 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMRNNs: An Efficient Method for Interpretable Dense Retrieval via Embedding Modulation
Jan 27, 2026Interpretability in black-box dense retrievers remains a central challenge in Retrieval-Augmented Generation (RAG). Understanding how queries and documents semantically interact is critical for diagnosing retrieval behavior and improving model design. However, existing dense retrievers rely on static embeddings for both queries and documents, which obscures this bidirectional relationship. Post-hoc approaches such as re-rankers are computationally expensive, add inference latency, and still fail to reveal the underlying semantic alignment. To address these limitations, we propose Interpretable Modular Retrieval Neural Networks (IMRNNs), a lightweight framework that augments any dense retriever with dynamic, bidirectional modulation at inference time. IMRNNs employ two independent adapters: one conditions document embeddings on the current query, while the other refines the query embedding using corpus-level feedback from initially retrieved documents. This iterative modulation process enables the model to adapt representations dynamically and expose interpretable semantic dependencies between queries and documents. Empirically, IMRNNs not only enhance interpretability but also improve retrieval effectiveness. Across seven benchmark datasets, applying our method to standard dense retrievers yields average gains of +6.35% nDCG, +7.14% recall, and +7.04% MRR over state-of-the-art baselines. These results demonstrate that incorporating interpretability-driven modulation can both explain and enhance retrieval in RAG systems.
Ranking Free RAG: Replacing Re-ranking with Selection in RAG for Sensitive Domains
May 21, 2025Traditional Retrieval-Augmented Generation (RAG) pipelines rely on similarity-based retrieval and re-ranking, which depend on heuristics such as top-k, and lack explainability, interpretability, and robustness against adversarial content. To address this gap, we propose a novel method METEORA that replaces re-ranking in RAG with a rationale-driven selection approach. METEORA operates in two stages. First, a general-purpose LLM is preference-tuned to generate rationales conditioned on the input query using direct preference optimization. These rationales guide the evidence chunk selection engine, which selects relevant chunks in three stages: pairing individual rationales with corresponding retrieved chunks for local relevance, global selection with elbow detection for adaptive cutoff, and context expansion via neighboring chunks. This process eliminates the need for top-k heuristics. The rationales are also used for consistency check using a Verifier LLM to detect and filter poisoned or misleading content for safe generation. The framework provides explainable and interpretable evidence flow by using rationales consistently across both selection and verification. Our evaluation across six datasets spanning legal, financial, and academic research domains shows that METEORA improves generation accuracy by 33.34% while using approximately 50% fewer chunks than state-of-the-art re-ranking methods. In adversarial settings, METEORA significantly improves the F1 score from 0.10 to 0.44 over the state-of-the-art perplexity-based defense baseline, demonstrating strong resilience to poisoning attacks. Code available at: https://anonymous.4open.science/r/METEORA-DC46/README.md
Explainable and Accurate Natural Language Understanding for Voice Assistants and Beyond
Sep 25, 2023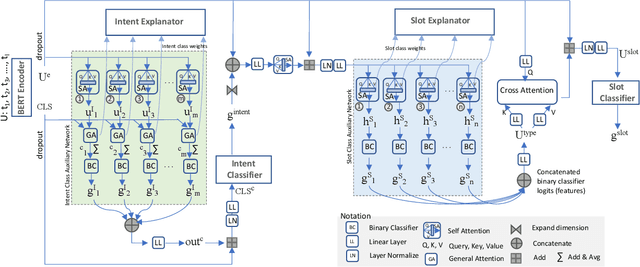
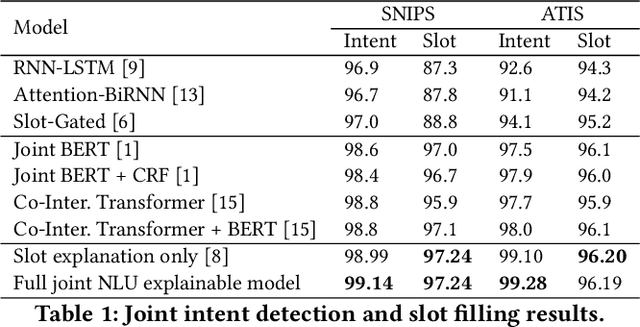

Joint intent detection and slot filling, which is also termed as joint NLU (Natural Language Understanding) is invaluable for smart voice assistants. Recent advancements in this area have been heavily focusing on improving accuracy using various techniques. Explainability is undoubtedly an important aspect for deep learning-based models including joint NLU models. Without explainability, their decisions are opaque to the outside world and hence, have tendency to lack user trust. Therefore to bridge this gap, we transform the full joint NLU model to be `inherently' explainable at granular levels without compromising on accuracy. Further, as we enable the full joint NLU model explainable, we show that our extension can be successfully used in other general classification tasks. We demonstrate this using sentiment analysis and named entity recognition.
AlpaGasus: Training A Better Alpaca with Fewer Data
Jul 17, 2023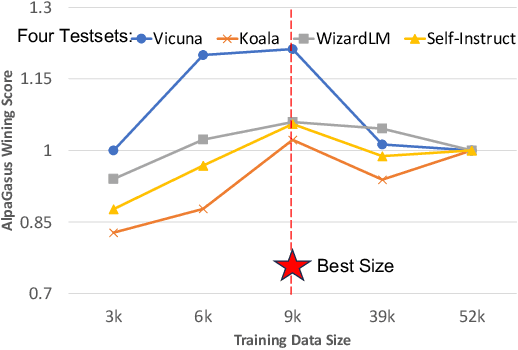
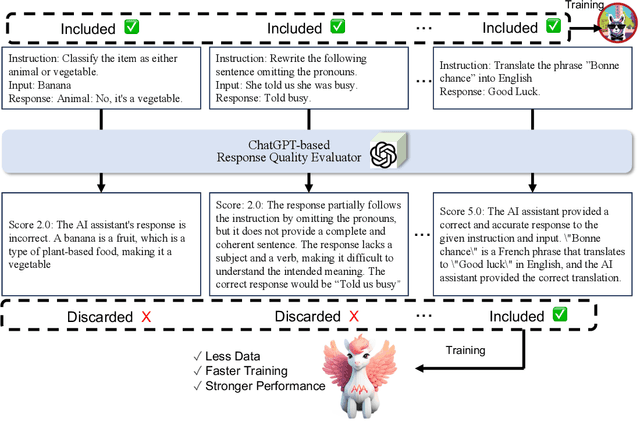
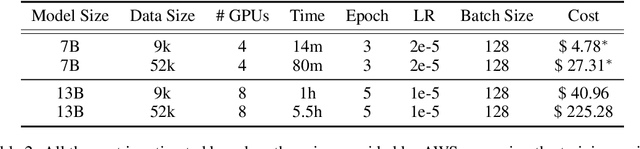

Large language models~(LLMs) obtain instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instances with incorrect or irrelevant responses, which are misleading and detrimental to IFT. In this paper, we propose a simple and effective data selection strategy that automatically identifies and removes low-quality data using a strong LLM (e.g., ChatGPT). To this end, we introduce AlpaGasus, which is finetuned on only 9k high-quality data filtered from the 52k Alpaca data. AlpaGasus significantly outperforms the original Alpaca as evaluated by GPT-4 on multiple test sets and its 13B variant matches $>90\%$ performance of its teacher LLM (i.e., Text-Davinci-003) on test tasks. It also provides 5.7x faster training, reducing the training time for a 7B variant from 80 minutes (for Alpaca) to 14 minutes \footnote{We apply IFT for the same number of epochs as Alpaca(7B) but on fewer data, using 4$\times$NVIDIA A100 (80GB) GPUs and following the original Alpaca setting and hyperparameters.}. Overall, AlpaGasus demonstrates a novel data-centric IFT paradigm that can be generally applied to instruction-tuning data, leading to faster training and better instruction-following models. Our project page is available at: \url{https://lichang-chen.github.io/AlpaGasus/}.
Explainable Slot Type Attentions to Improve Joint Intent Detection and Slot Filling
Oct 19, 2022
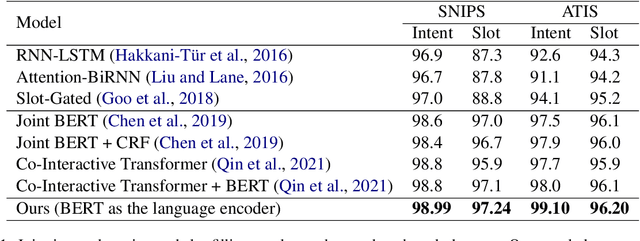
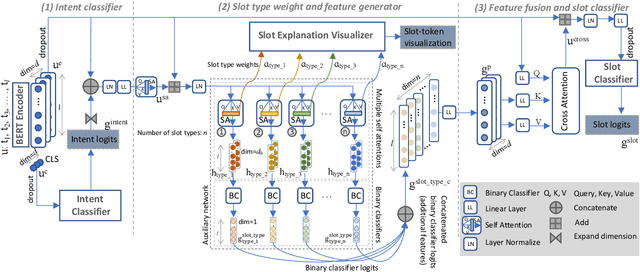
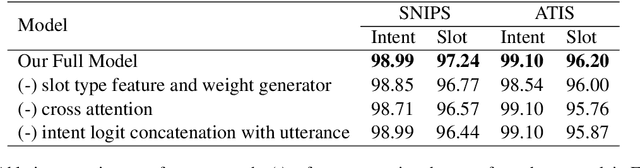
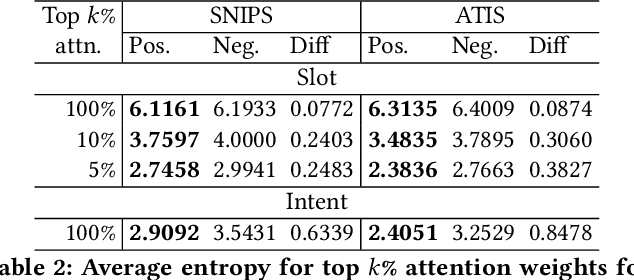
Joint intent detection and slot filling is a key research topic in natural language understanding (NLU). Existing joint intent and slot filling systems analyze and compute features collectively for all slot types, and importantly, have no way to explain the slot filling model decisions. In this work, we propose a novel approach that: (i) learns to generate additional slot type specific features in order to improve accuracy and (ii) provides explanations for slot filling decisions for the first time in a joint NLU model. We perform an additional constrained supervision using a set of binary classifiers for the slot type specific feature learning, thus ensuring appropriate attention weights are learned in the process to explain slot filling decisions for utterances. Our model is inherently explainable and does not need any post-hoc processing. We evaluate our approach on two widely used datasets and show accuracy improvements. Moreover, a detailed analysis is also provided for the exclusive slot explainability.
ISEEQ: Information Seeking Question Generation using Dynamic Meta-Information Retrieval and Knowledge Graphs
Dec 13, 2021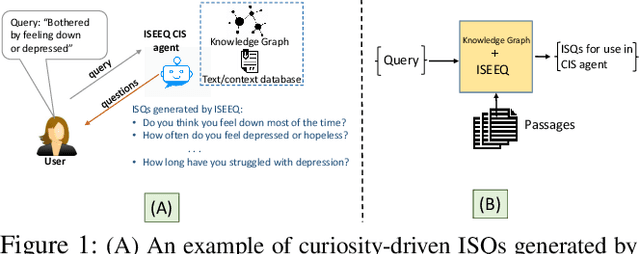
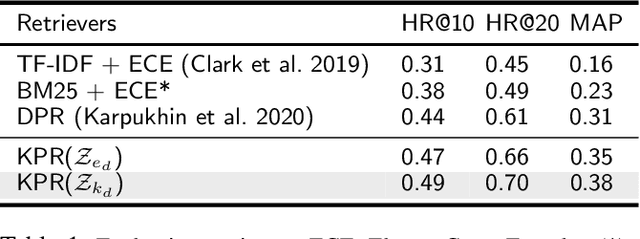
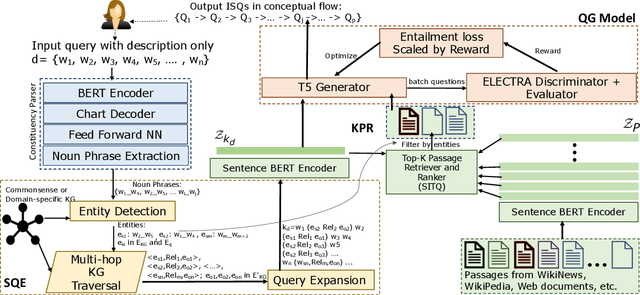
Conversational Information Seeking (CIS) is a relatively new research area within conversational AI that attempts to seek information from end-users in order to understand and satisfy users' needs. If realized, such a system has far-reaching benefits in the real world; for example, a CIS system can assist clinicians in pre-screening or triaging patients in healthcare. A key open sub-problem in CIS that remains unaddressed in the literature is generating Information Seeking Questions (ISQs) based on a short initial query from the end-user. To address this open problem, we propose Information SEEking Question generator (ISEEQ), a novel approach for generating ISQs from just a short user query, given a large text corpus relevant to the user query. Firstly, ISEEQ uses a knowledge graph to enrich the user query. Secondly, ISEEQ uses the knowledge-enriched query to retrieve relevant context passages to ask coherent ISQs adhering to a conceptual flow. Thirdly, ISEEQ introduces a new deep generative-adversarial reinforcement learning-based approach for generating ISQs. We show that ISEEQ can generate high-quality ISQs to promote the development of CIS agents. ISEEQ significantly outperforms comparable baselines on five ISQ evaluation metrics across four datasets having user queries from diverse domains. Further, we argue that ISEEQ is transferable across domains for generating ISQs, as it shows the acceptable performance when trained and tested on different pairs of domains. The qualitative human evaluation confirms ISEEQ-generated ISQs are comparable in quality to human-generated questions and outperform the best comparable baseline.
Using Neighborhood Context to Improve Information Extraction from Visual Documents Captured on Mobile Phones
Aug 23, 2021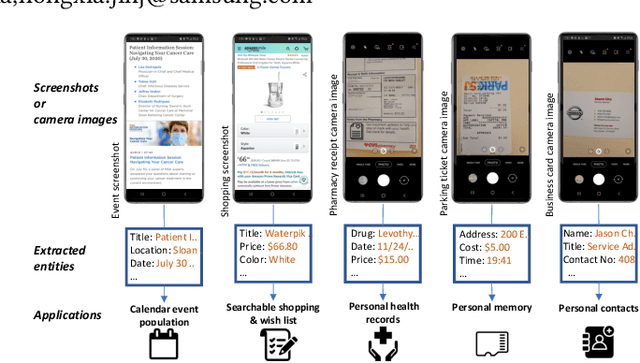

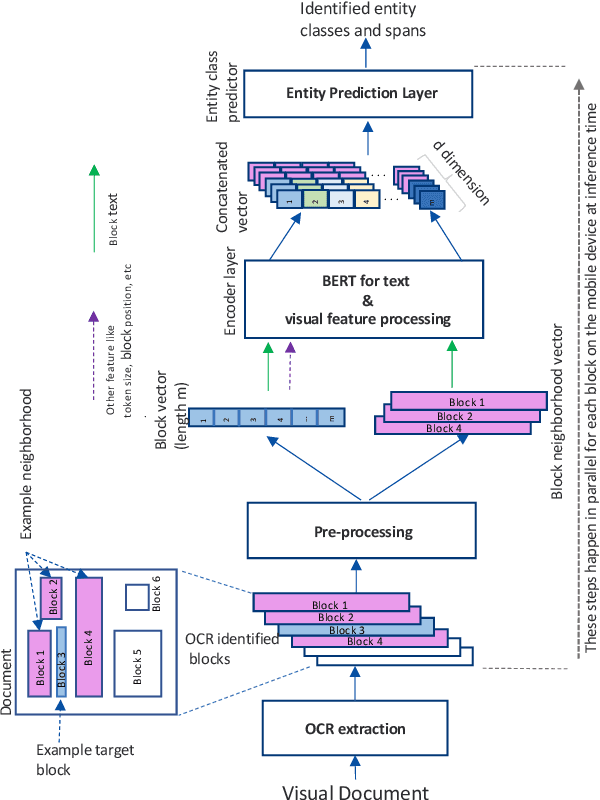
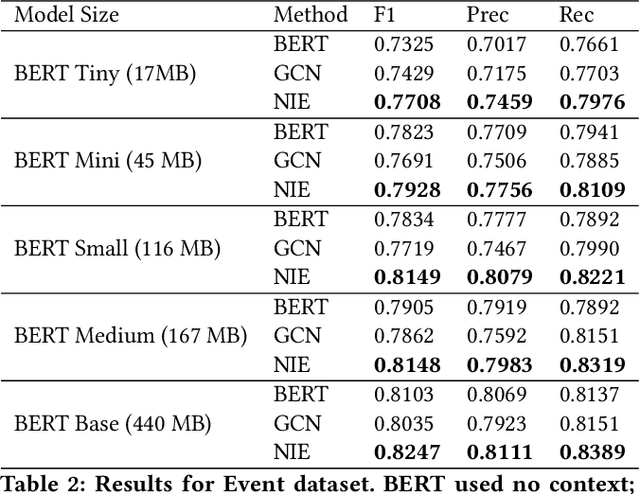
Information Extraction from visual documents enables convenient and intelligent assistance to end users. We present a Neighborhood-based Information Extraction (NIE) approach that uses contextual language models and pays attention to the local neighborhood context in the visual documents to improve information extraction accuracy. We collect two different visual document datasets and show that our approach outperforms the state-of-the-art global context-based IE technique. In fact, NIE outperforms existing approaches in both small and large model sizes. Our on-device implementation of NIE on a mobile platform that generally requires small models showcases NIE's usefulness in practical real-world applications.
Entity Context Graph: Learning Entity Representations fromSemi-Structured Textual Sources on the Web
Mar 29, 2021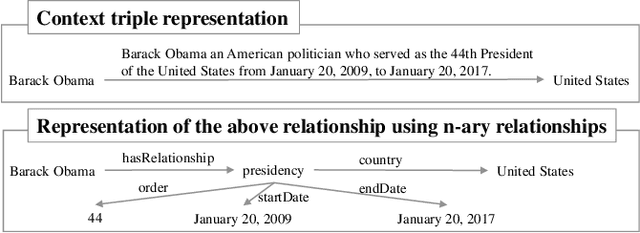
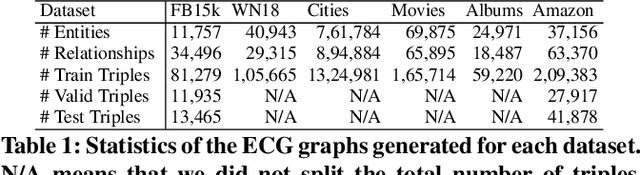
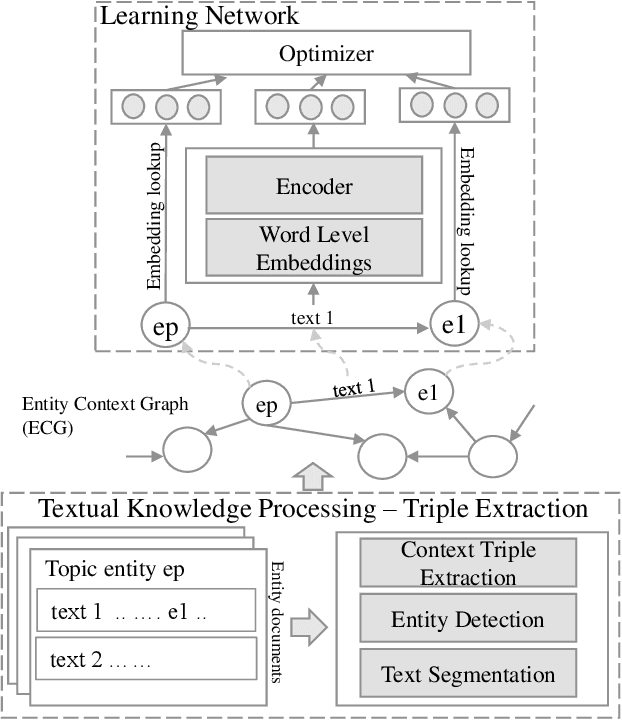
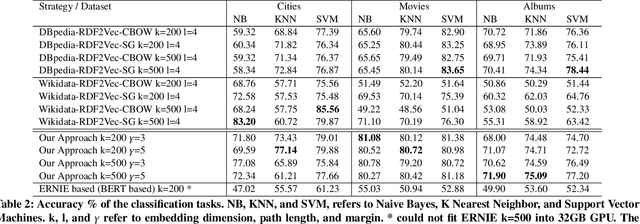
Knowledge is captured in the form of entities and their relationships and stored in knowledge graphs. Knowledge graphs enhance the capabilities of applications in many different areas including Web search, recommendation, and natural language understanding. This is mainly because, entities enable machines to understand things that go beyond simple tokens. Many modern algorithms use learned entity embeddings from these structured representations. However, building a knowledge graph takes time and effort, hence very costly and nontrivial. On the other hand, many Web sources describe entities in some structured format and therefore, finding ways to get them into useful entity knowledge is advantageous. We propose an approach that processes entity centric textual knowledge sources to learn entity embeddings and in turn avoids the need for a traditional knowledge graph. We first extract triples into the new representation format that does not use traditional complex triple extraction methods defined by pre-determined relationship labels. Then we learn entity embeddings through this new type of triples. We show that the embeddings learned from our approach are: (i) high quality and comparable to a known knowledge graph-based embeddings and can be used to improve them further, (ii) better than a contextual language model-based entity embeddings, and (iii) easy to compute and versatile in domain-specific applications where a knowledge graph is not readily available
A Complex KBQA System using Multiple Reasoning Paths
May 22, 2020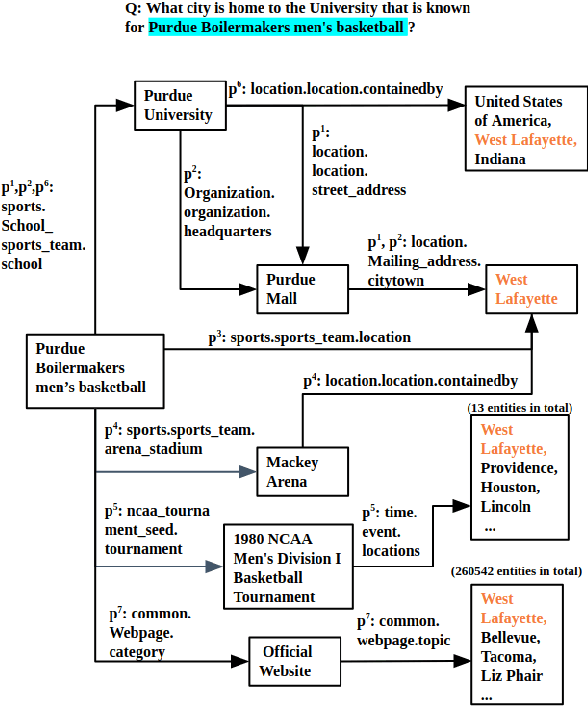
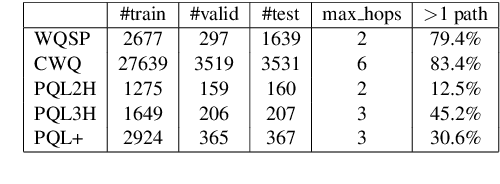
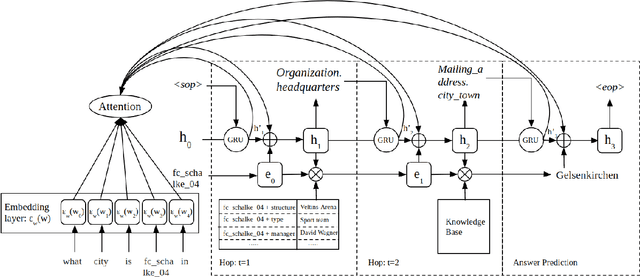
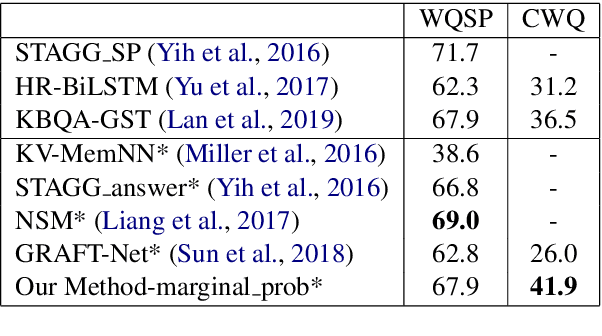
Multi-hop knowledge based question answering (KBQA) is a complex task for natural language understanding. Many KBQA approaches have been proposed in recent years, and most of them are trained based on labeled reasoning path. This hinders the system's performance as many correct reasoning paths are not labeled as ground truth, and thus they cannot be learned. In this paper, we introduce an end-to-end KBQA system which can leverage multiple reasoning paths' information and only requires labeled answer as supervision. We conduct experiments on several benchmark datasets containing both single-hop simple questions as well as muti-hop complex questions, including WebQuestionSP (WQSP), ComplexWebQuestion-1.1 (CWQ), and PathQuestion-Large (PQL), and demonstrate strong performance.
Neural Entity Summarization with Joint Encoding and Weak Supervision
May 10, 2020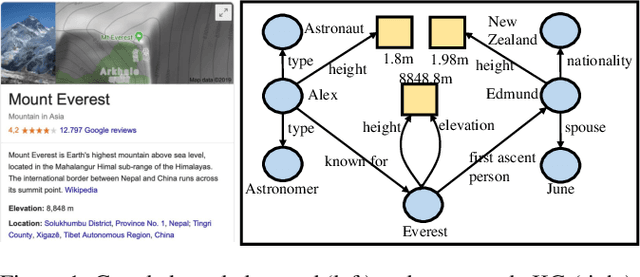

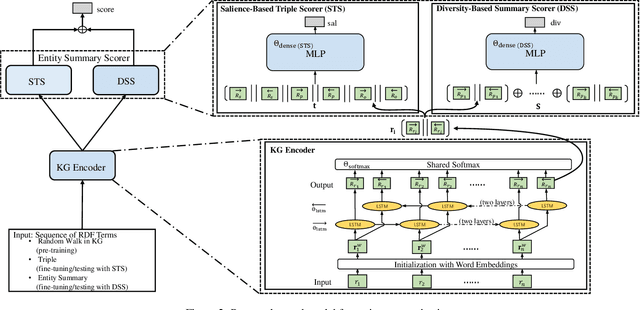
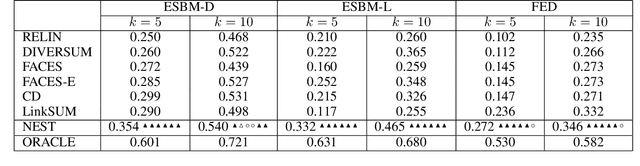
In a large-scale knowledge graph (KG), an entity is often described by a large number of triple-structured facts. Many applications require abridged versions of entity descriptions, called entity summaries. Existing solutions to entity summarization are mainly unsupervised. In this paper, we present a supervised approach NEST that is based on our novel neural model to jointly encode graph structure and text in KGs and generate high-quality diversified summaries. Since it is costly to obtain manually labeled summaries for training, our supervision is weak as we train with programmatically labeled data which may contain noise but is free of manual work. Evaluation results show that our approach significantly outperforms the state of the art on two public benchmarks.