 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuka-v2: Tendon Driven Open-Source Dexterous Hand with Wrist and Abduction for Robot Learning
Mar 27, 2026Lack of accessible and dexterous robot hardware has been a significant bottleneck to achieving human-level dexterity in robots. Last year, we released Ruka, a fully open-sourced, tendon-driven humanoid hand with 11 degrees of freedom - 2 per finger and 3 at the thumb - buildable for under $1,300. It was one of the first fully open-sourced humanoid hands, and introduced a novel data-driven approach to finger control that captures tendon dynamics within the control system. Despite these contributions, Ruka lacked two degrees of freedom essential for closely imitating human behavior: wrist mobility and finger adduction/abduction. In this paper, we introduce Ruka-v2: a fully open-sourced, tendon-driven humanoid hand featuring a decoupled 2-DOF parallel wrist and abduction/adduction at the fingers. The parallel wrist adds smooth, independent flexion/extension and radial/ulnar deviation, enabling manipulation in confined environments such as cabinets. Abduction enables motions such as grasping thin objects, in-hand rotation, and calligraphy. We present the design of Ruka-v2 and evaluate it against Ruka through user studies on teleoperated tasks, finding a 51.3% reduction in completion time and a 21.2% increase in success rate. We further demonstrate its full range of applications for robot learning: bimanual and single-arm teleoperation across 13 dexterous tasks, and autonomous policy learning on 3 tasks. All 3D print files, assembly instructions, controller software, and videos are available at https://ruka-hand-v2.github.io/ .
Touch begins where vision ends: Generalizable policies for contact-rich manipulation
Jun 16, 2025Data-driven approaches struggle with precise manipulation; imitation learning requires many hard-to-obtain demonstrations, while reinforcement learning yields brittle, non-generalizable policies. We introduce VisuoTactile Local (ViTaL) policy learning, a framework that solves fine-grained manipulation tasks by decomposing them into two phases: a reaching phase, where a vision-language model (VLM) enables scene-level reasoning to localize the object of interest, and a local interaction phase, where a reusable, scene-agnostic ViTaL policy performs contact-rich manipulation using egocentric vision and tactile sensing. This approach is motivated by the observation that while scene context varies, the low-level interaction remains consistent across task instances. By training local policies once in a canonical setting, they can generalize via a localize-then-execute strategy. ViTaL achieves around 90% success on contact-rich tasks in unseen environments and is robust to distractors. ViTaL's effectiveness stems from three key insights: (1) foundation models for segmentation enable training robust visual encoders via behavior cloning; (2) these encoders improve the generalizability of policies learned using residual RL; and (3) tactile sensing significantly boosts performance in contact-rich tasks. Ablation studies validate each of these insights, and we demonstrate that ViTaL integrates well with high-level VLMs, enabling robust, reusable low-level skills. Results and videos are available at https://vitalprecise.github.io.
eFlesh: Highly customizable Magnetic Touch Sensing using Cut-Cell Microstructures
Jun 11, 2025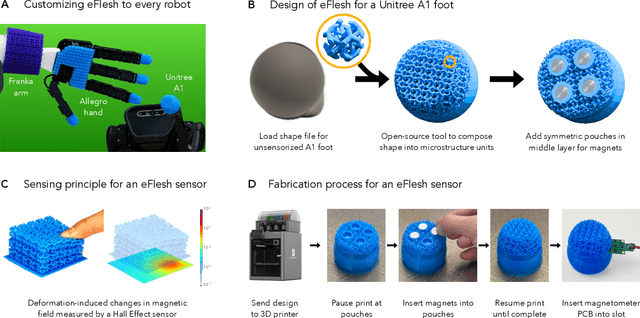


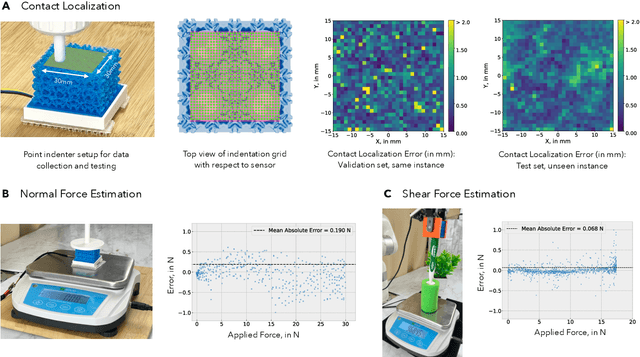
If human experience is any guide, operating effectively in unstructured environments -- like homes and offices -- requires robots to sense the forces during physical interaction. Yet, the lack of a versatile, accessible, and easily customizable tactile sensor has led to fragmented, sensor-specific solutions in robotic manipulation -- and in many cases, to force-unaware, sensorless approaches. With eFlesh, we bridge this gap by introducing a magnetic tactile sensor that is low-cost, easy to fabricate, and highly customizable. Building an eFlesh sensor requires only four components: a hobbyist 3D printer, off-the-shelf magnets (<$5), a CAD model of the desired shape, and a magnetometer circuit board. The sensor is constructed from tiled, parameterized microstructures, which allow for tuning the sensor's geometry and its mechanical response. We provide an open-source design tool that converts convex OBJ/STL files into 3D-printable STLs for fabrication. This modular design framework enables users to create application-specific sensors, and to adjust sensitivity depending on the task. Our sensor characterization experiments demonstrate the capabilities of eFlesh: contact localization RMSE of 0.5 mm, and force prediction RMSE of 0.27 N for normal force and 0.12 N for shear force. We also present a learned slip detection model that generalizes to unseen objects with 95% accuracy, and visuotactile control policies that improve manipulation performance by 40% over vision-only baselines -- achieving 91% average success rate for four precise tasks that require sub-mm accuracy for successful completion. All design files, code and the CAD-to-eFlesh STL conversion tool are open-sourced and available on https://e-flesh.com.
EgoZero: Robot Learning from Smart Glasses
May 26, 2025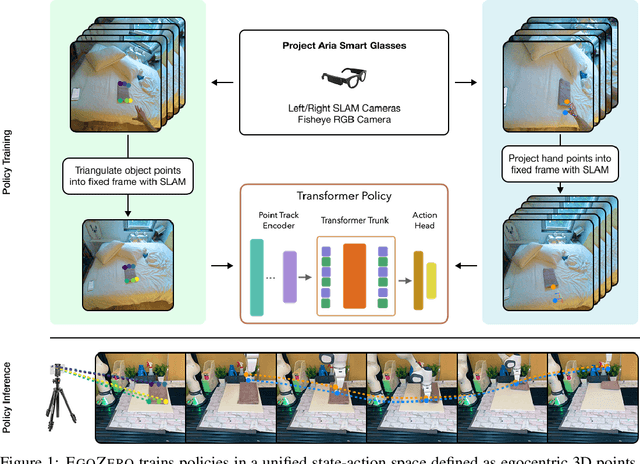
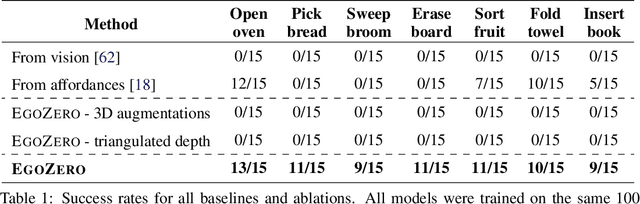

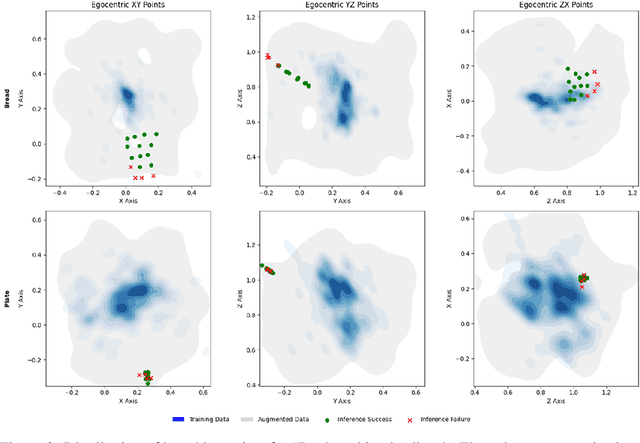
Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans interact constantly with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, $\textbf{and zero robot data}$. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning - paving the way toward a future of abundant, diverse, and naturalistic training data for robots. Code and videos are available at https://egozero-robot.github.io.
Bridging the Human to Robot Dexterity Gap through Object-Oriented Rewards
Oct 30, 2024



Training robots directly from human videos is an emerging area in robotics and computer vision. While there has been notable progress with two-fingered grippers, learning autonomous tasks for multi-fingered robot hands in this way remains challenging. A key reason for this difficulty is that a policy trained on human hands may not directly transfer to a robot hand due to morphology differences. In this work, we present HuDOR, a technique that enables online fine-tuning of policies by directly computing rewards from human videos. Importantly, this reward function is built using object-oriented trajectories derived from off-the-shelf point trackers, providing meaningful learning signals despite the morphology gap and visual differences between human and robot hands. Given a single video of a human solving a task, such as gently opening a music box, HuDOR enables our four-fingered Allegro hand to learn the task with just an hour of online interaction. Our experiments across four tasks show that HuDOR achieves a 4x improvement over baselines. Code and videos are available on our website, https://object-rewards.github.io.
Learning Precise, Contact-Rich Manipulation through Uncalibrated Tactile Skins
Oct 22, 2024



While visuomotor policy learning has advanced robotic manipulation, precisely executing contact-rich tasks remains challenging due to the limitations of vision in reasoning about physical interactions. To address this, recent work has sought to integrate tactile sensing into policy learning. However, many existing approaches rely on optical tactile sensors that are either restricted to recognition tasks or require complex dimensionality reduction steps for policy learning. In this work, we explore learning policies with magnetic skin sensors, which are inherently low-dimensional, highly sensitive, and inexpensive to integrate with robotic platforms. To leverage these sensors effectively, we present the Visuo-Skin (ViSk) framework, a simple approach that uses a transformer-based policy and treats skin sensor data as additional tokens alongside visual information. Evaluated on four complex real-world tasks involving credit card swiping, plug insertion, USB insertion, and bookshelf retrieval, ViSk significantly outperforms both vision-only and optical tactile sensing based policies. Further analysis reveals that combining tactile and visual modalities enhances policy performance and spatial generalization, achieving an average improvement of 27.5% across tasks. https://visuoskin.github.io/
AnySkin: Plug-and-play Skin Sensing for Robotic Touch
Sep 12, 2024While tactile sensing is widely accepted as an important and useful sensing modality, its use pales in comparison to other sensory modalities like vision and proprioception. AnySkin addresses the critical challenges that impede the use of tactile sensing -- versatility, replaceability, and data reusability. Building on the simplistic design of ReSkin, and decoupling the sensing electronics from the sensing interface, AnySkin simplifies integration making it as straightforward as putting on a phone case and connecting a charger. Furthermore, AnySkin is the first uncalibrated tactile-sensor with cross-instance generalizability of learned manipulation policies. To summarize, this work makes three key contributions: first, we introduce a streamlined fabrication process and a design tool for creating an adhesive-free, durable and easily replaceable magnetic tactile sensor; second, we characterize slip detection and policy learning with the AnySkin sensor; and third, we demonstrate zero-shot generalization of models trained on one instance of AnySkin to new instances, and compare it with popular existing tactile solutions like DIGIT and ReSkin.https://any-skin.github.io/
Hierarchical State Space Models for Continuous Sequence-to-Sequence Modeling
Feb 15, 2024Reasoning from sequences of raw sensory data is a ubiquitous problem across fields ranging from medical devices to robotics. These problems often involve using long sequences of raw sensor data (e.g. magnetometers, piezoresistors) to predict sequences of desirable physical quantities (e.g. force, inertial measurements). While classical approaches are powerful for locally-linear prediction problems, they often fall short when using real-world sensors. These sensors are typically non-linear, are affected by extraneous variables (e.g. vibration), and exhibit data-dependent drift. For many problems, the prediction task is exacerbated by small labeled datasets since obtaining ground-truth labels requires expensive equipment. In this work, we present Hierarchical State-Space Models (HiSS), a conceptually simple, new technique for continuous sequential prediction. HiSS stacks structured state-space models on top of each other to create a temporal hierarchy. Across six real-world sensor datasets, from tactile-based state prediction to accelerometer-based inertial measurement, HiSS outperforms state-of-the-art sequence models such as causal Transformers, LSTMs, S4, and Mamba by at least 23% on MSE. Our experiments further indicate that HiSS demonstrates efficient scaling to smaller datasets and is compatible with existing data-filtering techniques. Code, datasets and videos can be found on https://hiss-csp.github.io.
All the Feels: A dexterous hand with large area sensing
Oct 27, 2022



High cost and lack of reliability has precluded the widespread adoption of dexterous hands in robotics. Furthermore, the lack of a viable tactile sensor capable of sensing over the entire area of the hand impedes the rich, low-level feedback that would improve learning of dexterous manipulation skills. This paper introduces an inexpensive, modular, robust, and scalable platform - the DManus- aimed at resolving these challenges while satisfying the large-scale data collection capabilities demanded by deep robot learning paradigms. Studies on human manipulation point to the criticality of low-level tactile feedback in performing everyday dexterous tasks. The DManus comes with ReSkin sensing on the entire surface of the palm as well as the fingertips. We demonstrate effectiveness of the fully integrated system in a tactile aware task - bin picking and sorting. Code, documentation, design files, detailed assembly instructions, trained models, task videos, and all supplementary materials required to recreate the setup can be found on http://roboticsbenchmarks.org/platforms/dmanus
ReSkin: versatile, replaceable, lasting tactile skins
Oct 29, 2021


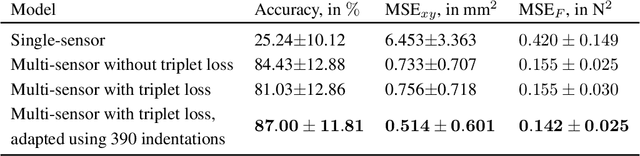
Soft sensors have continued growing interest in robotics, due to their ability to enable both passive conformal contact from the material properties and active contact data from the sensor properties. However, the same properties of conformal contact result in faster deterioration of soft sensors and larger variations in their response characteristics over time and across samples, inhibiting their ability to be long-lasting and replaceable. ReSkin is a tactile soft sensor that leverages machine learning and magnetic sensing to offer a low-cost, diverse and compact solution for long-term use. Magnetic sensing separates the electronic circuitry from the passive interface, making it easier to replace interfaces as they wear out while allowing for a wide variety of form factors. Machine learning allows us to learn sensor response models that are robust to variations across fabrication and time, and our self-supervised learning algorithm enables finer performance enhancement with small, inexpensive data collection procedures. We believe that ReSkin opens the door to more versatile, scalable and inexpensive tactile sensation modules than existing alternatives.