 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Multi-Modal Grasps for Dexterous Grasping in Dense Clutter
Jun 07, 2021



Grasping arbitrary objects in densely cluttered novel environments is a crucial skill for robots. Though many existing systems enable two-finger parallel-jaw grippers to pick items from clutter, these grippers cannot perform multiple types of grasps. However, multi-modal grasping with multi-finger grippers could much more effectively clear objects of varying sizes from cluttered scenes. We propose an approach to multi-model grasp detection that jointly predicts the probabilities that several types of grasps succeed at a given grasp pose. Given a partial point cloud of a scene, the algorithm proposes a set of feasible grasp candidates, then estimates the probabilities that a grasp of each type would succeed at each candidate pose. Predicting grasp success probabilities directly from point clouds makes our approach agnostic to the number and placement of depth sensors at execution time. We evaluate our system both in simulation and on a real robot with a Robotiq 3-Finger Adaptive Gripper. We compare our network against several baselines that perform fewer types of grasps. Our experiments show that a system that explicitly models grasp type achieves an object retrieval rate 8.5% higher in a complex cluttered environment than our highest-performing baseline.
Robot Object Retrieval with Contextual Natural Language Queries
Jun 23, 2020
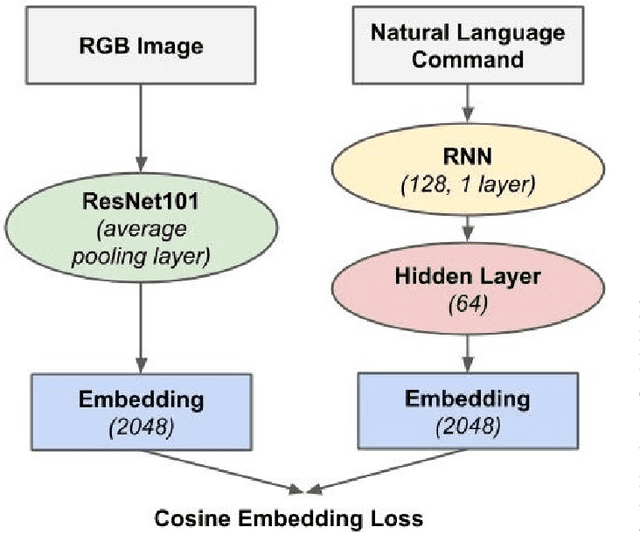
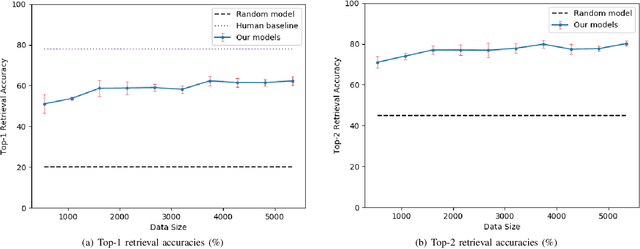

Natural language object retrieval is a highly useful yet challenging task for robots in human-centric environments. Previous work has primarily focused on commands specifying the desired object's type such as "scissors" and/or visual attributes such as "red," thus limiting the robot to only known object classes. We develop a model to retrieve objects based on descriptions of their usage. The model takes in a language command containing a verb, for example "Hand me something to cut," and RGB images of candidate objects and selects the object that best satisfies the task specified by the verb. Our model directly predicts an object's appearance from the object's use specified by a verb phrase. We do not need to explicitly specify an object's class label. Our approach allows us to predict high level concepts like an object's utility based on the language query. Based on contextual information present in the language commands, our model can generalize to unseen object classes and unknown nouns in the commands. Our model correctly selects objects out of sets of five candidates to fulfill natural language commands, and achieves an average accuracy of 62.3% on a held-out test set of unseen ImageNet object classes and 53.0% on unseen object classes and unknown nouns. Our model also achieves an average accuracy of 54.7% on unseen YCB object classes, which have a different image distribution from ImageNet objects. We demonstrate our model on a KUKA LBR iiwa robot arm, enabling the robot to retrieve objects based on natural language descriptions of their usage. We also present a new dataset of 655 verb-object pairs denoting object usage over 50 verbs and 216 object classes.