 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Bridge: 3D Representations for Cross Domain Policy Learning
Jan 24, 2026Robot foundation models are beginning to deliver on the promise of generalist robotic agents, yet progress remains constrained by the scarcity of large-scale real-world manipulation datasets. Simulation and synthetic data generation offer a scalable alternative, but their usefulness is limited by the visual domain gap between simulation and reality. In this work, we present Point Bridge, a framework that leverages unified, domain-agnostic point-based representations to unlock synthetic datasets for zero-shot sim-to-real policy transfer, without explicit visual or object-level alignment. Point Bridge combines automated point-based representation extraction via Vision-Language Models (VLMs), transformer-based policy learning, and efficient inference-time pipelines to train capable real-world manipulation agents using only synthetic data. With additional co-training on small sets of real demonstrations, Point Bridge further improves performance, substantially outperforming prior vision-based sim-and-real co-training methods. It achieves up to 44% gains in zero-shot sim-to-real transfer and up to 66% with limited real data across both single-task and multitask settings. Videos of the robot are best viewed at: https://pointbridge3d.github.io/
Touch begins where vision ends: Generalizable policies for contact-rich manipulation
Jun 16, 2025Data-driven approaches struggle with precise manipulation; imitation learning requires many hard-to-obtain demonstrations, while reinforcement learning yields brittle, non-generalizable policies. We introduce VisuoTactile Local (ViTaL) policy learning, a framework that solves fine-grained manipulation tasks by decomposing them into two phases: a reaching phase, where a vision-language model (VLM) enables scene-level reasoning to localize the object of interest, and a local interaction phase, where a reusable, scene-agnostic ViTaL policy performs contact-rich manipulation using egocentric vision and tactile sensing. This approach is motivated by the observation that while scene context varies, the low-level interaction remains consistent across task instances. By training local policies once in a canonical setting, they can generalize via a localize-then-execute strategy. ViTaL achieves around 90% success on contact-rich tasks in unseen environments and is robust to distractors. ViTaL's effectiveness stems from three key insights: (1) foundation models for segmentation enable training robust visual encoders via behavior cloning; (2) these encoders improve the generalizability of policies learned using residual RL; and (3) tactile sensing significantly boosts performance in contact-rich tasks. Ablation studies validate each of these insights, and we demonstrate that ViTaL integrates well with high-level VLMs, enabling robust, reusable low-level skills. Results and videos are available at https://vitalprecise.github.io.
Point Policy: Unifying Observations and Actions with Key Points for Robot Manipulation
Feb 27, 2025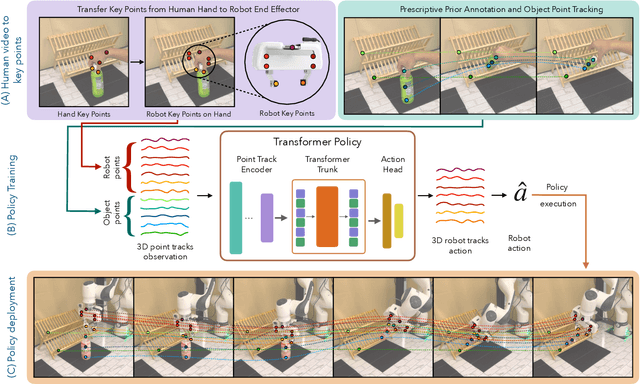

Building robotic agents capable of operating across diverse environments and object types remains a significant challenge, often requiring extensive data collection. This is particularly restrictive in robotics, where each data point must be physically executed in the real world. Consequently, there is a critical need for alternative data sources for robotics and frameworks that enable learning from such data. In this work, we present Point Policy, a new method for learning robot policies exclusively from offline human demonstration videos and without any teleoperation data. Point Policy leverages state-of-the-art vision models and policy architectures to translate human hand poses into robot poses while capturing object states through semantically meaningful key points. This approach yields a morphology-agnostic representation that facilitates effective policy learning. Our experiments on 8 real-world tasks demonstrate an overall 75% absolute improvement over prior works when evaluated in identical settings as training. Further, Point Policy exhibits a 74% gain across tasks for novel object instances and is robust to significant background clutter. Videos of the robot are best viewed at https://point-policy.github.io/.
P3-PO: Prescriptive Point Priors for Visuo-Spatial Generalization of Robot Policies
Dec 09, 2024
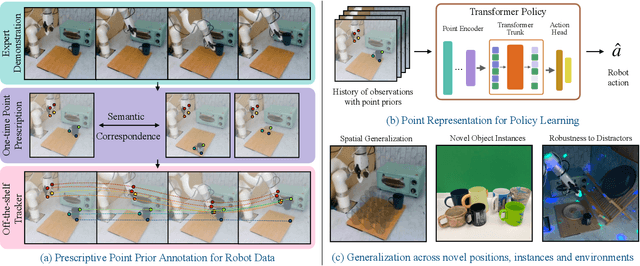


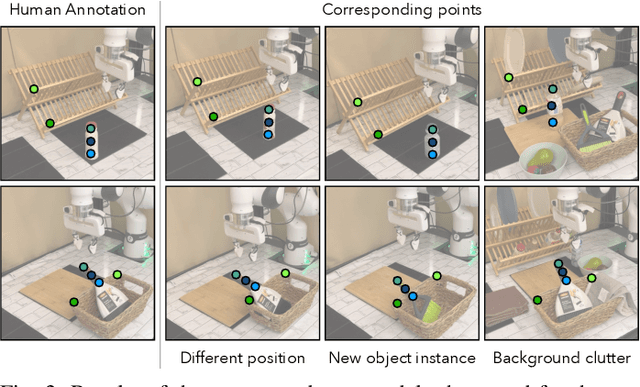
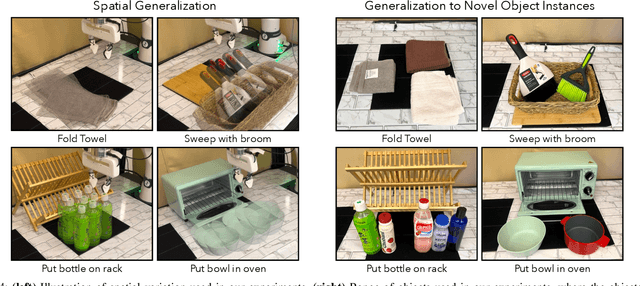
Developing generalizable robot policies that can robustly handle varied environmental conditions and object instances remains a fundamental challenge in robot learning. While considerable efforts have focused on collecting large robot datasets and developing policy architectures to learn from such data, naively learning from visual inputs often results in brittle policies that fail to transfer beyond the training data. This work presents Prescriptive Point Priors for Policies or P3-PO, a novel framework that constructs a unique state representation of the environment leveraging recent advances in computer vision and robot learning to achieve improved out-of-distribution generalization for robot manipulation. This representation is obtained through two steps. First, a human annotator prescribes a set of semantically meaningful points on a single demonstration frame. These points are then propagated through the dataset using off-the-shelf vision models. The derived points serve as an input to state-of-the-art policy architectures for policy learning. Our experiments across four real-world tasks demonstrate an overall 43% absolute improvement over prior methods when evaluated in identical settings as training. Further, P3-PO exhibits 58% and 80% gains across tasks for new object instances and more cluttered environments respectively. Videos illustrating the robot's performance are best viewed at point-priors.github.io.
Learning Precise, Contact-Rich Manipulation through Uncalibrated Tactile Skins
Oct 22, 2024



While visuomotor policy learning has advanced robotic manipulation, precisely executing contact-rich tasks remains challenging due to the limitations of vision in reasoning about physical interactions. To address this, recent work has sought to integrate tactile sensing into policy learning. However, many existing approaches rely on optical tactile sensors that are either restricted to recognition tasks or require complex dimensionality reduction steps for policy learning. In this work, we explore learning policies with magnetic skin sensors, which are inherently low-dimensional, highly sensitive, and inexpensive to integrate with robotic platforms. To leverage these sensors effectively, we present the Visuo-Skin (ViSk) framework, a simple approach that uses a transformer-based policy and treats skin sensor data as additional tokens alongside visual information. Evaluated on four complex real-world tasks involving credit card swiping, plug insertion, USB insertion, and bookshelf retrieval, ViSk significantly outperforms both vision-only and optical tactile sensing based policies. Further analysis reveals that combining tactile and visual modalities enhances policy performance and spatial generalization, achieving an average improvement of 27.5% across tasks. https://visuoskin.github.io/
DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control
Sep 18, 2024



Imitation learning has proven to be a powerful tool for training complex visuomotor policies. However, current methods often require hundreds to thousands of expert demonstrations to handle high-dimensional visual observations. A key reason for this poor data efficiency is that visual representations are predominantly either pretrained on out-of-domain data or trained directly through a behavior cloning objective. In this work, we present DynaMo, a new in-domain, self-supervised method for learning visual representations. Given a set of expert demonstrations, we jointly learn a latent inverse dynamics model and a forward dynamics model over a sequence of image embeddings, predicting the next frame in latent space, without augmentations, contrastive sampling, or access to ground truth actions. Importantly, DynaMo does not require any out-of-domain data such as Internet datasets or cross-embodied datasets. On a suite of six simulated and real environments, we show that representations learned with DynaMo significantly improve downstream imitation learning performance over prior self-supervised learning objectives, and pretrained representations. Gains from using DynaMo hold across policy classes such as Behavior Transformer, Diffusion Policy, MLP, and nearest neighbors. Finally, we ablate over key components of DynaMo and measure its impact on downstream policy performance. Robot videos are best viewed at https://dynamo-ssl.github.io
BAKU: An Efficient Transformer for Multi-Task Policy Learning
Jun 11, 2024Training generalist agents capable of solving diverse tasks is challenging, often requiring large datasets of expert demonstrations. This is particularly problematic in robotics, where each data point requires physical execution of actions in the real world. Thus, there is a pressing need for architectures that can effectively leverage the available training data. In this work, we present BAKU, a simple transformer architecture that enables efficient learning of multi-task robot policies. BAKU builds upon recent advancements in offline imitation learning and meticulously combines observation trunks, action chunking, multi-sensory observations, and action heads to substantially improve upon prior work. Our experiments on 129 simulated tasks across LIBERO, Meta-World suite, and the Deepmind Control suite exhibit an overall 18% absolute improvement over RT-1 and MT-ACT, with a 36% improvement on the harder LIBERO benchmark. On 30 real-world manipulation tasks, given an average of just 17 demonstrations per task, BAKU achieves a 91% success rate. Videos of the robot are best viewed at https://baku-robot.github.io/.
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
Mar 12, 2024


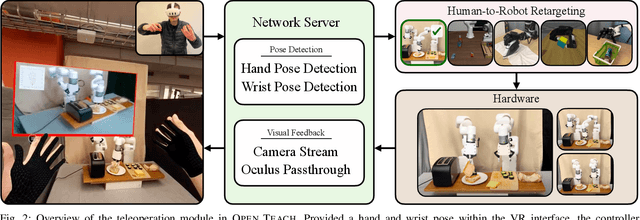
Open-sourced, user-friendly tools form the bedrock of scientific advancement across disciplines. The widespread adoption of data-driven learning has led to remarkable progress in multi-fingered dexterity, bimanual manipulation, and applications ranging from logistics to home robotics. However, existing data collection platforms are often proprietary, costly, or tailored to specific robotic morphologies. We present OPEN TEACH, a new teleoperation system leveraging VR headsets to immerse users in mixed reality for intuitive robot control. Built on the affordable Meta Quest 3, which costs $500, OPEN TEACH enables real-time control of various robots, including multi-fingered hands and bimanual arms, through an easy-to-use app. Using natural hand gestures and movements, users can manipulate robots at up to 90Hz with smooth visual feedback and interface widgets offering closeup environment views. We demonstrate the versatility of OPEN TEACH across 38 tasks on different robots. A comprehensive user study indicates significant improvement in teleoperation capability over the AnyTeleop framework. Further experiments exhibit that the collected data is compatible with policy learning on 10 dexterous and contact-rich manipulation tasks. Currently supporting Franka, xArm, Jaco, and Allegro platforms, OPEN TEACH is fully open-sourced to promote broader adoption. Videos are available at https://open-teach.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
PolyTask: Learning Unified Policies through Behavior Distillation
Oct 12, 2023Unified models capable of solving a wide variety of tasks have gained traction in vision and NLP due to their ability to share regularities and structures across tasks, which improves individual task performance and reduces computational footprint. However, the impact of such models remains limited in embodied learning problems, which present unique challenges due to interactivity, sample inefficiency, and sequential task presentation. In this work, we present PolyTask, a novel method for learning a single unified model that can solve various embodied tasks through a 'learn then distill' mechanism. In the 'learn' step, PolyTask leverages a few demonstrations for each task to train task-specific policies. Then, in the 'distill' step, task-specific policies are distilled into a single policy using a new distillation method called Behavior Distillation. Given a unified policy, individual task behavior can be extracted through conditioning variables. PolyTask is designed to be conceptually simple while being able to leverage well-established algorithms in RL to enable interactivity, a handful of expert demonstrations to allow for sample efficiency, and preventing interactive access to tasks during distillation to enable lifelong learning. Experiments across three simulated environment suites and a real-robot suite show that PolyTask outperforms prior state-of-the-art approaches in multi-task and lifelong learning settings by significant margins.