 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Approach for Visual Storytelling Using Image Description
Sep 26, 2019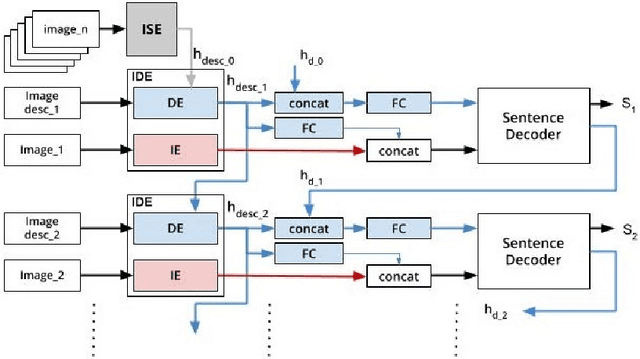

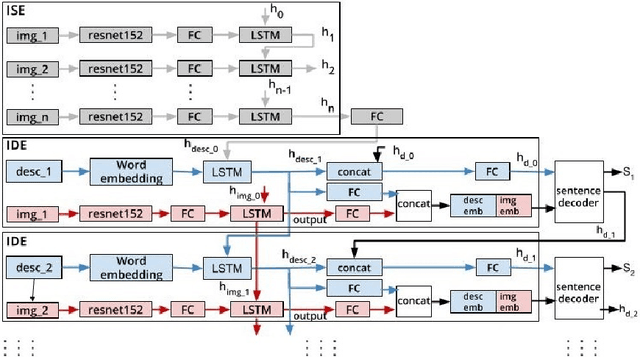
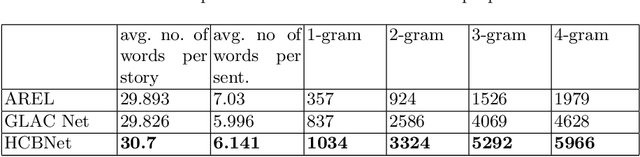
One of the primary challenges of visual storytelling is developing techniques that can maintain the context of the story over long event sequences to generate human-like stories. In this paper, we propose a hierarchical deep learning architecture based on encoder-decoder networks to address this problem. To better help our network maintain this context while also generating long and diverse sentences, we incorporate natural language image descriptions along with the images themselves to generate each story sentence. We evaluate our system on the Visual Storytelling (VIST) dataset and show that our method outperforms state-of-the-art techniques on a suite of different automatic evaluation metrics. The empirical results from this evaluation demonstrate the necessities of different components of our proposed architecture and shows the effectiveness of the architecture for visual storytelling.