 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-VIPE: Variational View Invariant Pose Embedding
Paper and Code

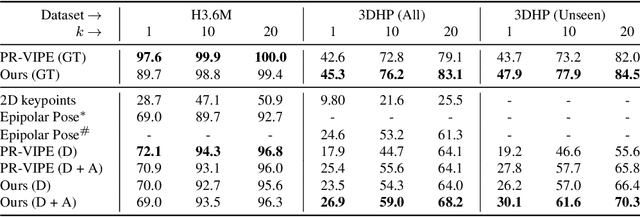


Learning to represent three dimensional (3D) human pose given a two dimensional (2D) image of a person, is a challenging problem. In order to make the problem less ambiguous it has become common practice to estimate 3D pose in the camera coordinate space. However, this makes the task of comparing two 3D poses difficult. In this paper, we address this challenge by separating the problem of estimating 3D pose from 2D images into two steps. We use a variational autoencoder (VAE) to find an embedding that represents 3D poses in canonical coordinate space. We refer to this embedding as variational view-invariant pose embedding V-VIPE. Using V-VIPE we can encode 2D and 3D poses and use the embedding for downstream tasks, like retrieval and classification. We can estimate 3D poses from these embeddings using the decoder as well as generate unseen 3D poses. The variability of our encoding allows it to generalize well to unseen camera views when mapping from 2D space. To the best of our knowledge, V-VIPE is the only representation to offer this diversity of applications. Code and more information can be found at https://v-vipe.github.io/.