 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Gap-dependent Bounds for Offline Reinforcement Learning
Paper and Code
Jun 01, 2022
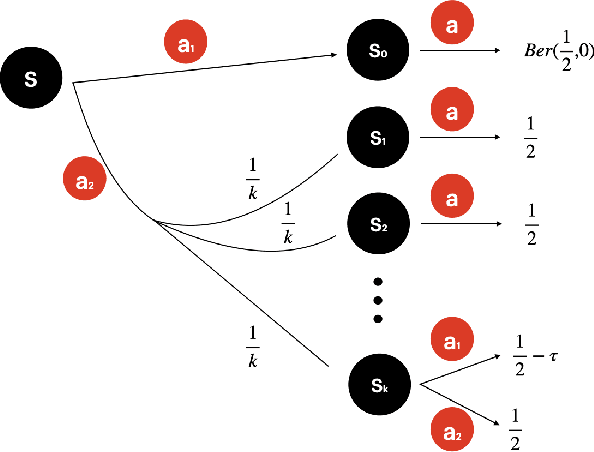
This paper presents a systematic study on gap-dependent sample complexity in offline reinforcement learning. Prior work showed when the density ratio between an optimal policy and the behavior policy is upper bounded (the optimal policy coverage assumption), then the agent can achieve an $O\left(\frac{1}{\epsilon^2}\right)$ rate, which is also minimax optimal. We show under the optimal policy coverage assumption, the rate can be improved to $O\left(\frac{1}{\epsilon}\right)$ when there is a positive sub-optimality gap in the optimal $Q$-function. Furthermore, we show when the visitation probabilities of the behavior policy are uniformly lower bounded for states where an optimal policy's visitation probabilities are positive (the uniform optimal policy coverage assumption), the sample complexity of identifying an optimal policy is independent of $\frac{1}{\epsilon}$. Lastly, we present nearly-matching lower bounds to complement our gap-dependent upper bounds.