 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Action Selection Learning via Layered Dimension Informed Program Synthesis
Paper and Code
Aug 10, 2020

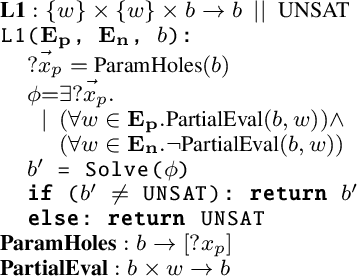

Action selection policies (ASPs), used to compose low-level robot skills into complex high-level tasks are commonly represented as neural networks (NNs) in the state of the art. Such a paradigm, while very effective, suffers from a few key problems: 1) NNs are opaque to the user and hence not amenable to verification, 2) they require significant amounts of training data, and 3) they are hard to repair when the domain changes. We present two key insights about ASPs for robotics. First, ASPs need to reason about physically meaningful quantities derived from the state of the world, and second, there exists a layered structure for composing these policies. Leveraging these insights, we introduce layered dimension-informed program synthesis (LDIPS) - by reasoning about the physical dimensions of state variables, and dimensional constraints on operators, LDIPS directly synthesizes ASPs in a human-interpretable domain-specific language that is amenable to program repair. We present empirical results to demonstrate that LDIPS 1) can synthesize effective ASPs for robot soccer and autonomous driving domains, 2) requires two orders of magnitude fewer training examples than a comparable NN representation, and 3) can repair the synthesized ASPs with only a small number of corrections when transferring from simulation to real robots.