 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Program Synthesis for Adaptable Social Navigation
Mar 08, 2021

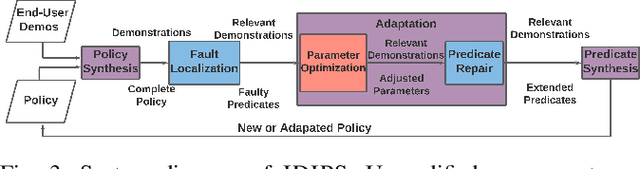

Robot social navigation is influenced by human preferences and environment-specific scenarios such as elevators and doors, thus necessitating end-user adaptability. State-of-the-art approaches to social navigation fall into two categories: model-based social constraints and learning-based approaches. While effective, these approaches have fundamental limitations -- model-based approaches require constraint and parameter tuning to adapt to preferences and new scenarios, while learning-based approaches require reward functions, significant training data, and are hard to adapt to new social scenarios or new domains with limited demonstrations. In this work, we propose Iterative Dimension Informed Program Synthesis (IDIPS) to address these limitations by learning and adapting social navigation in the form of human-readable symbolic programs. IDIPS works by combining program synthesis, parameter optimization, predicate repair, and iterative human demonstration to learn and adapt model-free action selection policies from orders of magnitude less data than learning-based approaches. We introduce a novel predicate repair technique that can accommodate previously unseen social scenarios or preferences by growing existing policies. We present experimental results showing that IDIPS: 1) synthesizes effective policies that model user preference, 2) can adapt existing policies to changing preferences, 3) can extend policies to handle novel social scenarios such as locked doors, and 4) generates policies that can be transferred from simulation to real-world robots with minimal effort.