 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-DETR: Towards Effective Video Moment Retrieval and Highlight Detection by Joint Motion-Semantic Learning
Jul 16, 2025Video Moment Retrieval (MR) and Highlight Detection (HD) aim to pinpoint specific moments and assess clip-wise relevance based on the text query. While DETR-based joint frameworks have made significant strides, there remains untapped potential in harnessing the intricate relationships between temporal motion and spatial semantics within video content. In this paper, we propose the Motion-Semantics DETR (MS-DETR), a framework that captures rich motion-semantics features through unified learning for MR/HD tasks. The encoder first explicitly models disentangled intra-modal correlations within motion and semantics dimensions, guided by the given text queries. Subsequently, the decoder utilizes the task-wise correlation across temporal motion and spatial semantics dimensions to enable precise query-guided localization for MR and refined highlight boundary delineation for HD. Furthermore, we observe the inherent sparsity dilemma within the motion and semantics dimensions of MR/HD datasets. To address this issue, we enrich the corpus from both dimensions by generation strategies and propose contrastive denoising learning to ensure the above components learn robustly and effectively. Extensive experiments on four MR/HD benchmarks demonstrate that our method outperforms existing state-of-the-art models by a margin. Our code is available at https://github.com/snailma0229/MS-DETR.git.
Rethinking Clothes Changing Person ReID: Conflicts, Synthesis, and Optimization
Apr 19, 2024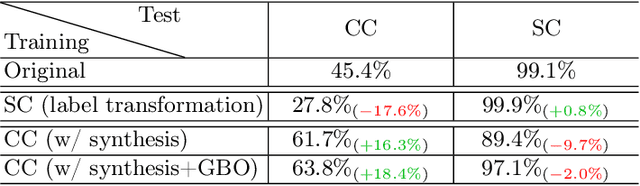



Clothes-changing person re-identification (CC-ReID) aims to retrieve images of the same person wearing different outfits. Mainstream researches focus on designing advanced model structures and strategies to capture identity information independent of clothing. However, the same-clothes discrimination as the standard ReID learning objective in CC-ReID is persistently ignored in previous researches. In this study, we dive into the relationship between standard and clothes-changing~(CC) learning objectives, and bring the inner conflicts between these two objectives to the fore. We try to magnify the proportion of CC training pairs by supplementing high-fidelity clothes-varying synthesis, produced by our proposed Clothes-Changing Diffusion model. By incorporating the synthetic images into CC-ReID model training, we observe a significant improvement under CC protocol. However, such improvement sacrifices the performance under the standard protocol, caused by the inner conflict between standard and CC. For conflict mitigation, we decouple these objectives and re-formulate CC-ReID learning as a multi-objective optimization (MOO) problem. By effectively regularizing the gradient curvature across multiple objectives and introducing preference restrictions, our MOO solution surpasses the single-task training paradigm. Our framework is model-agnostic, and demonstrates superior performance under both CC and standard ReID protocols.
Generalizable Person Search on Open-world User-Generated Video Content
Oct 16, 2023Person search is a challenging task that involves detecting and retrieving individuals from a large set of un-cropped scene images. Existing person search applications are mostly trained and deployed in the same-origin scenarios. However, collecting and annotating training samples for each scene is often difficult due to the limitation of resources and the labor cost. Moreover, large-scale intra-domain data for training are generally not legally available for common developers, due to the regulation of privacy and public security. Leveraging easily accessible large-scale User Generated Video Contents (\emph{i.e.} UGC videos) to train person search models can fit the open-world distribution, but still suffering a performance gap from the domain difference to surveillance scenes. In this work, we explore enhancing the out-of-domain generalization capabilities of person search models, and propose a generalizable framework on both feature-level and data-level generalization to facilitate downstream tasks in arbitrary scenarios. Specifically, we focus on learning domain-invariant representations for both detection and ReID by introducing a multi-task prototype-based domain-specific batch normalization, and a channel-wise ID-relevant feature decorrelation strategy. We also identify and address typical sources of noise in open-world training frames, including inaccurate bounding boxes, the omission of identity labels, and the absence of cross-camera data. Our framework achieves promising performance on two challenging person search benchmarks without using any human annotation or samples from the target domain.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Exploiting the Textual Potential from Vision-Language Pre-training for Text-based Person Search
Mar 08, 2023Text-based Person Search (TPS), is targeted on retrieving pedestrians to match text descriptions instead of query images. Recent Vision-Language Pre-training (VLP) models can bring transferable knowledge to downstream TPS tasks, resulting in more efficient performance gains. However, existing TPS methods improved by VLP only utilize pre-trained visual encoders, neglecting the corresponding textual representation and breaking the significant modality alignment learned from large-scale pre-training. In this paper, we explore the full utilization of textual potential from VLP in TPS tasks. We build on the proposed VLP-TPS baseline model, which is the first TPS model with both pre-trained modalities. We propose the Multi-Integrity Description Constraints (MIDC) to enhance the robustness of the textual modality by incorporating different components of fine-grained corpus during training. Inspired by the prompt approach for zero-shot classification with VLP models, we propose the Dynamic Attribute Prompt (DAP) to provide a unified corpus of fine-grained attributes as language hints for the image modality. Extensive experiments show that our proposed TPS framework achieves state-of-the-art performance, exceeding the previous best method by a margin.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Domain Adaptive Person Search
Jul 25, 2022

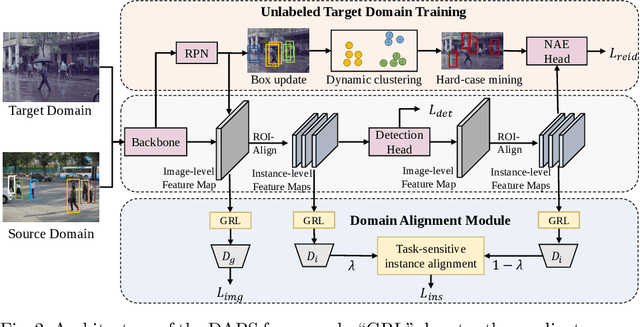

Person search is a challenging task which aims to achieve joint pedestrian detection and person re-identification (ReID). Previous works have made significant advances under fully and weakly supervised settings. However, existing methods ignore the generalization ability of the person search models. In this paper, we take a further step and present Domain Adaptive Person Search (DAPS), which aims to generalize the model from a labeled source domain to the unlabeled target domain. Two major challenges arises under this new setting: one is how to simultaneously solve the domain misalignment issue for both detection and Re-ID tasks, and the other is how to train the ReID subtask without reliable detection results on the target domain. To address these challenges, we propose a strong baseline framework with two dedicated designs. 1) We design a domain alignment module including image-level and task-sensitive instance-level alignments, to minimize the domain discrepancy. 2) We take full advantage of the unlabeled data with a dynamic clustering strategy, and employ pseudo bounding boxes to support ReID and detection training on the target domain. With the above designs, our framework achieves 34.7% in mAP and 80.6% in top-1 on PRW dataset, surpassing the direct transferring baseline by a large margin. Surprisingly, the performance of our unsupervised DAPS model even surpasses some of the fully and weakly supervised methods. The code is available at https://github.com/caposerenity/DAPS.
Receptive Multi-granularity Representation for Person Re-Identification
Aug 31, 2020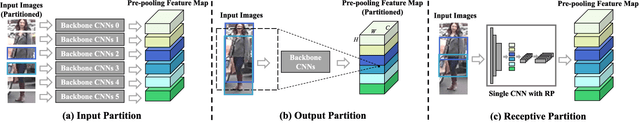
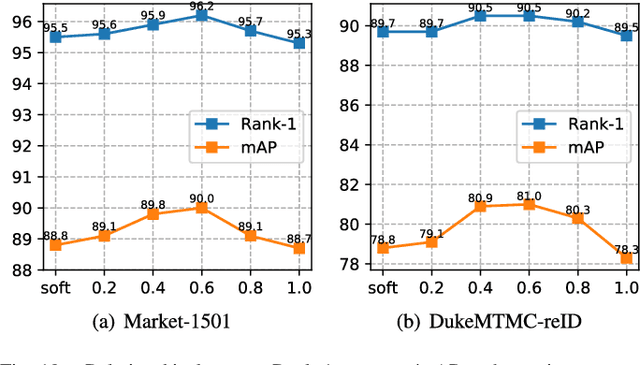
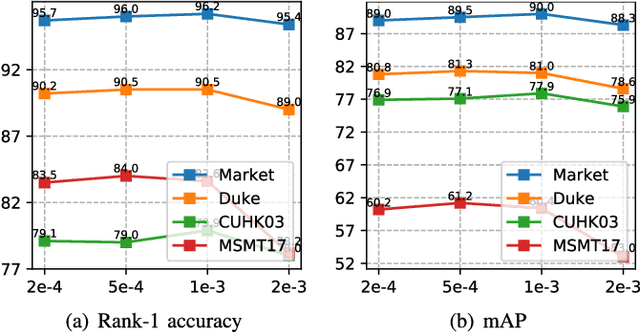
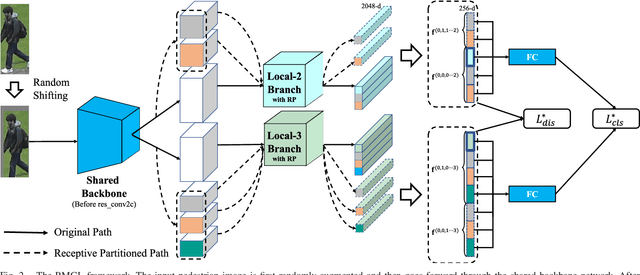
A key for person re-identification is achieving consistent local details for discriminative representation across variable environments. Current stripe-based feature learning approaches have delivered impressive accuracy, but do not make a proper trade-off between diversity, locality, and robustness, which easily suffers from part semantic inconsistency for the conflict between rigid partition and misalignment. This paper proposes a receptive multi-granularity learning approach to facilitate stripe-based feature learning. This approach performs local partition on the intermediate representations to operate receptive region ranges, rather than current approaches on input images or output features, thus can enhance the representation of locality while remaining proper local association. Toward this end, the local partitions are adaptively pooled by using significance-balanced activations for uniform stripes. Random shifting augmentation is further introduced for a higher variance of person appearing regions within bounding boxes to ease misalignment. By two-branch network architecture, different scales of discriminative identity representation can be learned. In this way, our model can provide a more comprehensive and efficient feature representation without larger model storage costs. Extensive experiments on intra-dataset and cross-dataset evaluations demonstrate the effectiveness of the proposed approach. Especially, our approach achieves a state-of-the-art accuracy of 96.2%@Rank-1 or 90.0%@mAP on the challenging Market-1501 benchmark.
* 14 pages, 9 figures. Championship solution of NAIC 2019 Person re-ID Track
Accurate Temporal Action Proposal Generation with Relation-Aware Pyramid Network
Mar 09, 2020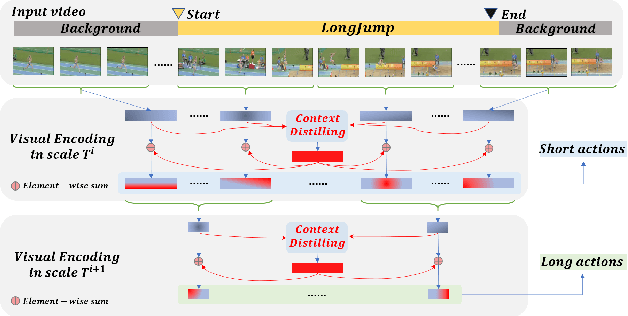
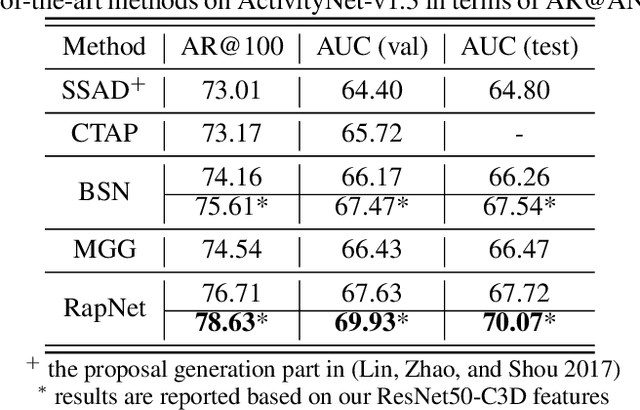
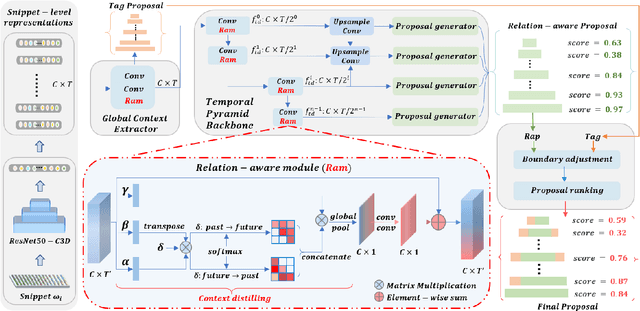
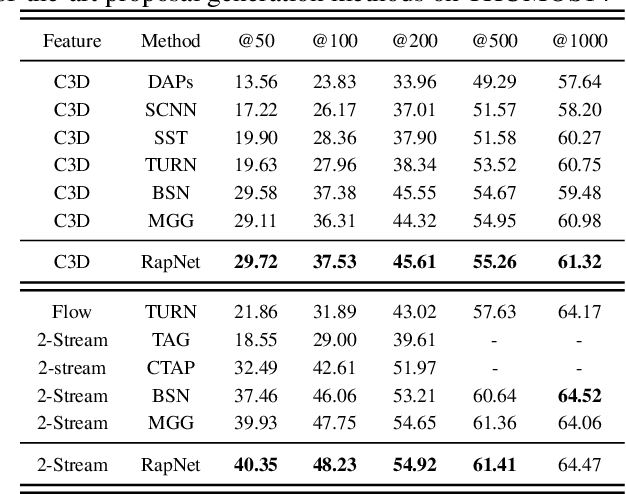
Accurate temporal action proposals play an important role in detecting actions from untrimmed videos. The existing approaches have difficulties in capturing global contextual information and simultaneously localizing actions with different durations. To this end, we propose a Relation-aware pyramid Network (RapNet) to generate highly accurate temporal action proposals. In RapNet, a novel relation-aware module is introduced to exploit bi-directional long-range relations between local features for context distilling. This embedded module enhances the RapNet in terms of its multi-granularity temporal proposal generation ability, given predefined anchor boxes. We further introduce a two-stage adjustment scheme to refine the proposal boundaries and measure their confidence in containing an action with snippet-level actionness. Extensive experiments on the challenging ActivityNet and THUMOS14 benchmarks demonstrate our RapNet generates superior accurate proposals over the existing state-of-the-art methods.
One Shot Domain Adaptation for Person Re-Identification
Nov 26, 2018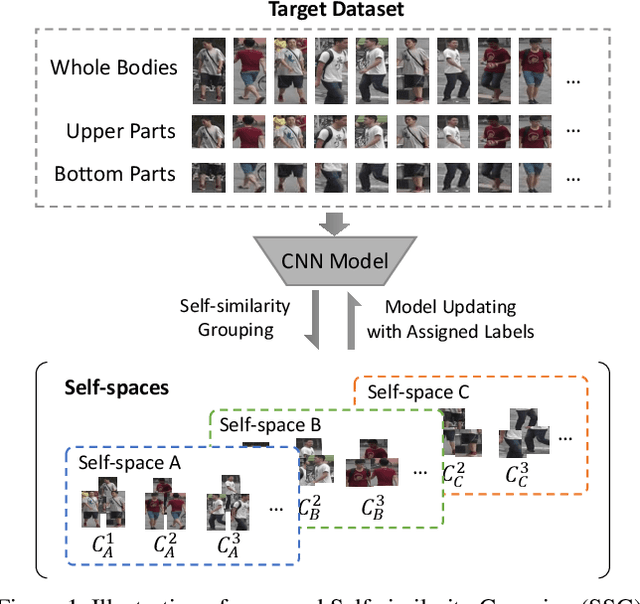

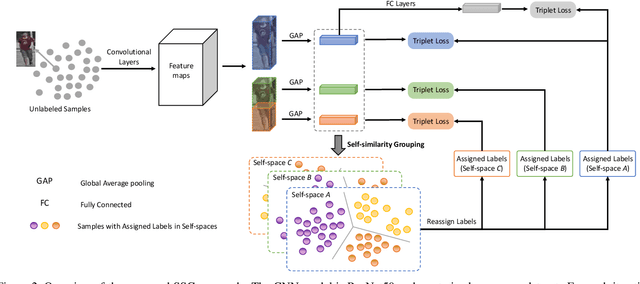

How to effectively address the domain adaptation problem is a challenging task for person re-identification (reID). In this work, we make the first endeavour to tackle this issue according to one shot learning. Given an annotated source training set and a target training set that only one instance for each category is annotated, we aim to achieve competitive re-ID performance on the testing set of the target domain. To this end, we introduce a similarity-guided strategy to progressively assign pseudo labels to unlabeled instances with different confidence scores, which are in turn leveraged as weights to guide the optimization as training goes on. Collaborating with a simple self-mining operation, we make significant improvement in the domain adaptation tasks of re-ID. In particular, we achieve the mAP of 71.5% in the adaptation task of DukeMTMC-reID to Market1501 with one shot setting, which outperforms the state-of-arts of unsupervised domain adaptation more than 17.8%. Under the five shots setting, we achieve competitive accuracy of the fully supervised setting on Market-1501. Code will be made available.