 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Neural Story Generation via Reinforcement Learning
Sep 27, 2018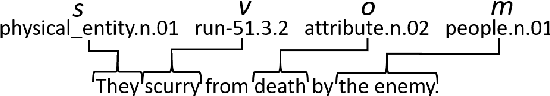
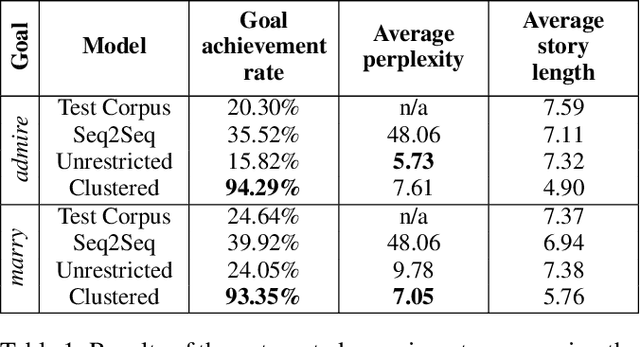
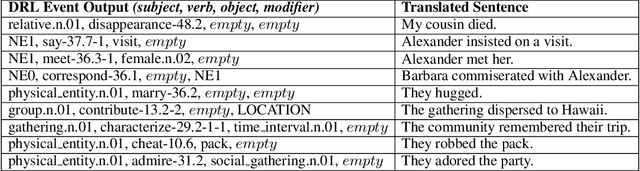
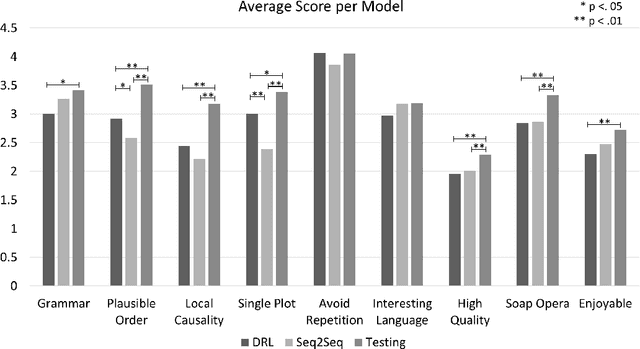
Open story generation is the problem of automatically creating a story for any domain without retraining. Neural language models can be trained on large corpora across many domains and then used to generate stories. However, stories generated via language models tend to lack direction and coherence. We introduce a policy gradient reinforcement learning approach to open story generation that learns to achieve a given narrative goal state. In this work, the goal is for a story to end with a specific type of event, given in advance. However, a reward based on achieving the given goal is too sparse for effective learning. We use reward shaping to provide the reinforcement learner with a partial reward at every step. We show that our technique can train a model that generates a story that reaches the goal 94% of the time and reduces model perplexity. A human subject evaluation shows that stories generated by our technique are perceived to have significantly higher plausible event ordering and plot coherence over a baseline language modeling technique without perceived degradation of overall quality, enjoyability, or local causality.