 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Goofus & Gallant Story Corpus for Practical Value Alignment
Jan 16, 2025

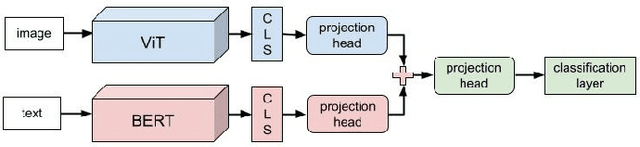
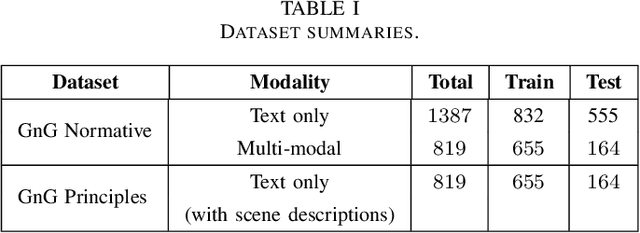
Values or principles are key elements of human society that influence people to behave and function according to an accepted standard set of social rules to maintain social order. As AI systems are becoming ubiquitous in human society, it is a major concern that they could violate these norms or values and potentially cause harm. Thus, to prevent intentional or unintentional harm, AI systems are expected to take actions that align with these principles. Training systems to exhibit this type of behavior is difficult and often requires a specialized dataset. This work presents a multi-modal dataset illustrating normative and non-normative behavior in real-life situations described through natural language and artistic images. This training set contains curated sets of images that are designed to teach young children about social principles. We argue that this is an ideal dataset to use for training socially normative agents given this fact.
Influencing Reinforcement Learning through Natural Language Guidance
Apr 11, 2021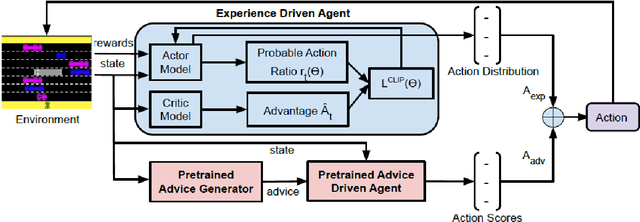
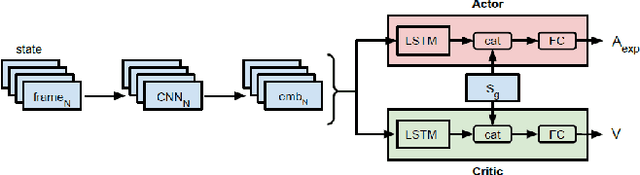
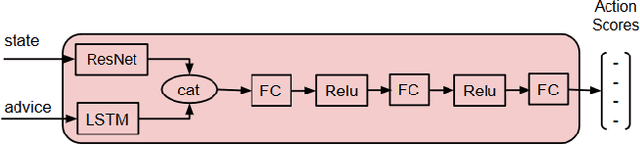

Interactive reinforcement learning agents use human feedback or instruction to help them learn in complex environments. Often, this feedback comes in the form of a discrete signal that is either positive or negative. While informative, this information can be difficult to generalize on its own. In this work, we explore how natural language advice can be used to provide a richer feedback signal to a reinforcement learning agent by extending policy shaping, a well-known Interactive reinforcement learning technique. Usually policy shaping employs a human feedback policy to help an agent to learn more about how to achieve its goal. In our case, we replace this human feedback policy with policy generated based on natural language advice. We aim to inspect if the generated natural language reasoning provides support to a deep reinforcement learning agent to decide its actions successfully in any given environment. So, we design our model with three networks: first one is the experience driven, next is the advice generator and third one is the advice driven. While the experience driven reinforcement learning agent chooses its actions being influenced by the environmental reward, the advice driven neural network with generated feedback by the advice generator for any new state selects its actions to assist the reinforcement learning agent to better policy shaping.
Visual Question Answering Using Semantic Information from Image Descriptions
Apr 23, 2020
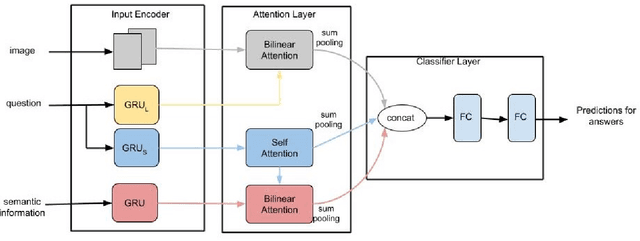


Visual question answering (VQA) is a task that requires AI systems to display multi-modal understanding. A system must be able to reason over the question being asked as well as the image itself to determine reasonable answers to the questions posed. In many cases, simply reasoning over the image itself and the question is not enough to achieve good performance. As an aid of the task, other than region based visual information and natural language questions, external textual knowledge extracted from images can also be used to generate correct answers for questions. Considering these, we propose a deep neural network model that uses an attention mechanism which utilizes image features, the natural language question asked and semantic knowledge extracted from the image to produce open-ended answers for the given questions. The combination of image features and contextual information about the image bolster a model to more accurately respond to questions and potentially do so with less required training data. We evaluate our proposed architecture on a VQA task against a strong baseline and show that our method achieves excellent results on this task.
A Hierarchical Approach for Visual Storytelling Using Image Description
Sep 26, 2019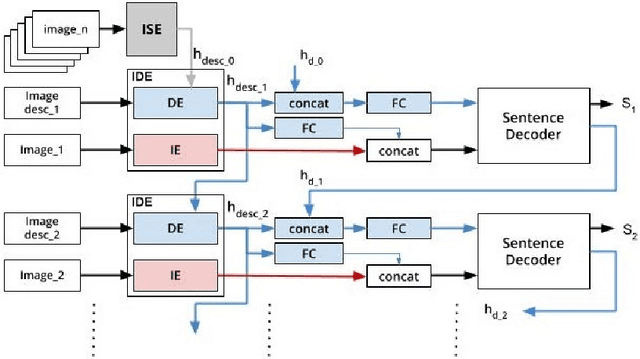

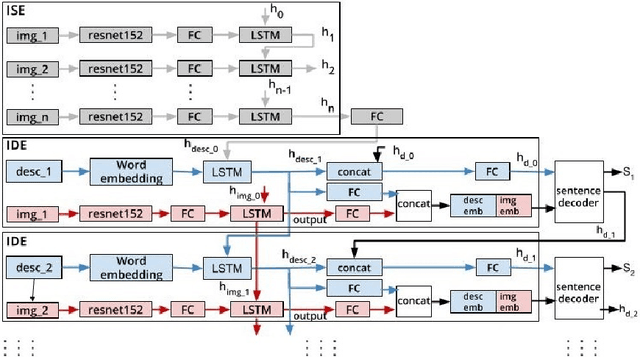
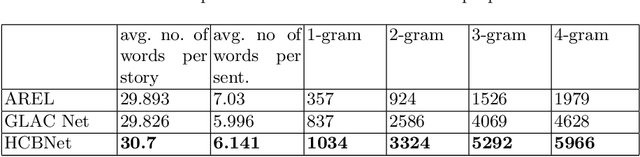
One of the primary challenges of visual storytelling is developing techniques that can maintain the context of the story over long event sequences to generate human-like stories. In this paper, we propose a hierarchical deep learning architecture based on encoder-decoder networks to address this problem. To better help our network maintain this context while also generating long and diverse sentences, we incorporate natural language image descriptions along with the images themselves to generate each story sentence. We evaluate our system on the Visual Storytelling (VIST) dataset and show that our method outperforms state-of-the-art techniques on a suite of different automatic evaluation metrics. The empirical results from this evaluation demonstrate the necessities of different components of our proposed architecture and shows the effectiveness of the architecture for visual storytelling.