 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Decision-Making for Inline Text Autocomplete
Mar 21, 2024Autocomplete suggestions are fundamental to modern text entry systems, with applications in domains such as messaging and email composition. Typically, autocomplete suggestions are generated from a language model with a confidence threshold. However, this threshold does not directly take into account the cognitive load imposed on the user by surfacing suggestions, such as the effort to switch contexts from typing to reading the suggestion, and the time to decide whether to accept the suggestion. In this paper, we study the problem of improving inline autocomplete suggestions in text entry systems via a sequential decision-making formulation, and use reinforcement learning to learn suggestion policies through repeated interactions with a target user over time. This formulation allows us to factor cognitive load into the objective of training an autocomplete model, through a reward function based on text entry speed. We acquired theoretical and experimental evidence that, under certain objectives, the sequential decision-making formulation of the autocomplete problem provides a better suggestion policy than myopic single-step reasoning. However, aligning these objectives with real users requires further exploration. In particular, we hypothesize that the objectives under which sequential decision-making can improve autocomplete systems are not tailored solely to text entry speed, but more broadly to metrics such as user satisfaction and convenience.
Score Models for Offline Goal-Conditioned Reinforcement Learning
Nov 03, 2023Offline Goal-Conditioned Reinforcement Learning (GCRL) is tasked with learning to achieve multiple goals in an environment purely from offline datasets using sparse reward functions. Offline GCRL is pivotal for developing generalist agents capable of leveraging pre-existing datasets to learn diverse and reusable skills without hand-engineering reward functions. However, contemporary approaches to GCRL based on supervised learning and contrastive learning are often suboptimal in the offline setting. An alternative perspective on GCRL optimizes for occupancy matching, but necessitates learning a discriminator, which subsequently serves as a pseudo-reward for downstream RL. Inaccuracies in the learned discriminator can cascade, negatively influencing the resulting policy. We present a novel approach to GCRL under a new lens of mixture-distribution matching, leading to our discriminator-free method: SMORe. The key insight is combining the occupancy matching perspective of GCRL with a convex dual formulation to derive a learning objective that can better leverage suboptimal offline data. SMORe learns scores or unnormalized densities representing the importance of taking an action at a state for reaching a particular goal. SMORe is principled and our extensive experiments on the fully offline GCRL benchmark composed of robot manipulation and locomotion tasks, including high-dimensional observations, show that SMORe can outperform state-of-the-art baselines by a significant margin.
IQL-TD-MPC: Implicit Q-Learning for Hierarchical Model Predictive Control
Jun 01, 2023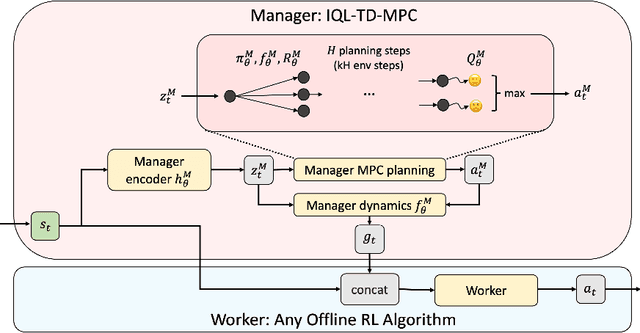
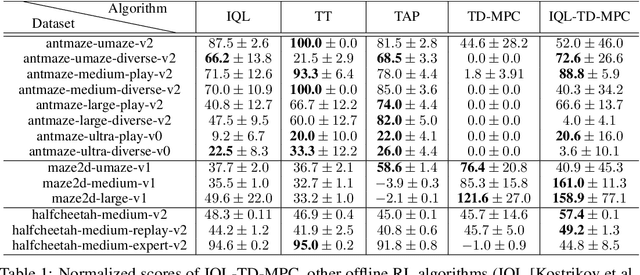

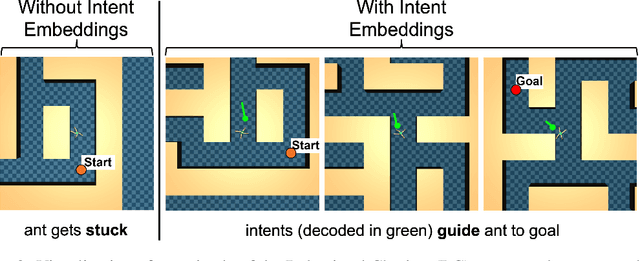
Model-based reinforcement learning (RL) has shown great promise due to its sample efficiency, but still struggles with long-horizon sparse-reward tasks, especially in offline settings where the agent learns from a fixed dataset. We hypothesize that model-based RL agents struggle in these environments due to a lack of long-term planning capabilities, and that planning in a temporally abstract model of the environment can alleviate this issue. In this paper, we make two key contributions: 1) we introduce an offline model-based RL algorithm, IQL-TD-MPC, that extends the state-of-the-art Temporal Difference Learning for Model Predictive Control (TD-MPC) with Implicit Q-Learning (IQL); 2) we propose to use IQL-TD-MPC as a Manager in a hierarchical setting with any off-the-shelf offline RL algorithm as a Worker. More specifically, we pre-train a temporally abstract IQL-TD-MPC Manager to predict "intent embeddings", which roughly correspond to subgoals, via planning. We empirically show that augmenting state representations with intent embeddings generated by an IQL-TD-MPC manager significantly improves off-the-shelf offline RL agents' performance on some of the most challenging D4RL benchmark tasks. For instance, the offline RL algorithms AWAC, TD3-BC, DT, and CQL all get zero or near-zero normalized evaluation scores on the medium and large antmaze tasks, while our modification gives an average score over 40.
Sequence Modeling is a Robust Contender for Offline Reinforcement Learning
May 26, 2023Offline reinforcement learning (RL) allows agents to learn effective, return-maximizing policies from a static dataset. Three major paradigms for offline RL are Q-Learning, Imitation Learning, and Sequence Modeling. A key open question is: which paradigm is preferred under what conditions? We study this question empirically by exploring the performance of representative algorithms -- Conservative Q-Learning (CQL), Behavior Cloning (BC), and Decision Transformer (DT) -- across the commonly used D4RL and Robomimic benchmarks. We design targeted experiments to understand their behavior concerning data suboptimality and task complexity. Our key findings are: (1) Sequence Modeling requires more data than Q-Learning to learn competitive policies but is more robust; (2) Sequence Modeling is a substantially better choice than both Q-Learning and Imitation Learning in sparse-reward and low-quality data settings; and (3) Sequence Modeling and Imitation Learning are preferable as task horizon increases, or when data is obtained from human demonstrators. Based on the overall strength of Sequence Modeling, we also investigate architectural choices and scaling trends for DT on Atari and D4RL and make design recommendations. We find that scaling the amount of data for DT by 5x gives a 2.5x average score improvement on Atari.
Learning Operators with Ignore Effects for Bilevel Planning in Continuous Domains
Aug 16, 2022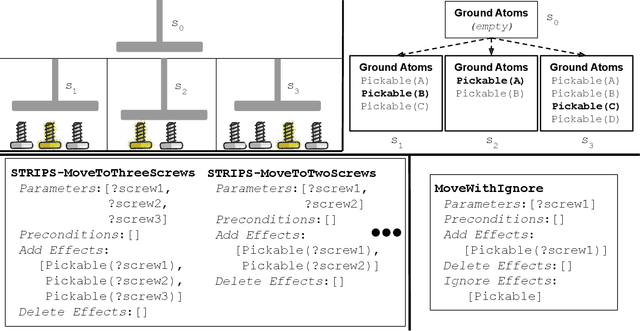
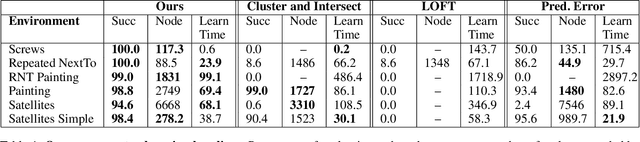
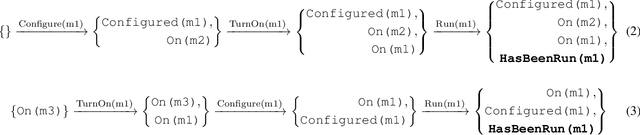
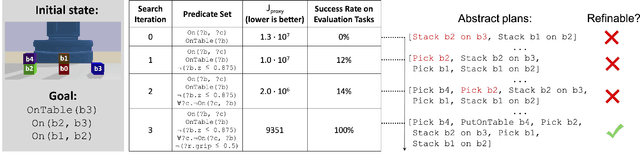
Bilevel planning, in which a high-level search over an abstraction of an environment is used to guide low-level decision making, is an effective approach to solving long-horizon tasks in continuous state and action spaces. Recent work has shown that action abstractions that enable such bilevel planning can be learned in the form of symbolic operators and neural samplers given symbolic predicates and demonstrations that achieve known goals. In this work, we show that existing approaches fall short in environments where actions tend to cause a large number of predicates to change. To address this issue, we propose to learn operators with ignore effects. The key idea motivating our approach is that modeling every observed change in the predicates is unnecessary; the only changes that need be modeled are those that are necessary for high-level search to achieve the specified goal. Experimentally, we show that our approach is able to learn operators with ignore effects across six hybrid robotic domains that enable an agent to solve novel variations of a task, with different initial states, goals, and numbers of objects, significantly more efficiently than several baselines.
Inventing Relational State and Action Abstractions for Effective and Efficient Bilevel Planning
Mar 17, 2022


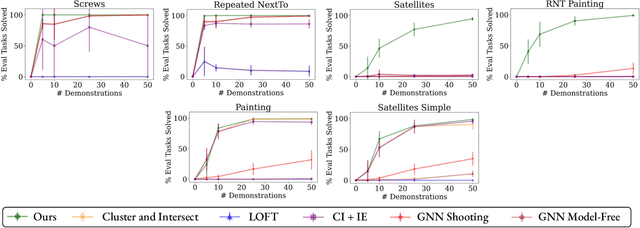
Effective and efficient planning in continuous state and action spaces is fundamentally hard, even when the transition model is deterministic and known. One way to alleviate this challenge is to perform bilevel planning with abstractions, where a high-level search for abstract plans is used to guide planning in the original transition space. In this paper, we develop a novel framework for learning state and action abstractions that are explicitly optimized for both effective (successful) and efficient (fast) bilevel planning. Given demonstrations of tasks in an environment, our data-efficient approach learns relational, neuro-symbolic abstractions that generalize over object identities and numbers. The symbolic components resemble the STRIPS predicates and operators found in AI planning, and the neural components refine the abstractions into actions that can be executed in the environment. Experimentally, we show across four robotic planning environments that our learned abstractions are able to quickly solve held-out tasks of longer horizons than were seen in the demonstrations, and can even outperform the efficiency of abstractions that we manually specified. We also find that as the planner configuration varies, the learned abstractions adapt accordingly, indicating that our abstraction learning method is both "task-aware" and "planner-aware." Code: https://tinyurl.com/predicators-release
Towards Optimal Correlational Object Search
Oct 19, 2021
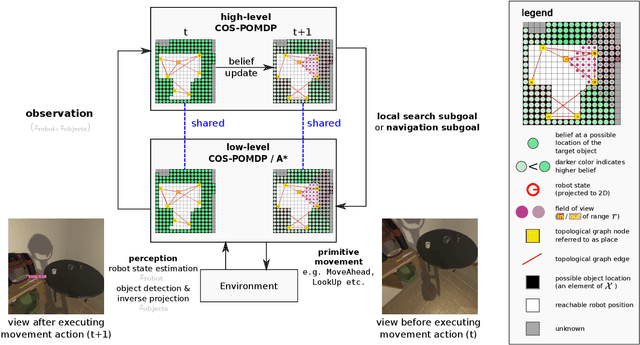


In realistic applications of object search, robots will need to locate target objects in complex environments while coping with unreliable sensors, especially for small or hard-to-detect objects. In such settings, correlational information can be valuable for planning efficiently: when looking for a fork, the robot could start by locating the easier-to-detect refrigerator, since forks would probably be found nearby. Previous approaches to object search with correlational information typically resort to ad-hoc or greedy search strategies. In this paper, we propose the Correlational Object Search POMDP (COS-POMDP), which can be solved to produce search strategies that use correlational information. COS-POMDPs contain a correlation-based observation model that allows us to avoid the exponential blow-up of maintaining a joint belief about all objects, while preserving the optimal solution to this naive, exponential POMDP formulation. We propose a hierarchical planning algorithm to scale up COS-POMDP for practical domains. We conduct experiments using AI2-THOR, a realistic simulator of household environments, as well as YOLOv5, a widely-used object detector. Our results show that, particularly for hard-to-detect objects, such as scrub brush and remote control, our method offers the most robust performance compared to baselines that ignore correlations as well as a greedy, next-best view approach.
Reinforcement Learning for Classical Planning: Viewing Heuristics as Dense Reward Generators
Sep 30, 2021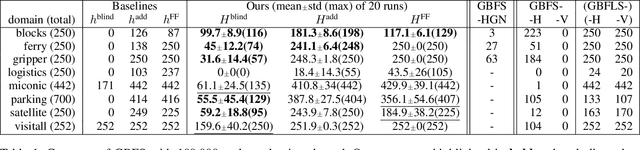
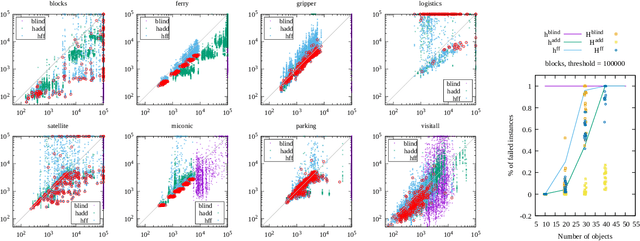

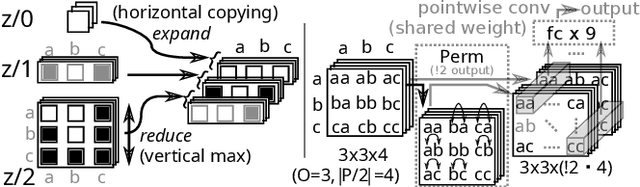
Recent advances in reinforcement learning (RL) have led to a growing interest in applying RL to classical planning domains or applying classical planning methods to some complex RL domains. However, the long-horizon goal-based problems found in classical planning lead to sparse rewards for RL, making direct application inefficient. In this paper, we propose to leverage domain-independent heuristic functions commonly used in the classical planning literature to improve the sample efficiency of RL. These classical heuristics act as dense reward generators to alleviate the sparse-rewards issue and enable our RL agent to learn domain-specific value functions as residuals on these heuristics, making learning easier. Correct application of this technique requires consolidating the discounted metric used in RL and the non-discounted metric used in heuristics. We implement the value functions using Neural Logic Machines, a neural network architecture designed for grounded first-order logic inputs. We demonstrate on several classical planning domains that using classical heuristics for RL allows for good sample efficiency compared to sparse-reward RL. We further show that our learned value functions generalize to novel problem instances in the same domain.
Learning Neuro-Symbolic Relational Transition Models for Bilevel Planning
May 28, 2021

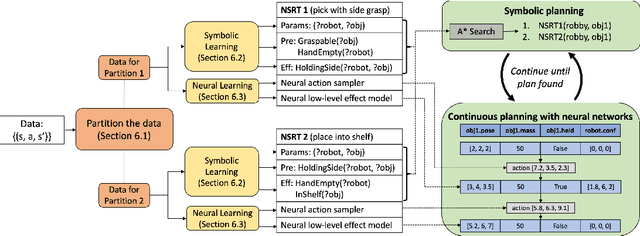

Despite recent, independent progress in model-based reinforcement learning and integrated symbolic-geometric robotic planning, synthesizing these techniques remains challenging because of their disparate assumptions and strengths. In this work, we take a step toward bridging this gap with Neuro-Symbolic Relational Transition Models (NSRTs), a novel class of transition models that are data-efficient to learn, compatible with powerful robotic planning methods, and generalizable over objects. NSRTs have both symbolic and neural components, enabling a bilevel planning scheme where symbolic AI planning in an outer loop guides continuous planning with neural models in an inner loop. Experiments in four robotic planning domains show that NSRTs can be learned after only tens or hundreds of training episodes, and then used for fast planning in new tasks that require up to 60 actions to reach the goal and involve many more objects than were seen during training. Video: https://tinyurl.com/chitnis-nsrts
Learning Symbolic Operators for Task and Motion Planning
Feb 28, 2021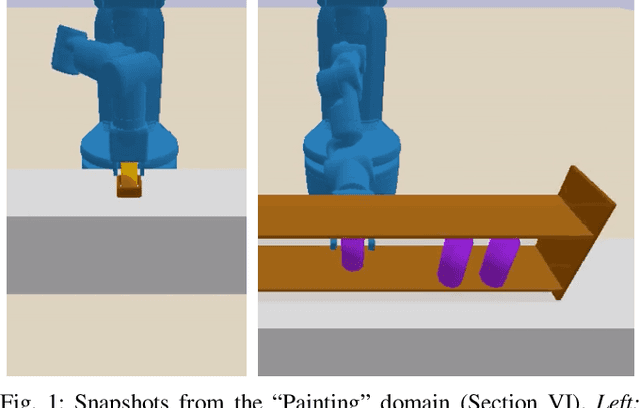



Robotic planning problems in hybrid state and action spaces can be solved by integrated task and motion planners (TAMP) that handle the complex interaction between motion-level decisions and task-level plan feasibility. TAMP approaches rely on domain-specific symbolic operators to guide the task-level search, making planning efficient. In this work, we formalize and study the problem of operator learning for TAMP. Central to this study is the view that operators define a lossy abstraction of the transition model of the underlying domain. We then propose a bottom-up relational learning method for operator learning and show how the learned operators can be used for planning in a TAMP system. Experimentally, we provide results in three domains, including long-horizon robotic planning tasks. We find our approach to substantially outperform several baselines, including three graph neural network-based model-free approaches based on recent work. Video: https://youtu.be/iVfpX9BpBRo