 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Generation and Validation of Memory-Aware Formal Function Specifications
Mar 12, 2026Formal verification of memory-manipulating programs critically depends on precise function specifications that capture memory states written by experts. This requirement has become a major bottleneck as large language models (LLMs) increasingly generate low-level systems code whose correctness cannot be assumed. To enable scalable formal verification, we focus exclusively on function specification generation, deliberately avoiding the synthesis of complex loop invariants that are central to traditional verification pipelines. We propose a neuro-symbolic framework for automatically generating memory-aware formal function specifications for C programs from natural language problem descriptions and function signatures. The pipeline first produces candidate specifications via in-context learning, and then iteratively refines them using compiler diagnostics from symbolic provers and the verification toolchain. In particular, we validate candidate specifications by constructing a proof for the negation of the specification with concrete examples, enabling machine-checked rejection of plausible-but-incorrect specifications. To support systematic evaluation, we introduce LeetCode-C-Spec, a new benchmark of 200 C programming problems for generating memory-aware formal function specifications. Experiments show that iterative refinement substantially improves syntactic validity, while symbolic prover-based refutation significantly enhances correctness assessment by filtering false positives that LLM-only judges frequently accept. Our results demonstrate that combining neural generation with symbolic feedback provides an effective approach to formal specification synthesis for memory-safe systems software.
Policy-Based Trajectory Clustering in Offline Reinforcement Learning
Jun 12, 2025We introduce a novel task of clustering trajectories from offline reinforcement learning (RL) datasets, where each cluster center represents the policy that generated its trajectories. By leveraging the connection between the KL-divergence of offline trajectory distributions and a mixture of policy-induced distributions, we formulate a natural clustering objective. To solve this, we propose Policy-Guided K-means (PG-Kmeans) and Centroid-Attracted Autoencoder (CAAE). PG-Kmeans iteratively trains behavior cloning (BC) policies and assigns trajectories based on policy generation probabilities, while CAAE resembles the VQ-VAE framework by guiding the latent representations of trajectories toward the vicinity of specific codebook entries to achieve clustering. Theoretically, we prove the finite-step convergence of PG-Kmeans and identify a key challenge in offline trajectory clustering: the inherent ambiguity of optimal solutions due to policy-induced conflicts, which can result in multiple equally valid but structurally distinct clusterings. Experimentally, we validate our methods on the widely used D4RL dataset and custom GridWorld environments. Our results show that both PG-Kmeans and CAAE effectively partition trajectories into meaningful clusters. They offer a promising framework for policy-based trajectory clustering, with broad applications in offline RL and beyond.
USV-AUV Collaboration Framework for Underwater Tasks under Extreme Sea Conditions
Sep 04, 2024



Autonomous underwater vehicles (AUVs) are valuable for ocean exploration due to their flexibility and ability to carry communication and detection units. Nevertheless, AUVs alone often face challenges in harsh and extreme sea conditions. This study introduces a unmanned surface vehicle (USV)-AUV collaboration framework, which includes high-precision multi-AUV positioning using USV path planning via Fisher information matrix optimization and reinforcement learning for multi-AUV cooperative tasks. Applied to a multi-AUV underwater data collection task scenario, extensive simulations validate the framework's feasibility and superior performance, highlighting exceptional coordination and robustness under extreme sea conditions. The simulation code will be made available as open-source to foster future research in this area.
Multi-Agent Reinforcement Learning from Human Feedback: Data Coverage and Algorithmic Techniques
Sep 04, 2024



We initiate the study of Multi-Agent Reinforcement Learning from Human Feedback (MARLHF), exploring both theoretical foundations and empirical validations. We define the task as identifying Nash equilibrium from a preference-only offline dataset in general-sum games, a problem marked by the challenge of sparse feedback signals. Our theory establishes the upper complexity bounds for Nash Equilibrium in effective MARLHF, demonstrating that single-policy coverage is inadequate and highlighting the importance of unilateral dataset coverage. These theoretical insights are verified through comprehensive experiments. To enhance the practical performance, we further introduce two algorithmic techniques. (1) We propose a Mean Squared Error (MSE) regularization along the time axis to achieve a more uniform reward distribution and improve reward learning outcomes. (2) We utilize imitation learning to approximate the reference policy, ensuring stability and effectiveness in training. Our findings underscore the multifaceted approach required for MARLHF, paving the way for effective preference-based multi-agent systems.
CSANet: Channel Spatial Attention Network for Robust 3D Face Alignment and Reconstruction
May 30, 2024



Our project proposes an end-to-end 3D face alignment and reconstruction network. The backbone of our model is built by Bottle-Neck structure via Depth-wise Separable Convolution. We integrate Coordinate Attention mechanism and Spatial Group-wise Enhancement to extract more representative features. For more stable training process and better convergence, we jointly use Wing loss and the Weighted Parameter Distance Cost to learn parameters for 3D Morphable model and 3D vertices. Our proposed model outperforms all baseline models both quantitatively and qualitatively.
Transferable Reinforcement Learning via Generalized Occupancy Models
Mar 10, 2024Intelligent agents must be generalists - showing the ability to quickly adapt and generalize to varying tasks. Within the framework of reinforcement learning (RL), model-based RL algorithms learn a task-agnostic dynamics model of the world, in principle allowing them to generalize to arbitrary rewards. However, one-step models naturally suffer from compounding errors, making them ineffective for problems with long horizons and large state spaces. In this work, we propose a novel class of models - generalized occupancy models (GOMs) - that retain the generality of model-based RL while avoiding compounding error. The key idea behind GOMs is to model the distribution of all possible long-term outcomes from a given state under the coverage of a stationary dataset, along with a policy that realizes a particular outcome from the given state. These models can then quickly be used to select the optimal action for arbitrary new tasks, without having to redo policy optimization. By directly modeling long-term outcomes, GOMs avoid compounding error while retaining generality across arbitrary reward functions. We provide a practical instantiation of GOMs using diffusion models and show its efficacy as a new class of transferable models, both theoretically and empirically across a variety of simulated robotics problems. Videos and code at https://weirdlabuw.github.io/gom/.
Tree-of-Mixed-Thought: Combining Fast and Slow Thinking for Multi-hop Visual Reasoning
Aug 21, 2023



There emerges a promising trend of using large language models (LLMs) to generate code-like plans for complex inference tasks such as visual reasoning. This paradigm, known as LLM-based planning, provides flexibility in problem solving and endows better interpretability. However, current research is mostly limited to basic scenarios of simple questions that can be straightforward answered in a few inference steps. Planning for the more challenging multi-hop visual reasoning tasks remains under-explored. Specifically, under multi-hop reasoning situations, the trade-off between accuracy and the complexity of plan-searching becomes prominent. The prevailing algorithms either address the efficiency issue by employing the fast one-stop generation or adopt a complex iterative generation method to improve accuracy. Both fail to balance the need for efficiency and performance. Drawing inspiration from the dual system of cognition in the human brain, the fast and the slow think processes, we propose a hierarchical plan-searching algorithm that integrates the one-stop reasoning (fast) and the Tree-of-thought (slow). Our approach succeeds in performance while significantly saving inference steps. Moreover, we repurpose the PTR and the CLEVER datasets, developing a systematic framework for evaluating the performance and efficiency of LLMs-based plan-search algorithms under reasoning tasks at different levels of difficulty. Extensive experiments demonstrate the superiority of our proposed algorithm in terms of performance and efficiency. The dataset and code will be release soon.
On Gap-dependent Bounds for Offline Reinforcement Learning
Jun 01, 2022
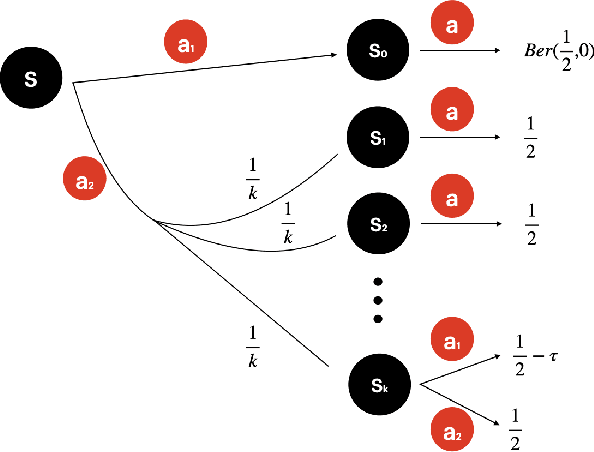
This paper presents a systematic study on gap-dependent sample complexity in offline reinforcement learning. Prior work showed when the density ratio between an optimal policy and the behavior policy is upper bounded (the optimal policy coverage assumption), then the agent can achieve an $O\left(\frac{1}{\epsilon^2}\right)$ rate, which is also minimax optimal. We show under the optimal policy coverage assumption, the rate can be improved to $O\left(\frac{1}{\epsilon}\right)$ when there is a positive sub-optimality gap in the optimal $Q$-function. Furthermore, we show when the visitation probabilities of the behavior policy are uniformly lower bounded for states where an optimal policy's visitation probabilities are positive (the uniform optimal policy coverage assumption), the sample complexity of identifying an optimal policy is independent of $\frac{1}{\epsilon}$. Lastly, we present nearly-matching lower bounds to complement our gap-dependent upper bounds.