 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient Methods for Off-policy Control
Paper and Code
Dec 13, 2015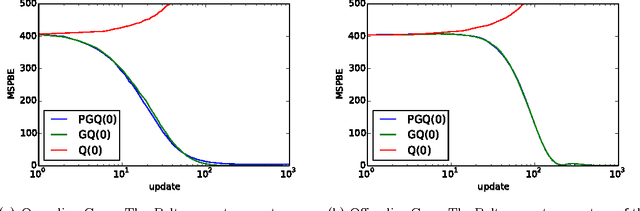
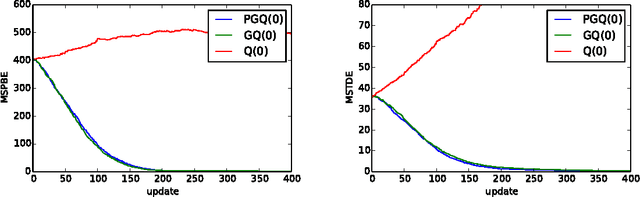
Off-policy learning refers to the problem of learning the value function of a way of behaving, or policy, while following a different policy. Gradient-based off-policy learning algorithms, such as GTD and TDC/GQ, converge even when using function approximation and incremental updates. However, they have been developed for the case of a fixed behavior policy. In control problems, one would like to adapt the behavior policy over time to become more greedy with respect to the existing value function. In this paper, we present the first gradient-based learning algorithms for this problem, which rely on the framework of policy gradient in order to modify the behavior policy. We present derivations of the algorithms, a convergence theorem, and empirical evidence showing that they compare favorably to existing approaches.