 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPC: Federated Learning for Language Generation with Personal and Context Preference Embeddings
Paper and Code
Oct 07, 2022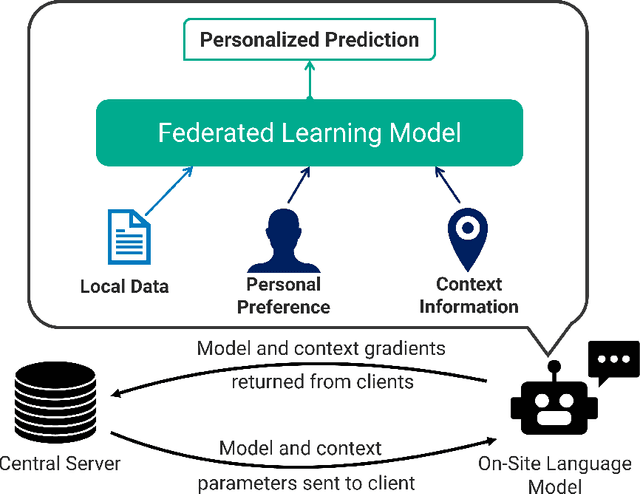
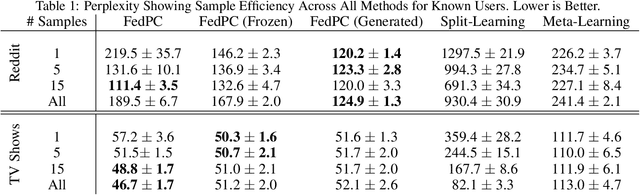
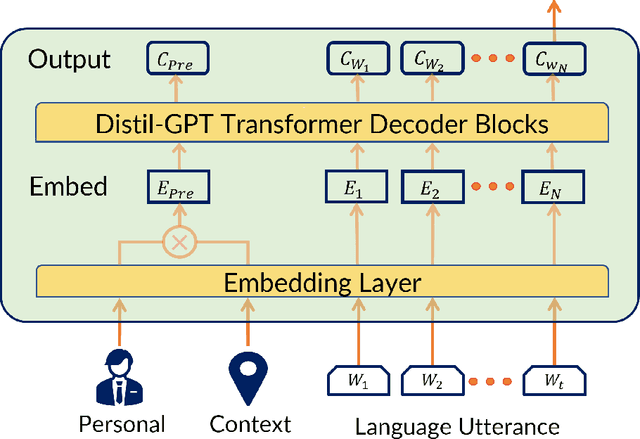
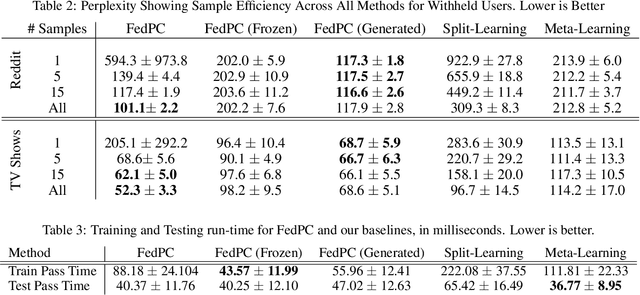
Federated learning is a training paradigm that learns from multiple distributed users without aggregating data on a centralized server. Such a paradigm promises the ability to deploy machine-learning at-scale to a diverse population of end-users without first collecting a large, labeled dataset for all possible tasks. As federated learning typically averages learning updates across a decentralized population, there is a growing need for personalization of federated learning systems (i.e conversational agents must be able to personalize to a specific user's preferences). In this work, we propose a new direction for personalization research within federated learning, leveraging both personal embeddings and shared context embeddings. We also present an approach to predict these ``preference'' embeddings, enabling personalization without backpropagation. Compared to state-of-the-art personalization baselines, our approach achieves a 50\% improvement in test-time perplexity using 0.001\% of the memory required by baseline approaches, and achieving greater sample- and compute-efficiency.