 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Reinforcement Learning Using Uncertainty-Aware Large Language Models
Paper and Code
Nov 15, 2024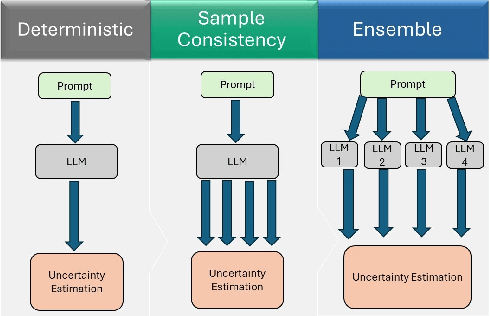

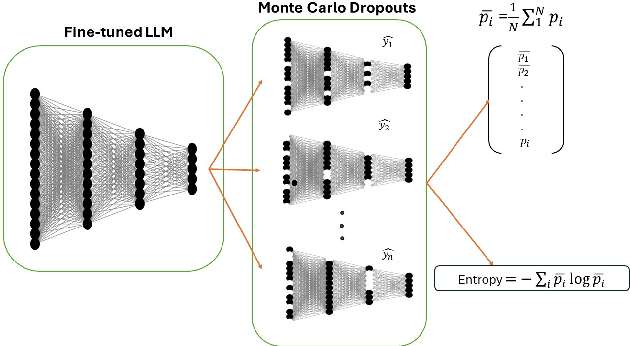

Human guidance in reinforcement learning (RL) is often impractical for large-scale applications due to high costs and time constraints. Large Language Models (LLMs) offer a promising alternative to mitigate RL sample inefficiency and potentially replace human trainers. However, applying LLMs as RL trainers is challenging due to their overconfidence and less reliable solutions in sequential tasks. We address this limitation by introducing a calibrated guidance system that uses Monte Carlo Dropout to enhance LLM advice reliability by assessing prediction variances from multiple forward passes. Additionally, we develop a novel RL policy shaping method based on dynamic model average entropy to adjust the LLM's influence on RL policies according to guidance uncertainty. This approach ensures robust RL training by relying on reliable LLM guidance. To validate our contributions, we conduct extensive experiments in a Minigrid environment with three goals in varying environment sizes. The results showcase superior model performance compared to uncalibrated LLMs, unguided RL, and calibrated LLMs with different shaping policies. Moreover, we analyze various uncertainty estimation methods, demonstrating the effectiveness of average entropy in reflecting higher uncertainty in incorrect guidance. These findings highlight the persistent overconfidence in fine-tuned LLMs and underscore the importance of effective calibration in sequential decision-making problems.