 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Knowledge-Infusion For Explainable Depression Detection
Sep 01, 2024



Discovering individuals depression on social media has become increasingly important. Researchers employed ML/DL or lexicon-based methods for automated depression detection. Lexicon based methods, explainable and easy to implement, match words from user posts in a depression dictionary without considering contexts. While the DL models can leverage contextual information, their black-box nature limits their adoption in the domain. Though surrogate models like LIME and SHAP can produce explanations for DL models, the explanations are suitable for the developer and of limited use to the end user. We propose a Knolwedge-infused Neural Network (KiNN) incorporating domain-specific knowledge from DepressionFeature ontology (DFO) in a neural network to endow the model with user-level explainability regarding concepts and processes the clinician understands. Further, commonsense knowledge from the Commonsense Transformer (COMET) trained on ATOMIC is also infused to consider the generic emotional aspects of user posts in depression detection. The model is evaluated on three expertly curated datasets related to depression. We observed the model to have a statistically significant (p<0.1) boost in performance over the best domain-specific model, MentalBERT, across CLEF e-Risk (25% MCC increase, 12% F1 increase). A similar trend is observed across the PRIMATE dataset, where the proposed model performed better than MentalBERT (2.5% MCC increase, 19% F1 increase). The observations confirm the generated explanations to be informative for MHPs compared to post hoc model explanations. Results demonstrated that the user-level explainability of KiNN also surpasses the performance of baseline models and can provide explanations where other baselines fall short. Infusing the domain and commonsense knowledge in KiNN enhances the ability of models like GPT-3.5 to generate application-relevant explanations.
A Cross Attention Approach to Diagnostic Explainability using Clinical Practice Guidelines for Depression
Nov 23, 2023

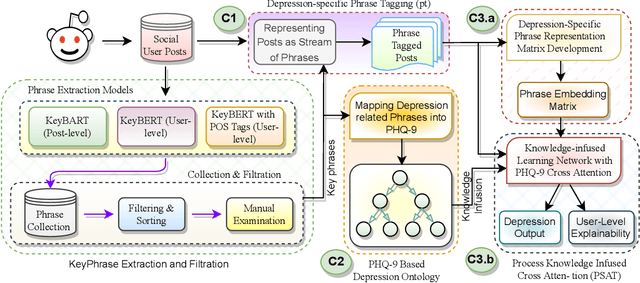
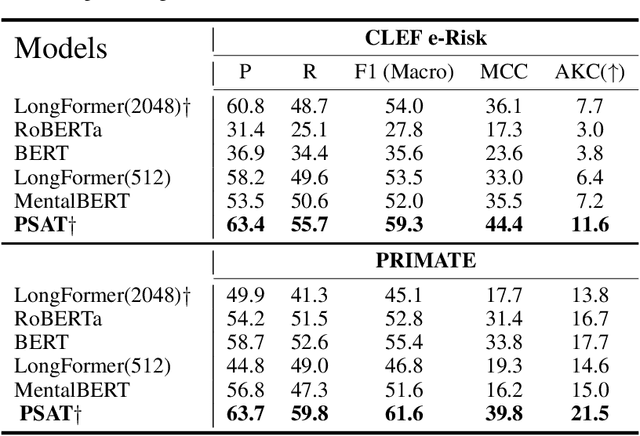
The lack of explainability using relevant clinical knowledge hinders the adoption of Artificial Intelligence-powered analysis of unstructured clinical dialogue. A wealth of relevant, untapped Mental Health (MH) data is available in online communities, providing the opportunity to address the explainability problem with substantial potential impact as a screening tool for both online and offline applications. We develop a method to enhance attention in popular transformer models and generate clinician-understandable explanations for classification by incorporating external clinical knowledge. Inspired by how clinicians rely on their expertise when interacting with patients, we leverage relevant clinical knowledge to model patient inputs, providing meaningful explanations for classification. This will save manual review time and engender trust. We develop such a system in the context of MH using clinical practice guidelines (CPG) for diagnosing depression, a mental health disorder of global concern. We propose an application-specific language model called ProcesS knowledge-infused cross ATtention (PSAT), which incorporates CPGs when computing attention. Through rigorous evaluation on three expert-curated datasets related to depression, we demonstrate application-relevant explainability of PSAT. PSAT also surpasses the performance of nine baseline models and can provide explanations where other baselines fall short. We transform a CPG resource focused on depression, such as the Patient Health Questionnaire (e.g. PHQ-9) and related questions, into a machine-readable ontology using SNOMED-CT. With this resource, PSAT enhances the ability of models like GPT-3.5 to generate application-relevant explanations.
Comprehensive Review on Semantic Information Retrieval and Ontology Engineering
Jul 25, 2023Situation awareness is a crucial cognitive skill that enables individuals to perceive, comprehend, and project the current state of their environment accurately. It involves being conscious of relevant information, understanding its meaning, and using that understanding to make well-informed decisions. Awareness systems often need to integrate new knowledge and adapt to changing environments. Ontology reasoning facilitates knowledge integration and evolution, allowing for seamless updates and expansions of the ontology. With the consideration of above, we are providing a quick review on semantic information retrieval and ontology engineering to understand the emerging challenges and future research. In the review we have found that the ontology reasoning addresses the limitations of traditional systems by providing a formal, flexible, and scalable framework for knowledge representation, reasoning, and inference.
InBiodiv-O: An Ontology for Indian Biodiversity Knowledge Management
Aug 20, 2021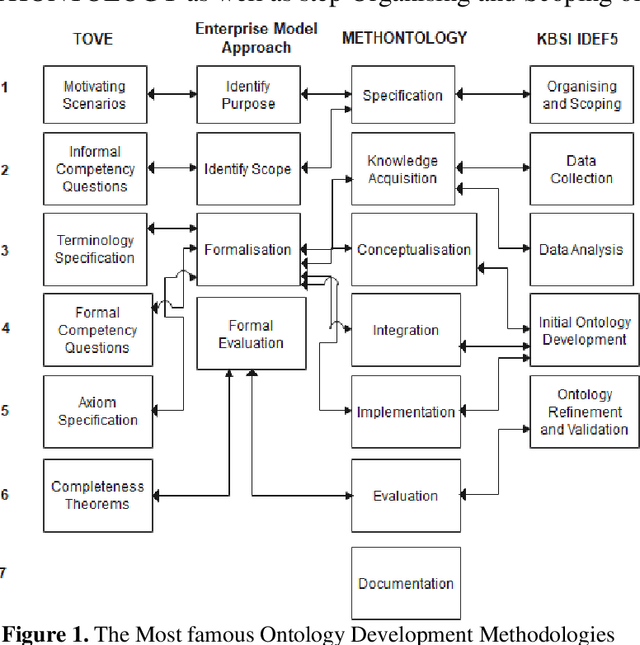
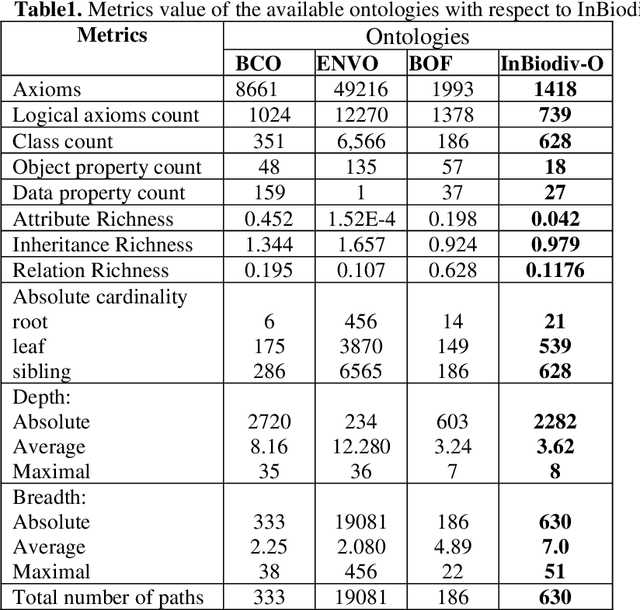
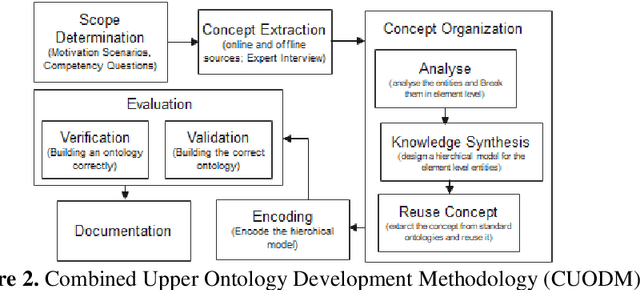
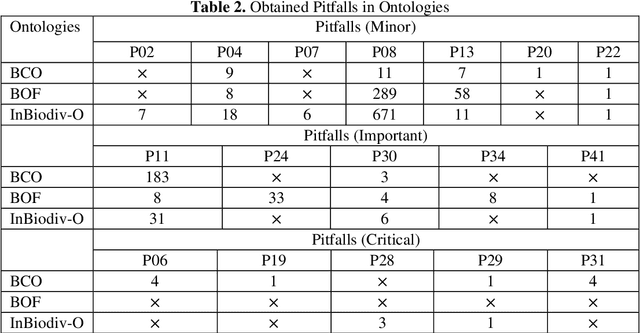
To present the biodiversity information, a semantic model is required that connects all kinds of data about living creatures and their habitats. The model must be able to encode human knowledge for machines to be understood. Ontology offers the richest machine-interpretable (rather than just machine-processable) and explicit semantics that are being extensively used in the biodiversity domain. Various ontologies are developed for the biodiversity domain however a review of the current landscape shows that these ontologies are not capable to define the Indian biodiversity information though India is one of the megadiverse countries. To semantically analyze the Indian biodiversity information, it is crucial to build an ontology that describes all the essential terms of this domain from the unstructured format of the data available on the web. Since, the curation of the ontologies heavily depends on the domain where these are implemented hence there is no ideal methodology is defined yet to be ready for universal use. The aim of this article is to develop an ontology that semantically encodes all the terms of Indian biodiversity information in all its dimensions based on the proposed methodology. The comprehensive evaluation of the proposed ontology depicts that ontology is well built in the specified domain.
Semantic Contextual Reasoning to Provide Human Behavior
Mar 19, 2021

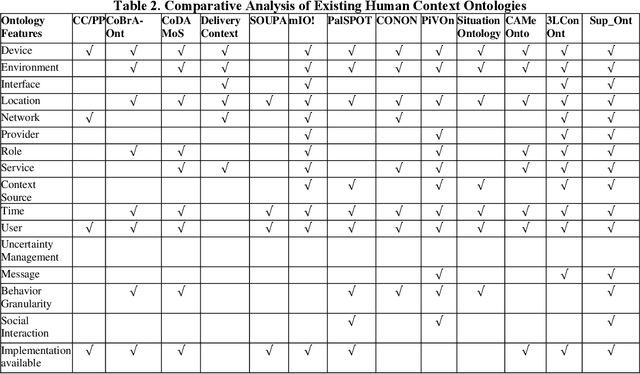
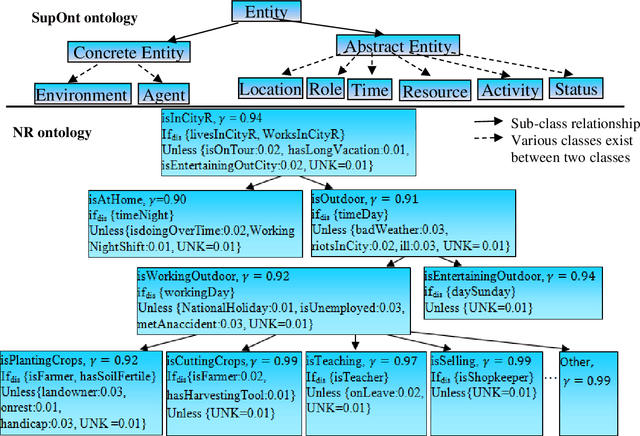
In recent years, the world has witnessed various primitives pertaining to the complexity of human behavior. Identifying an event in the presence of insufficient, incomplete, or tentative premises along with the constraints on resources such as time, data and memory is a vital aspect of an intelligent system. Data explosion presents one of the most challenging research issues for intelligent systems; to optimally represent and store this heterogeneous and voluminous data semantically to provide human behavior. There is a requirement of intelligent but personalized human behavior subject to constraints on resources and priority of the user. Knowledge, when represented in the form of an ontology, procures an intelligent response to a query posed by users; but it does not offer content in accordance with the user context. To this aim, we propose a model to quantify the user context and provide semantic contextual reasoning. A diagnostic belief algorithm (DBA) is also presented that identifies a given event and also computes the confidence of the decision as a function of available resources, premises, exceptions, and desired specificity. We conduct an empirical study in the domain of day-to-day routine queries and the experimental results show that the answer to queries and also its confidence varies with user context.
Exploiting Knowledge Graphs for Facilitating Product/Service Discovery
Oct 11, 2020


Most of the existing techniques to product discovery rely on syntactic approaches, thus ignoring valuable and specific semantic information of the underlying standards during the process. The product data comes from different heterogeneous sources and formats giving rise to the problem of interoperability. Above all, due to the continuously increasing influx of data, the manual labeling is getting costlier. Integrating the descriptions of different products into a single representation requires organizing all the products across vendors in a single taxonomy. Practically relevant and quality product categorization standards are still limited in number; and that too in academic research projects where we can majorly see only prototypes as compared to industry. This work presents a cost-effective solution for e-commerce on the Data Web by employing an unsupervised approach for data classification and exploiting the knowledge graphs for matching. The proposed architecture describes available products in web ontology language OWL and stores them in a triple store. User input specifications for certain products are matched against the available product categories to generate a knowledge graph. This mullti-phased top-down approach to develop and improve existing, if any, tailored product recommendations will be able to connect users with the exact product/service of their choice.