 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization with Robustness Certificates
Jan 26, 2023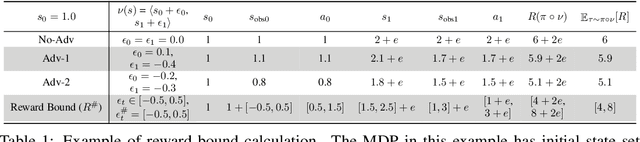
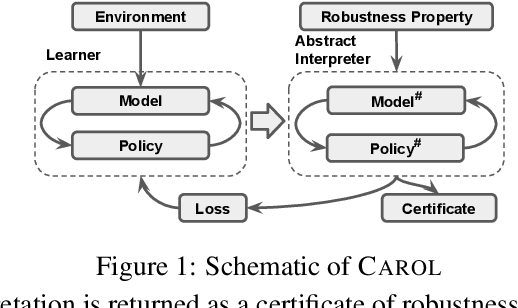
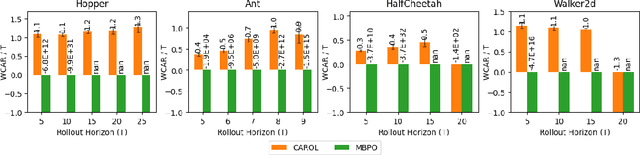
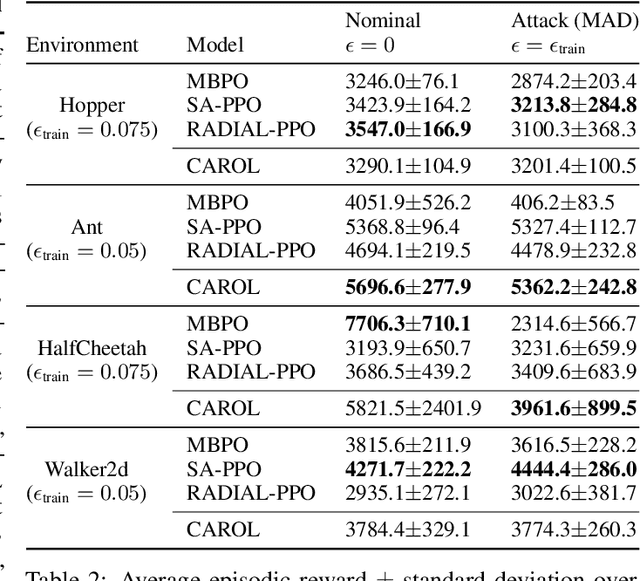
We present a policy optimization framework in which the learned policy comes with a machine-checkable certificate of adversarial robustness. Our approach, called CAROL, learns a model of the environment. In each learning iteration, it uses the current version of this model and an external abstract interpreter to construct a differentiable signal for provable robustness. This signal is used to guide policy learning, and the abstract interpretation used to construct it directly leads to the robustness certificate returned at convergence. We give a theoretical analysis that bounds the worst-case accumulative reward of CAROL. We also experimentally evaluate CAROL on four MuJoCo environments. On these tasks, which involve continuous state and action spaces, CAROL learns certified policies that have performance comparable to the (non-certified) policies learned using state-of-the-art robust RL methods.
Guiding Safe Exploration with Weakest Preconditions
Sep 28, 2022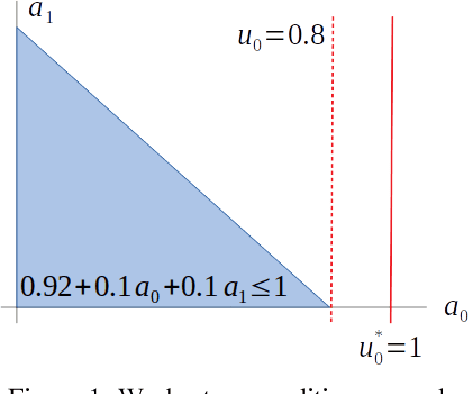
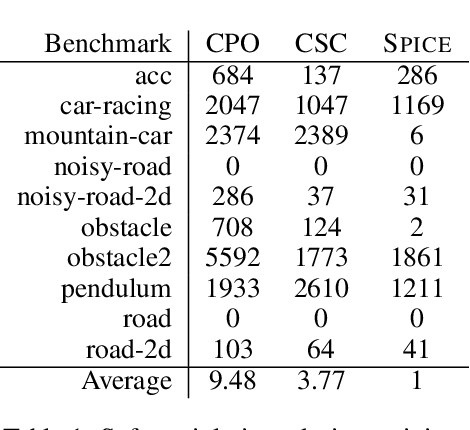
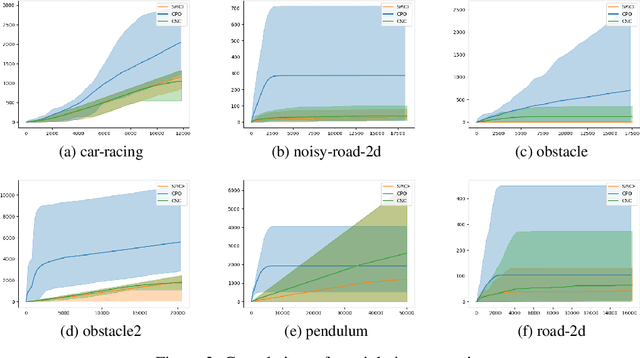
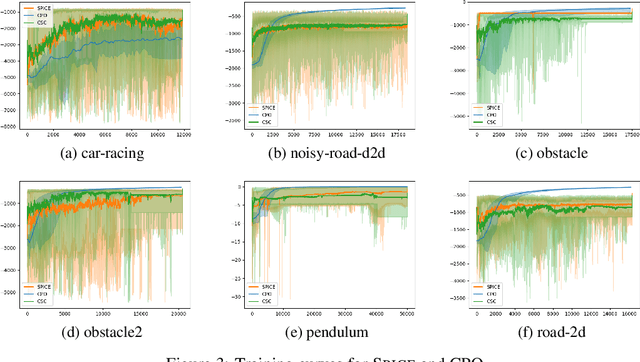
In reinforcement learning for safety-critical settings, it is often desirable for the agent to obey safety constraints at all points in time, including during training. We present a novel neurosymbolic approach called SPICE to solve this safe exploration problem. SPICE uses an online shielding layer based on symbolic weakest preconditions to achieve a more precise safety analysis than existing tools without unduly impacting the training process. We evaluate the approach on a suite of continuous control benchmarks and show that it can achieve comparable performance to existing safe learning techniques while incurring fewer safety violations. Additionally, we present theoretical results showing that SPICE converges to the optimal safe policy under reasonable assumptions.
Neurosymbolic Reinforcement Learning with Formally Verified Exploration
Oct 26, 2020
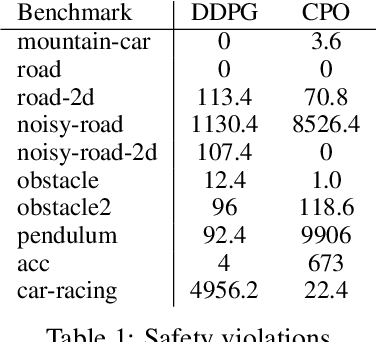
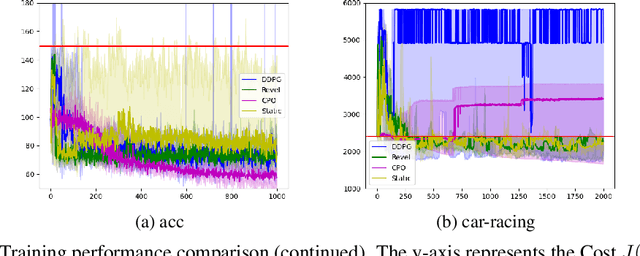
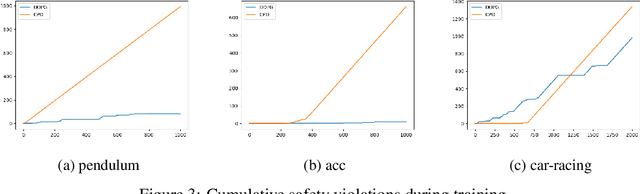
We present Revel, a partially neural reinforcement learning (RL) framework for provably safe exploration in continuous state and action spaces. A key challenge for provably safe deep RL is that repeatedly verifying neural networks within a learning loop is computationally infeasible. We address this challenge using two policy classes: a general, neurosymbolic class with approximate gradients and a more restricted class of symbolic policies that allows efficient verification. Our learning algorithm is a mirror descent over policies: in each iteration, it safely lifts a symbolic policy into the neurosymbolic space, performs safe gradient updates to the resulting policy, and projects the updated policy into the safe symbolic subset, all without requiring explicit verification of neural networks. Our empirical results show that Revel enforces safe exploration in many scenarios in which Constrained Policy Optimization does not, and that it can discover policies that outperform those learned through prior approaches to verified exploration.
Optimization and Abstraction: A Synergistic Approach for Analyzing Neural Network Robustness
May 01, 2019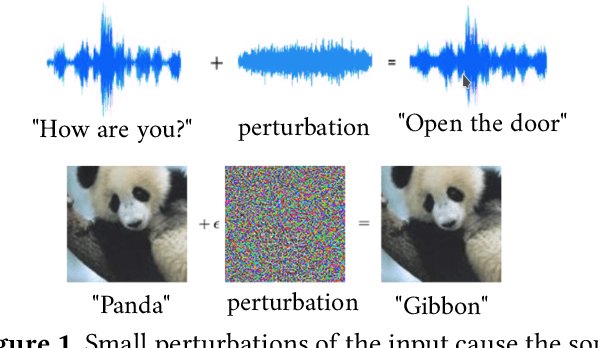
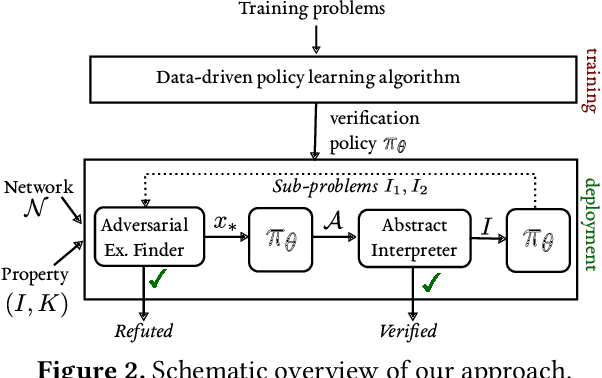
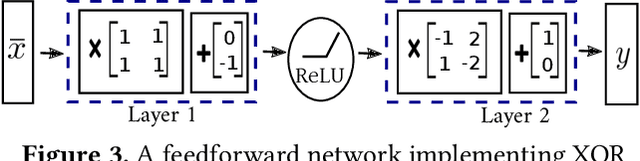
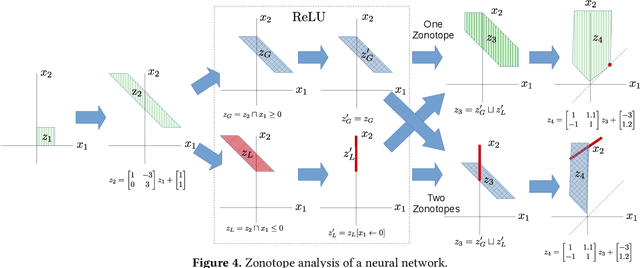
In recent years, the notion of local robustness (or robustness for short) has emerged as a desirable property of deep neural networks. Intuitively, robustness means that small perturbations to an input do not cause the network to perform misclassifications. In this paper, we present a novel algorithm for verifying robustness properties of neural networks. Our method synergistically combines gradient-based optimization methods for counterexample search with abstraction-based proof search to obtain a sound and ({\delta}-)complete decision procedure. Our method also employs a data-driven approach to learn a verification policy that guides abstract interpretation during proof search. We have implemented the proposed approach in a tool called Charon and experimentally evaluated it on hundreds of benchmarks. Our experiments show that the proposed approach significantly outperforms three state-of-the-art tools, namely AI^2 , Reluplex, and Reluval.