 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Language Communication for Cooperative Autonomous Driving via Self-Play
May 23, 2025



Past work has demonstrated that autonomous vehicles can drive more safely if they communicate with one another than if they do not. However, their communication has often not been human-understandable. Using natural language as a vehicle-to-vehicle (V2V) communication protocol offers the potential for autonomous vehicles to drive cooperatively not only with each other but also with human drivers. In this work, we propose a suite of traffic tasks in autonomous driving where vehicles in a traffic scenario need to communicate in natural language to facilitate coordination in order to avoid an imminent collision and/or support efficient traffic flow. To this end, this paper introduces a novel method, LLM+Debrief, to learn a message generation and high-level decision-making policy for autonomous vehicles through multi-agent discussion. To evaluate LLM agents for driving, we developed a gym-like simulation environment that contains a range of driving scenarios. Our experimental results demonstrate that LLM+Debrief is more effective at generating meaningful and human-understandable natural language messages to facilitate cooperation and coordination than a zero-shot LLM agent. Our code and demo videos are available at https://talking-vehicles.github.io/.
SOCIALGYM 2.0: Simulator for Multi-Agent Social Robot Navigation in Shared Human Spaces
Mar 09, 2023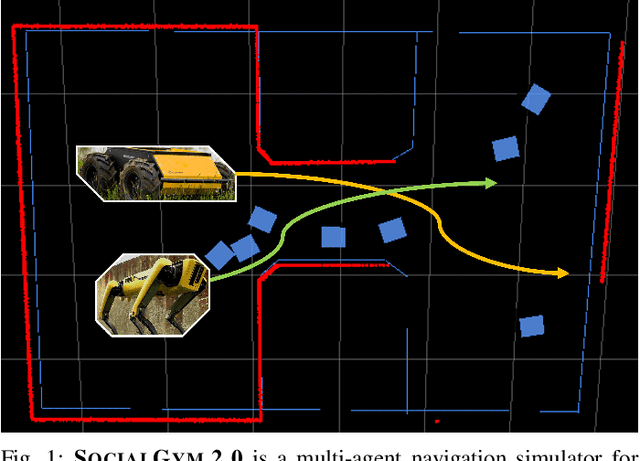
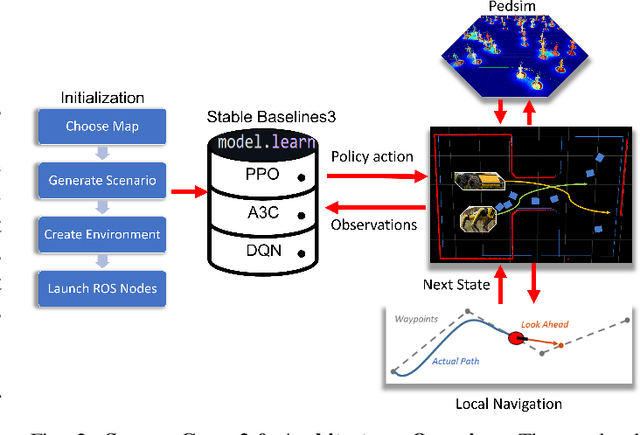
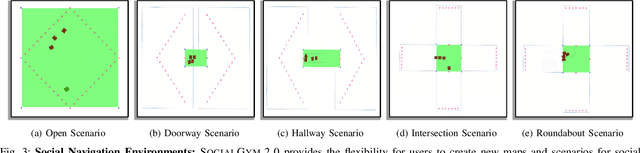
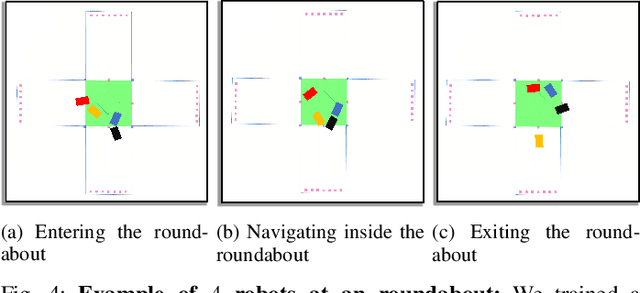
We present SocialGym 2, a multi-agent navigation simulator for social robot research. Our simulator models multiple autonomous agents, replicating real-world dynamics in complex environments, including doorways, hallways, intersections, and roundabouts. Unlike traditional simulators that concentrate on single robots with basic kinematic constraints in open spaces, SocialGym 2 employs multi-agent reinforcement learning (MARL) to develop optimal navigation policies for multiple robots with diverse, dynamic constraints in complex environments. Built on the PettingZoo MARL library and Stable Baselines3 API, SocialGym 2 offers an accessible python interface that integrates with a navigation stack through ROS messaging. SocialGym 2 can be easily installed and is packaged in a docker container, and it provides the capability to swap and evaluate different MARL algorithms, as well as customize observation and reward functions. We also provide scripts to allow users to create their own environments and have conducted benchmarks using various social navigation algorithms, reporting a broad range of social navigation metrics. Projected hosted at: https://amrl.cs.utexas.edu/social_gym/index.html
PLUNDER: Probabilistic Program Synthesis for Learning from Unlabeled and Noisy Demonstrations
Mar 02, 2023


Learning from demonstration (LfD) is a widely researched paradigm for teaching robots to perform novel tasks. LfD works particularly well with program synthesis since the resulting programmatic policy is data efficient, interpretable, and amenable to formal verification. However, existing synthesis approaches to LfD rely on precise and labeled demonstrations and are incapable of reasoning about the uncertainty inherent in human decision-making. In this paper, we propose PLUNDER, a new LfD approach that integrates a probabilistic program synthesizer in an expectation-maximization (EM) loop to overcome these limitations. PLUNDER only requires unlabeled low-level demonstrations of the intended task (e.g., remote-controlled motion trajectories), which liberates end-users from providing explicit labels and facilitates a more intuitive LfD experience. PLUNDER also generates a probabilistic policy that captures actuation errors and the uncertainties inherent in human decision making. Our experiments compare PLUNDER with state-of the-art LfD techniques and demonstrate its advantages across different robotic tasks.
STEADY: Simultaneous State Estimation and Dynamics Learning from Indirect Observations
Mar 02, 2022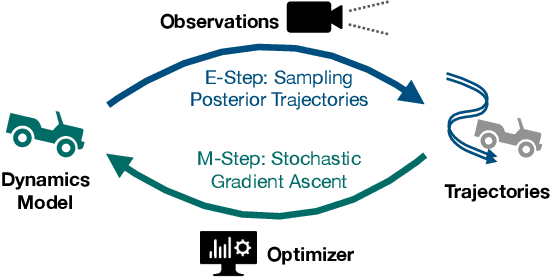
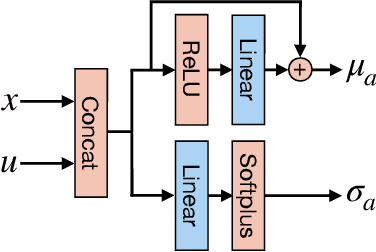
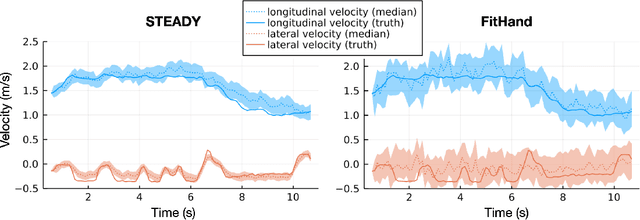
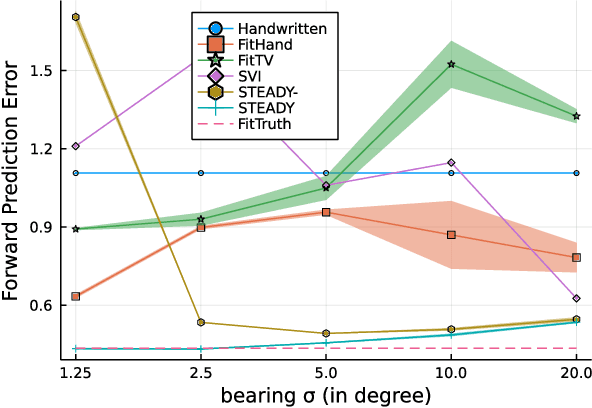
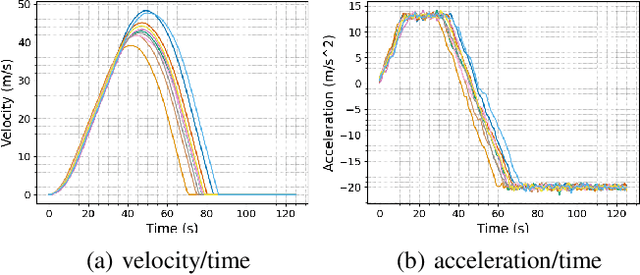
Accurate kinodynamic models play a crucial role in many robotics applications such as off-road navigation and high-speed driving. Many state-of-the-art approaches in learning stochastic kinodynamic models, however, require precise measurements of robot states as labeled input/output examples, which can be hard to obtain in outdoor settings due to limited sensor capabilities and the absence of ground truth. In this work, we propose a new technique for learning neural stochastic kinodynamic models from noisy and indirect observations by performing simultaneous state estimation and dynamics learning. The proposed technique iteratively improves the kinodynamic model in an expectation-maximization loop, where the E Step samples posterior state trajectories using particle filtering, and the M Step updates the dynamics to be more consistent with the sampled trajectories via stochastic gradient ascent. We evaluate our approach on both simulation and real-world benchmarks and compare it with several baseline techniques. Our approach not only achieves significantly higher accuracy but is also more robust to observation noise, thereby showing promise for boosting the performance of many other robotics applications.
SOCIALGYM: A Framework for Benchmarking Social Robot Navigation
Sep 22, 2021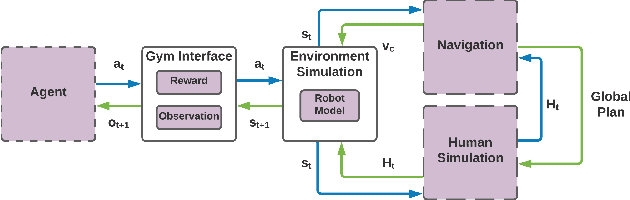
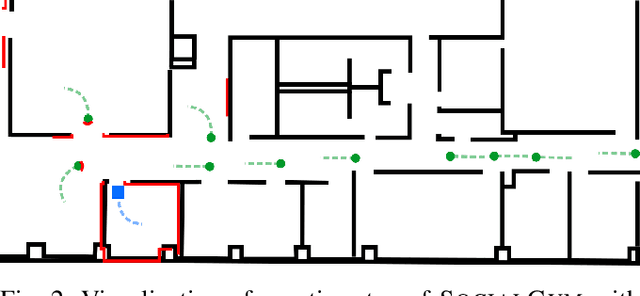
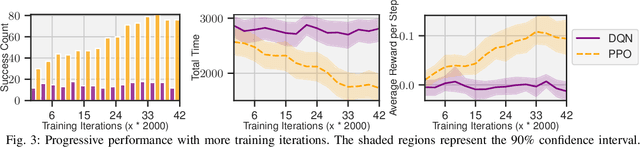
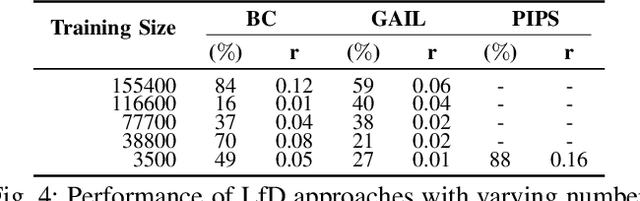
Robots moving safely and in a socially compliant manner in dynamic human environments is an essential benchmark for long-term robot autonomy. However, it is not feasible to learn and benchmark social navigation behaviors entirely in the real world, as learning is data-intensive, and it is challenging to make safety guarantees during training. Therefore, simulation-based benchmarks that provide abstractions for social navigation are required. A framework for these benchmarks would need to support a wide variety of learning approaches, be extensible to the broad range of social navigation scenarios, and abstract away the perception problem to focus on social navigation explicitly. While there have been many proposed solutions, including high fidelity 3D simulators and grid world approximations, no existing solution satisfies all of the aforementioned properties for learning and evaluating social navigation behaviors. In this work, we propose SOCIALGYM, a lightweight 2D simulation environment for robot social navigation designed with extensibility in mind, and a benchmark scenario built on SOCIALGYM. Further, we present benchmark results that compare and contrast human-engineered and model-based learning approaches to a suite of off-the-shelf Learning from Demonstration (LfD) and Reinforcement Learning (RL) approaches applied to social robot navigation. These results demonstrate the data efficiency, task performance, social compliance, and environment transfer capabilities for each of the policies evaluated to provide a solid grounding for future social navigation research.
Iterative Program Synthesis for Adaptable Social Navigation
Mar 08, 2021

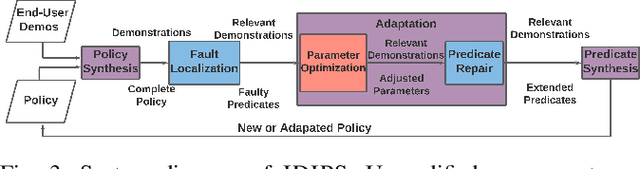

Robot social navigation is influenced by human preferences and environment-specific scenarios such as elevators and doors, thus necessitating end-user adaptability. State-of-the-art approaches to social navigation fall into two categories: model-based social constraints and learning-based approaches. While effective, these approaches have fundamental limitations -- model-based approaches require constraint and parameter tuning to adapt to preferences and new scenarios, while learning-based approaches require reward functions, significant training data, and are hard to adapt to new social scenarios or new domains with limited demonstrations. In this work, we propose Iterative Dimension Informed Program Synthesis (IDIPS) to address these limitations by learning and adapting social navigation in the form of human-readable symbolic programs. IDIPS works by combining program synthesis, parameter optimization, predicate repair, and iterative human demonstration to learn and adapt model-free action selection policies from orders of magnitude less data than learning-based approaches. We introduce a novel predicate repair technique that can accommodate previously unseen social scenarios or preferences by growing existing policies. We present experimental results showing that IDIPS: 1) synthesizes effective policies that model user preference, 2) can adapt existing policies to changing preferences, 3) can extend policies to handle novel social scenarios such as locked doors, and 4) generates policies that can be transferred from simulation to real-world robots with minimal effort.
Robot Action Selection Learning via Layered Dimension Informed Program Synthesis
Aug 10, 2020

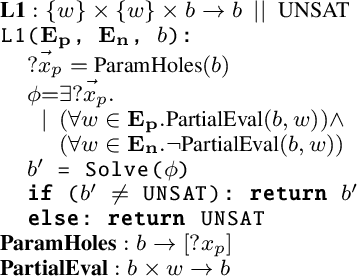

Action selection policies (ASPs), used to compose low-level robot skills into complex high-level tasks are commonly represented as neural networks (NNs) in the state of the art. Such a paradigm, while very effective, suffers from a few key problems: 1) NNs are opaque to the user and hence not amenable to verification, 2) they require significant amounts of training data, and 3) they are hard to repair when the domain changes. We present two key insights about ASPs for robotics. First, ASPs need to reason about physically meaningful quantities derived from the state of the world, and second, there exists a layered structure for composing these policies. Leveraging these insights, we introduce layered dimension-informed program synthesis (LDIPS) - by reasoning about the physical dimensions of state variables, and dimensional constraints on operators, LDIPS directly synthesizes ASPs in a human-interpretable domain-specific language that is amenable to program repair. We present empirical results to demonstrate that LDIPS 1) can synthesize effective ASPs for robot soccer and autonomous driving domains, 2) requires two orders of magnitude fewer training examples than a comparable NN representation, and 3) can repair the synthesized ASPs with only a small number of corrections when transferring from simulation to real robots.
SMT-based Robot Transition Repair
Jan 09, 2020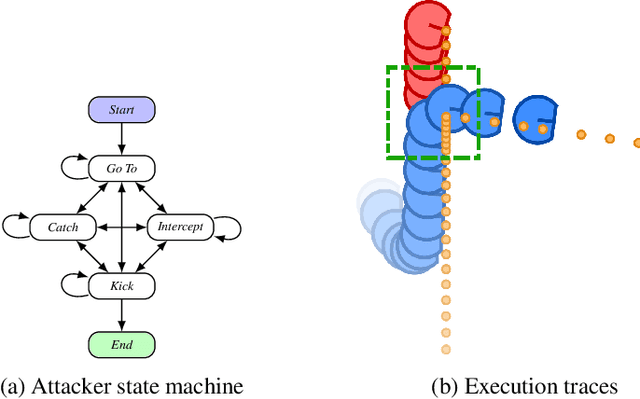

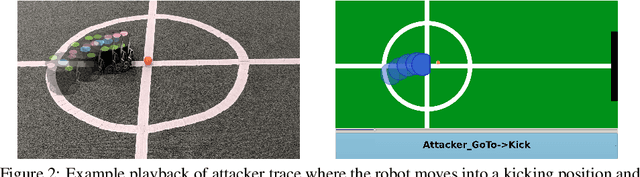
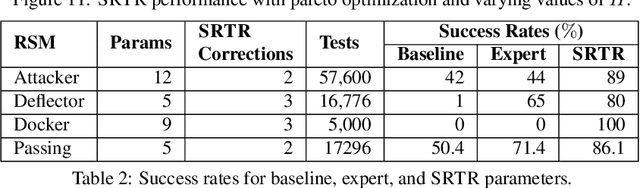
State machines are a common model for robot behaviors. Transition functions often rely on parameterized conditions to model preconditions for the controllers, where the correct values of the parameters depend on factors relating to the environment or the specific robot. In the absence of specific calibration procedures a roboticist must painstakingly adjust the parameters through a series of trial and error experiments. In this process, identifying when the robot has taken an incorrect action, and what should be done is straightforward, but finding the right parameter values can be difficult. We present an alternative approach that we call, interactive SMT-based Robot Transition Repair. During execution we record an execution trace of the transition function, and we ask the roboticist to identify a few instances where the robot has transitioned incorrectly, and what the correct transition should have been. A user supplies these corrections based on the type of error to repair, and an automated analysis of the traces partially evaluates the transition function for each correction. This system of constraints is then formulated as a MaxSMT problem, where the solution is a minimal adjustment to the parameters that satisfies the maximum number of constraints. In order to identify a repair that accurately captures user intentions and generalizes to novel scenarios, solutions are explored by iteratively adding constraints to the MaxSMT problem to yield sets of alternative repairs. We test with state machines from multiple domains including robot soccer and autonomous driving, and we evaluate solver based repair with respect to solver choice and optimization hyperparameters. Our results demonstrate that SRTR can repair a variety of states machines and error types 1) quickly, 2) with small numbers of corrections, while 3) not overcorrecting state machines and harming generalized performance.
Interactive Robot Transition Repair With SMT
May 05, 2018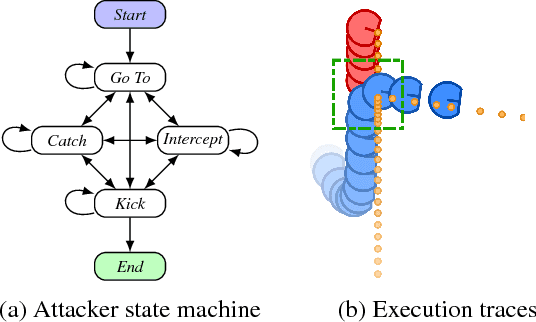
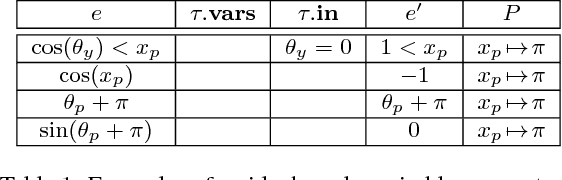


Complex robot behaviors are often structured as state machines, where states encapsulate actions and a transition function switches between states. Since transitions depend on physical parameters, when the environment changes, a roboticist has to painstakingly readjust the parameters to work in the new environment. We present interactive SMT-based Robot Transition Repair (SRTR): instead of manually adjusting parameters, we ask the roboticist to identify a few instances where the robot is in a wrong state and what the right state should be. A lightweight automated analysis of the transition function's source code then 1) identifies adjustable parameters, 2) converts the transition function into a system of logical constraints, and 3) formulates the constraints and user-supplied corrections as MaxSMT problem that yields new parameter values. Our evaluation shows that SRTR is effective on real robots and in simulation. We show that SRTR finds new parameters 1) quickly, 2) with only a few corrections, and 3) that the parameters generalize to new scenarios. We also show that a simple state machine corrected by SRTR can out-perform a more complex, expert-tuned state machine in the real world.