 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation
Dec 24, 2024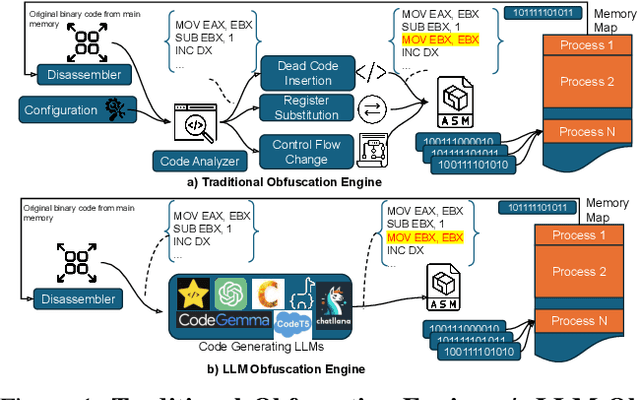


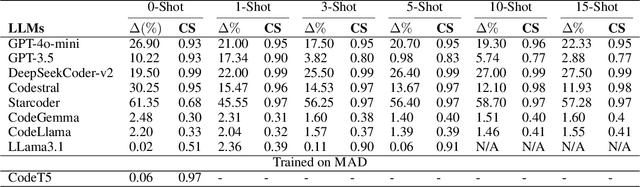
Malware authors often employ code obfuscations to make their malware harder to detect. Existing tools for generating obfuscated code often require access to the original source code (e.g., C++ or Java), and adding new obfuscations is a non-trivial, labor-intensive process. In this study, we ask the following question: Can Large Language Models (LLMs) potentially generate a new obfuscated assembly code? If so, this poses a risk to anti-virus engines and potentially increases the flexibility of attackers to create new obfuscation patterns. We answer this in the affirmative by developing the MetamorphASM benchmark comprising MetamorphASM Dataset (MAD) along with three code obfuscation techniques: dead code, register substitution, and control flow change. The MetamorphASM systematically evaluates the ability of LLMs to generate and analyze obfuscated code using MAD, which contains 328,200 obfuscated assembly code samples. We release this dataset and analyze the success rate of various LLMs (e.g., GPT-3.5/4, GPT-4o-mini, Starcoder, CodeGemma, CodeLlama, CodeT5, and LLaMA 3.1) in generating obfuscated assembly code. The evaluation was performed using established information-theoretic metrics and manual human review to ensure correctness and provide the foundation for researchers to study and develop remediations to this risk. The source code can be found at the following GitHub link: https://github.com/mohammadi-ali/MetamorphASM.
Benchmarking Deep Jansen-Rit Parameter Inference: An in Silico Study
Jun 07, 2024
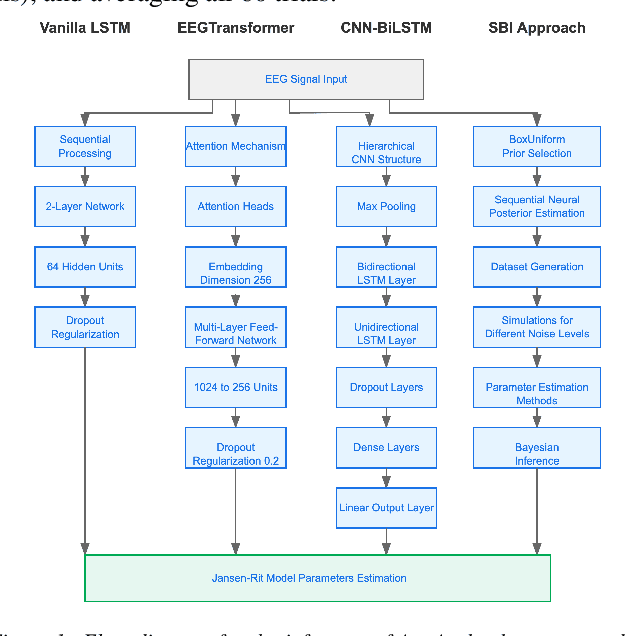


The study of effective connectivity (EC) is essential in understanding how the brain integrates and responds to various sensory inputs. Model-driven estimation of EC is a powerful approach that requires estimating global and local parameters of a generative model of neural activity. Insights gathered through this process can be used in various applications, such as studying neurodevelopmental disorders. However, accurately determining EC through generative models remains a significant challenge due to the complexity of brain dynamics and the inherent noise in neural recordings, e.g., in electroencephalography (EEG). Current model-driven methods to study EC are computationally complex and cannot scale to all brain regions as required by whole-brain analyses. To facilitate EC assessment, an inference algorithm must exhibit reliable prediction of parameters in the presence of noise. Further, the relationship between the model parameters and the neural recordings must be learnable. To progress toward these objectives, we benchmarked the performance of a Bi-LSTM model for parameter inference from the Jansen-Rit neural mass model (JR-NMM) simulated EEG under various noise conditions. Additionally, our study explores how the JR-NMM reacts to changes in key biological parameters (i.e., sensitivity analysis) like synaptic gains and time constants, a crucial step in understanding the connection between neural mechanisms and observed brain activity. Our results indicate that we can predict the local JR-NMM parameters from EEG, supporting the feasibility of our deep-learning-based inference approach. In future work, we plan to extend this framework to estimate local and global parameters from real EEG in clinically relevant applications.
REASONS: A benchmark for REtrieval and Automated citationS Of scieNtific Sentences using Public and Proprietary LLMs
May 03, 2024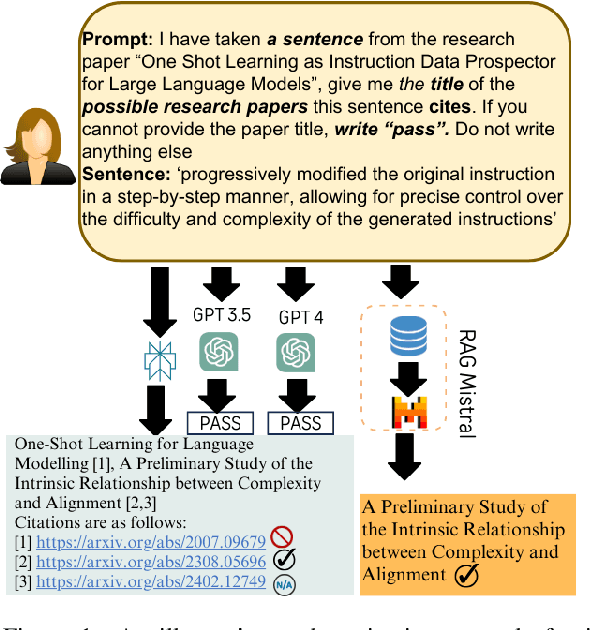
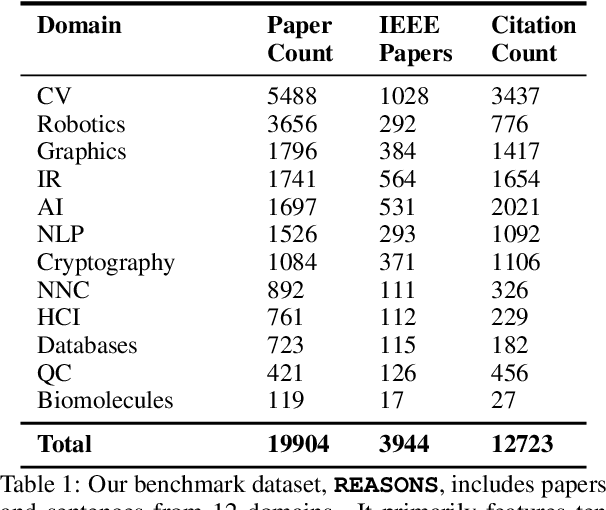
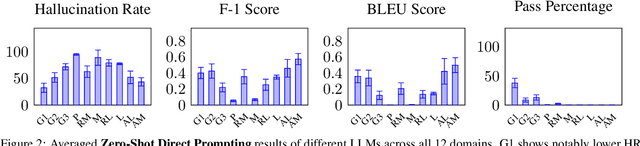
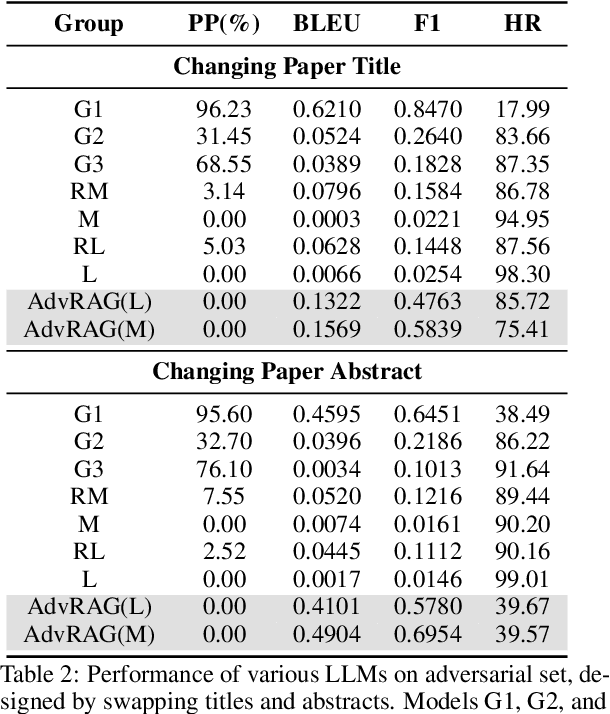
Automatic citation generation for sentences in a document or report is paramount for intelligence analysts, cybersecurity, news agencies, and education personnel. In this research, we investigate whether large language models (LLMs) are capable of generating references based on two forms of sentence queries: (a) Direct Queries, LLMs are asked to provide author names of the given research article, and (b) Indirect Queries, LLMs are asked to provide the title of a mentioned article when given a sentence from a different article. To demonstrate where LLM stands in this task, we introduce a large dataset called REASONS comprising abstracts of the 12 most popular domains of scientific research on arXiv. From around 20K research articles, we make the following deductions on public and proprietary LLMs: (a) State-of-the-art, often called anthropomorphic GPT-4 and GPT-3.5, suffers from high pass percentage (PP) to minimize the hallucination rate (HR). When tested with Perplexity.ai (7B), they unexpectedly made more errors; (b) Augmenting relevant metadata lowered the PP and gave the lowest HR; (c) Advance retrieval-augmented generation (RAG) using Mistral demonstrates consistent and robust citation support on indirect queries and matched performance to GPT-3.5 and GPT-4. The HR across all domains and models decreased by an average of 41.93% and the PP was reduced to 0% in most cases. In terms of generation quality, the average F1 Score and BLEU were 68.09% and 57.51%, respectively; (d) Testing with adversarial samples showed that LLMs, including the Advance RAG Mistral, struggle to understand context, but the extent of this issue was small in Mistral and GPT-4-Preview. Our study con tributes valuable insights into the reliability of RAG for automated citation generation tasks.
A Cross Attention Approach to Diagnostic Explainability using Clinical Practice Guidelines for Depression
Nov 23, 2023

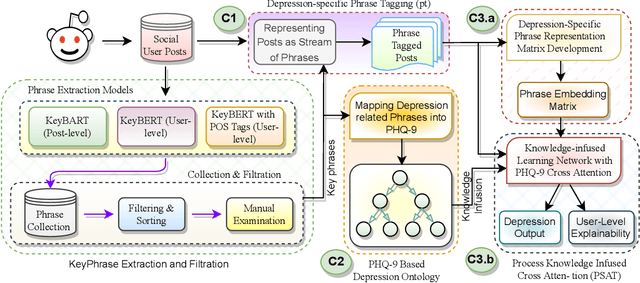
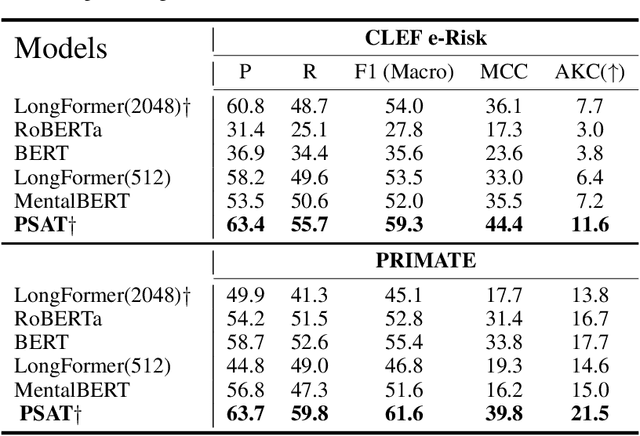
The lack of explainability using relevant clinical knowledge hinders the adoption of Artificial Intelligence-powered analysis of unstructured clinical dialogue. A wealth of relevant, untapped Mental Health (MH) data is available in online communities, providing the opportunity to address the explainability problem with substantial potential impact as a screening tool for both online and offline applications. We develop a method to enhance attention in popular transformer models and generate clinician-understandable explanations for classification by incorporating external clinical knowledge. Inspired by how clinicians rely on their expertise when interacting with patients, we leverage relevant clinical knowledge to model patient inputs, providing meaningful explanations for classification. This will save manual review time and engender trust. We develop such a system in the context of MH using clinical practice guidelines (CPG) for diagnosing depression, a mental health disorder of global concern. We propose an application-specific language model called ProcesS knowledge-infused cross ATtention (PSAT), which incorporates CPGs when computing attention. Through rigorous evaluation on three expert-curated datasets related to depression, we demonstrate application-relevant explainability of PSAT. PSAT also surpasses the performance of nine baseline models and can provide explanations where other baselines fall short. We transform a CPG resource focused on depression, such as the Patient Health Questionnaire (e.g. PHQ-9) and related questions, into a machine-readable ontology using SNOMED-CT. With this resource, PSAT enhances the ability of models like GPT-3.5 to generate application-relevant explanations.