 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREND: Tri-teaching for Robust Preference-based Reinforcement Learning with Demonstrations
May 09, 2025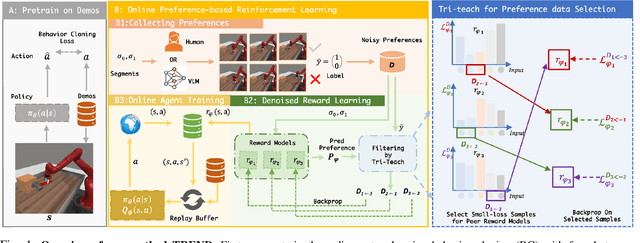
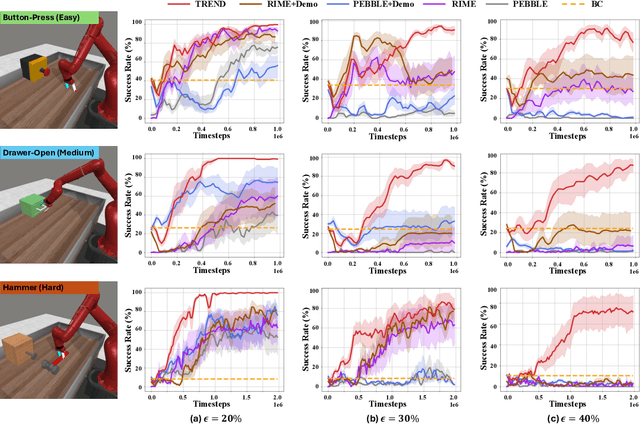
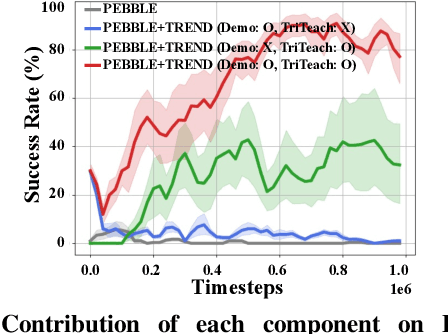
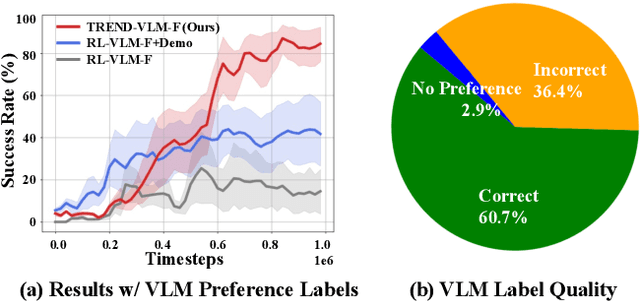
Preference feedback collected by human or VLM annotators is often noisy, presenting a significant challenge for preference-based reinforcement learning that relies on accurate preference labels. To address this challenge, we propose TREND, a novel framework that integrates few-shot expert demonstrations with a tri-teaching strategy for effective noise mitigation. Our method trains three reward models simultaneously, where each model views its small-loss preference pairs as useful knowledge and teaches such useful pairs to its peer network for updating the parameters. Remarkably, our approach requires as few as one to three expert demonstrations to achieve high performance. We evaluate TREND on various robotic manipulation tasks, achieving up to 90% success rates even with noise levels as high as 40%, highlighting its effective robustness in handling noisy preference feedback. Project page: https://shuaiyihuang.github.io/publications/TREND.
P3-PO: Prescriptive Point Priors for Visuo-Spatial Generalization of Robot Policies
Dec 09, 2024
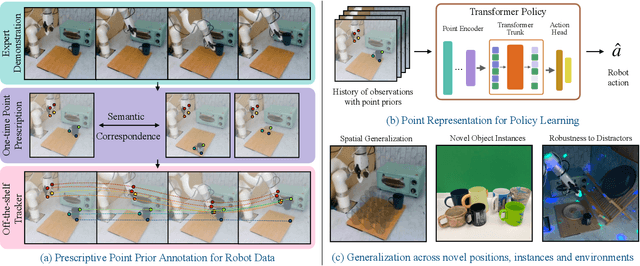


Developing generalizable robot policies that can robustly handle varied environmental conditions and object instances remains a fundamental challenge in robot learning. While considerable efforts have focused on collecting large robot datasets and developing policy architectures to learn from such data, naively learning from visual inputs often results in brittle policies that fail to transfer beyond the training data. This work presents Prescriptive Point Priors for Policies or P3-PO, a novel framework that constructs a unique state representation of the environment leveraging recent advances in computer vision and robot learning to achieve improved out-of-distribution generalization for robot manipulation. This representation is obtained through two steps. First, a human annotator prescribes a set of semantically meaningful points on a single demonstration frame. These points are then propagated through the dataset using off-the-shelf vision models. The derived points serve as an input to state-of-the-art policy architectures for policy learning. Our experiments across four real-world tasks demonstrate an overall 43% absolute improvement over prior methods when evaluated in identical settings as training. Further, P3-PO exhibits 58% and 80% gains across tasks for new object instances and more cluttered environments respectively. Videos illustrating the robot's performance are best viewed at point-priors.github.io.
VeriGraph: Scene Graphs for Execution Verifiable Robot Planning
Nov 15, 2024



Recent advancements in vision-language models (VLMs) offer potential for robot task planning, but challenges remain due to VLMs' tendency to generate incorrect action sequences. To address these limitations, we propose VeriGraph, a novel framework that integrates VLMs for robotic planning while verifying action feasibility. VeriGraph employs scene graphs as an intermediate representation, capturing key objects and spatial relationships to improve plan verification and refinement. The system generates a scene graph from input images and uses it to iteratively check and correct action sequences generated by an LLM-based task planner, ensuring constraints are respected and actions are executable. Our approach significantly enhances task completion rates across diverse manipulation scenarios, outperforming baseline methods by 58% for language-based tasks and 30% for image-based tasks.
NeRF-Aug: Data Augmentation for Robotics with Neural Radiance Fields
Nov 04, 2024
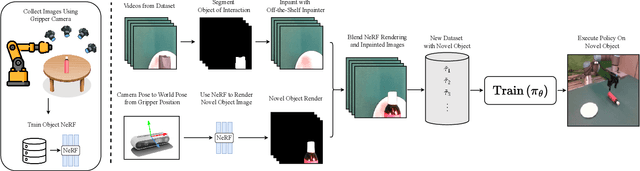


Training a policy that can generalize to unknown objects is a long standing challenge within the field of robotics. The performance of a policy often drops significantly in situations where an object in the scene was not seen during training. To solve this problem, we present NeRF-Aug, a novel method that is capable of teaching a policy to interact with objects that are not present in the dataset. This approach differs from existing approaches by leveraging the speed and photorealism of a neural radiance field for augmentation. NeRF- Aug both creates more photorealistic data and runs 3.83 times faster than existing methods. We demonstrate the effectiveness of our method on 4 tasks with 11 novel objects that have no expert demonstration data. We achieve an average 69.1% success rate increase over existing methods. See video results at https://nerf-aug.github.io.
WayEx: Waypoint Exploration using a Single Demonstration
Jul 22, 2024We propose WayEx, a new method for learning complex goal-conditioned robotics tasks from a single demonstration. Our approach distinguishes itself from existing imitation learning methods by demanding fewer expert examples and eliminating the need for information about the actions taken during the demonstration. This is accomplished by introducing a new reward function and employing a knowledge expansion technique. We demonstrate the effectiveness of WayEx, our waypoint exploration strategy, across six diverse tasks, showcasing its applicability in various environments. Notably, our method significantly reduces training time by 50% as compared to traditional reinforcement learning methods. WayEx obtains a higher reward than existing imitation learning methods given only a single demonstration. Furthermore, we demonstrate its success in tackling complex environments where standard approaches fall short. More information is available at: https://waypoint-ex.github.io.
V-VIPE: Variational View Invariant Pose Embedding
Jul 09, 2024
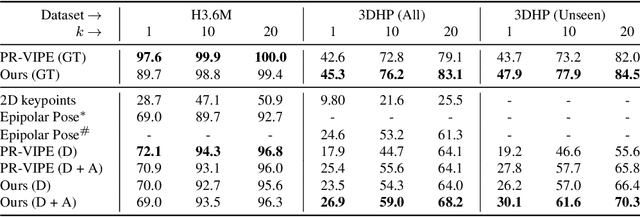


Learning to represent three dimensional (3D) human pose given a two dimensional (2D) image of a person, is a challenging problem. In order to make the problem less ambiguous it has become common practice to estimate 3D pose in the camera coordinate space. However, this makes the task of comparing two 3D poses difficult. In this paper, we address this challenge by separating the problem of estimating 3D pose from 2D images into two steps. We use a variational autoencoder (VAE) to find an embedding that represents 3D poses in canonical coordinate space. We refer to this embedding as variational view-invariant pose embedding V-VIPE. Using V-VIPE we can encode 2D and 3D poses and use the embedding for downstream tasks, like retrieval and classification. We can estimate 3D poses from these embeddings using the decoder as well as generate unseen 3D poses. The variability of our encoding allows it to generalize well to unseen camera views when mapping from 2D space. To the best of our knowledge, V-VIPE is the only representation to offer this diversity of applications. Code and more information can be found at https://v-vipe.github.io/.
ARDuP: Active Region Video Diffusion for Universal Policies
Jun 19, 2024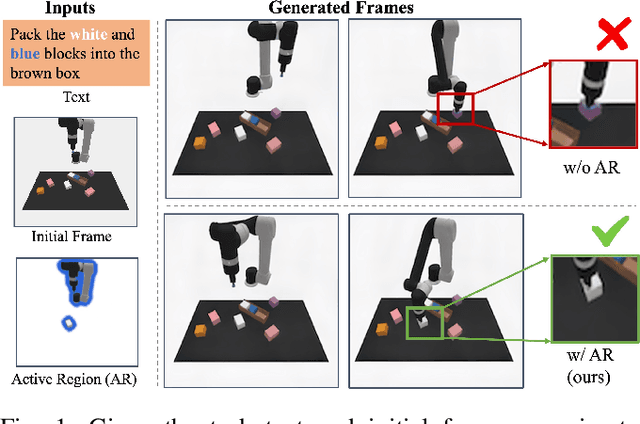
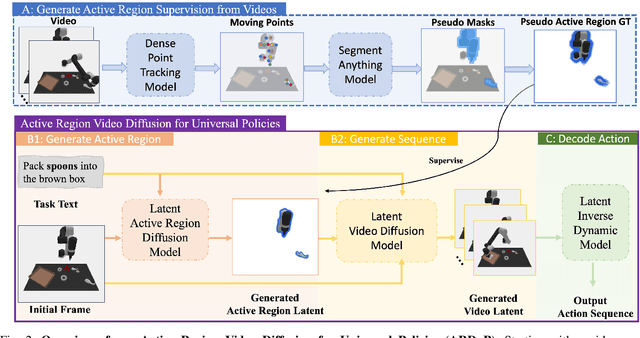
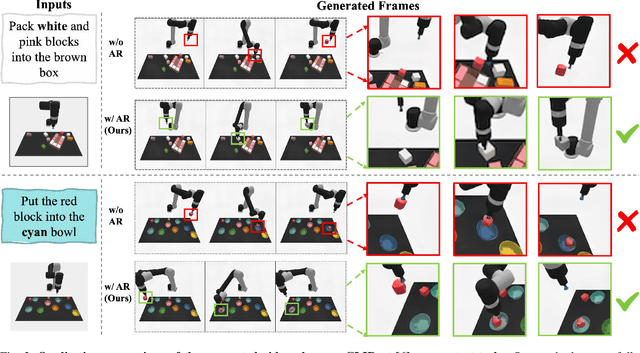
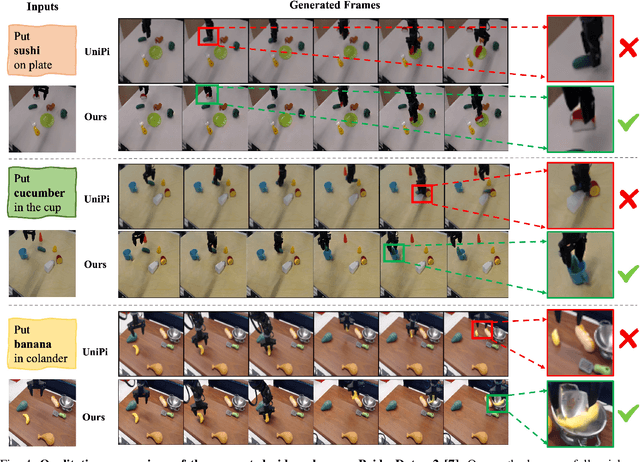
Sequential decision-making can be formulated as a text-conditioned video generation problem, where a video planner, guided by a text-defined goal, generates future frames visualizing planned actions, from which control actions are subsequently derived. In this work, we introduce Active Region Video Diffusion for Universal Policies (ARDuP), a novel framework for video-based policy learning that emphasizes the generation of active regions, i.e. potential interaction areas, enhancing the conditional policy's focus on interactive areas critical for task execution. This innovative framework integrates active region conditioning with latent diffusion models for video planning and employs latent representations for direct action decoding during inverse dynamic modeling. By utilizing motion cues in videos for automatic active region discovery, our method eliminates the need for manual annotations of active regions. We validate ARDuP's efficacy via extensive experiments on simulator CLIPort and the real-world dataset BridgeData v2, achieving notable improvements in success rates and generating convincingly realistic video plans.
No-frills Dynamic Planning using Static Planners
Jun 17, 2021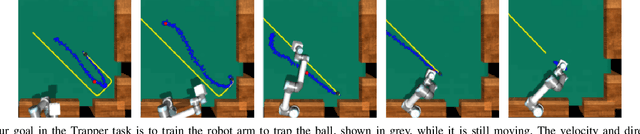

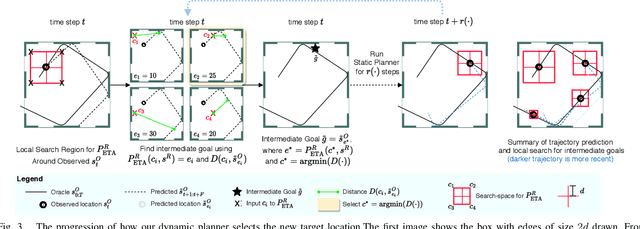

In this paper, we address the task of interacting with dynamic environments where the changes in the environment are independent of the agent. We study this through the context of trapping a moving ball with a UR5 robotic arm. Our key contribution is an approach to utilize a static planner for dynamic tasks using a Dynamic Planning add-on; that is, if we can successfully solve a task with a static target, then our approach can solve the same task when the target is moving. Our approach has three key components: an off-the-shelf static planner, a trajectory forecasting network, and a network to predict robot's estimated time of arrival at any location. We demonstrate the generalization of our approach across environments. More information and videos at https://mlevy2525.github.io/DynamicAddOn.