 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Predictive Clustering
Paper and Code
Nov 07, 2022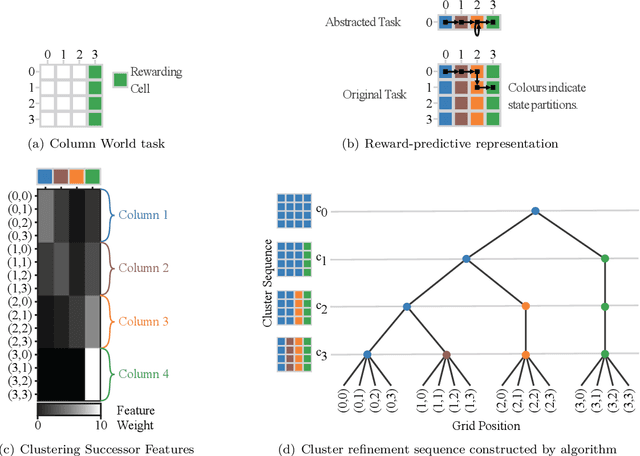

Recent advances in reinforcement-learning research have demonstrated impressive results in building algorithms that can out-perform humans in complex tasks. Nevertheless, creating reinforcement-learning systems that can build abstractions of their experience to accelerate learning in new contexts still remains an active area of research. Previous work showed that reward-predictive state abstractions fulfill this goal, but have only be applied to tabular settings. Here, we provide a clustering algorithm that enables the application of such state abstractions to deep learning settings, providing compressed representations of an agent's inputs that preserve the ability to predict sequences of reward. A convergence theorem and simulations show that the resulting reward-predictive deep network maximally compresses the agent's inputs, significantly speeding up learning in high dimensional visual control tasks. Furthermore, we present different generalization experiments and analyze under which conditions a pre-trained reward-predictive representation network can be re-used without re-training to accelerate learning -- a form of systematic out-of-distribution transfer.