perplexity.ai (7B), they unexpectedly made more errors; (b) Augmenting relevant metadata lowered the PP and gave the lowest HR; (c) Advance retrieval-augmented generation (RAG) using Mistral demonstrates consistent and robust citation support on indirect queries and matched performance to GPT-3.5 and GPT-4. The HR across all domains and models decreased by an average of 41.93% and the PP was reduced to 0% in most cases. In terms of generation quality, the average F1 Score and BLEU were 68.09% and 57.51%, respectively; (d) Testing with adversarial samples showed that LLMs, including the Advance RAG Mistral, struggle to understand context, but the extent of this issue was small in Mistral and GPT-4-Preview. Our study con tributes valuable insights into the reliability of RAG for automated citation generation tasks.
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Apr 25, 2024



Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90\% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
Deploying and Evaluating LLMs to Program Service Mobile Robots
Nov 18, 2023



Recent advancements in large language models (LLMs) have spurred interest in using them for generating robot programs from natural language, with promising initial results. We investigate the use of LLMs to generate programs for service mobile robots leveraging mobility, perception, and human interaction skills, and where accurate sequencing and ordering of actions is crucial for success. We contribute CodeBotler, an open-source robot-agnostic tool to program service mobile robots from natural language, and RoboEval, a benchmark for evaluating LLMs' capabilities of generating programs to complete service robot tasks. CodeBotler performs program generation via few-shot prompting of LLMs with an embedded domain-specific language (eDSL) in Python, and leverages skill abstractions to deploy generated programs on any general-purpose mobile robot. RoboEval evaluates the correctness of generated programs by checking execution traces starting with multiple initial states, and checking whether the traces satisfy temporal logic properties that encode correctness for each task. RoboEval also includes multiple prompts per task to test for the robustness of program generation. We evaluate several popular state-of-the-art LLMs with the RoboEval benchmark, and perform a thorough analysis of the modes of failures, resulting in a taxonomy that highlights common pitfalls of LLMs at generating robot programs. We release our code and benchmark at https://amrl.cs.utexas.edu/codebotler/.