Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvantages and Limitations of using Successor Features for Transfer in Reinforcement Learning
Paper and Code
Jul 31, 2017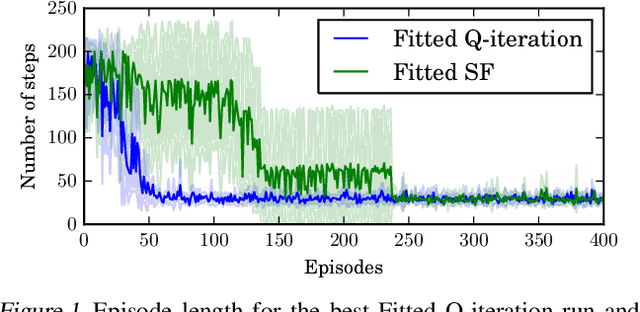
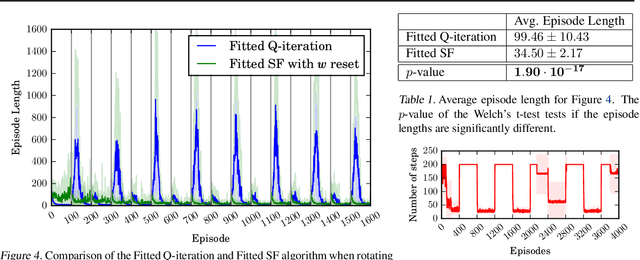
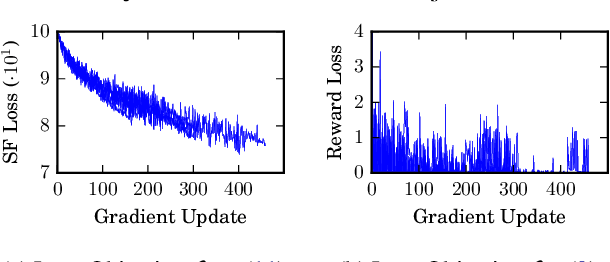
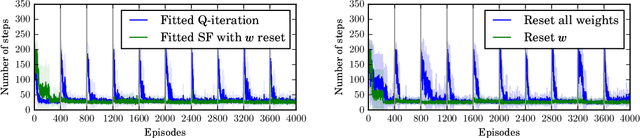
One question central to Reinforcement Learning is how to learn a feature representation that supports algorithm scaling and re-use of learned information from different tasks. Successor Features approach this problem by learning a feature representation that satisfies a temporal constraint. We present an implementation of an approach that decouples the feature representation from the reward function, making it suitable for transferring knowledge between domains. We then assess the advantages and limitations of using Successor Features for transfer.
View paper on