 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021

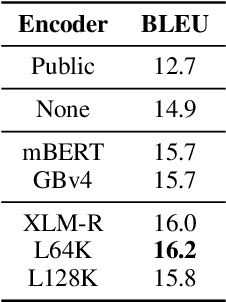

Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
Model compression for faster structural separation of macromolecules captured by Cellular Electron Cryo-Tomography
Jan 31, 2018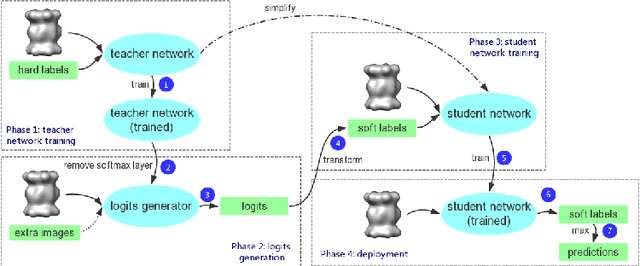

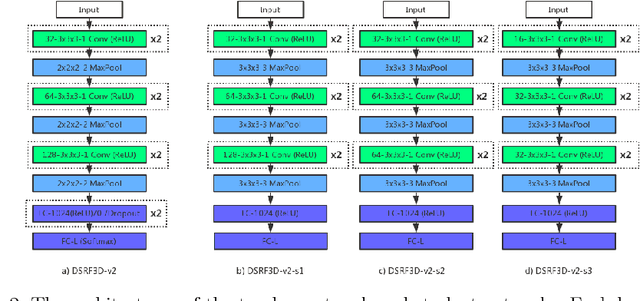
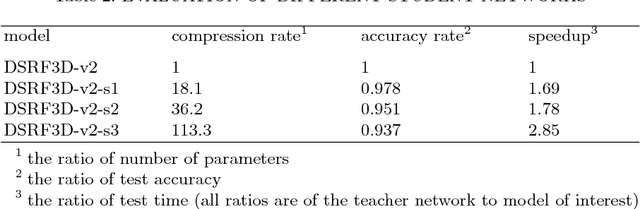
Electron Cryo-Tomography (ECT) enables 3D visualization of macromolecule structure inside single cells. Macromolecule classification approaches based on convolutional neural networks (CNN) were developed to separate millions of macromolecules captured from ECT systematically. However, given the fast accumulation of ECT data, it will soon become necessary to use CNN models to efficiently and accurately separate substantially more macromolecules at the prediction stage, which requires additional computational costs. To speed up the prediction, we compress classification models into compact neural networks with little in accuracy for deployment. Specifically, we propose to perform model compression through knowledge distillation. Firstly, a complex teacher network is trained to generate soft labels with better classification feasibility followed by training of customized student networks with simple architectures using the soft label to compress model complexity. Our tests demonstrate that our compressed models significantly reduce the number of parameters and time cost while maintaining similar classification accuracy.
* 8 pages