 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Cascaded Diffusion Models for Neural Motion Planning
May 21, 2025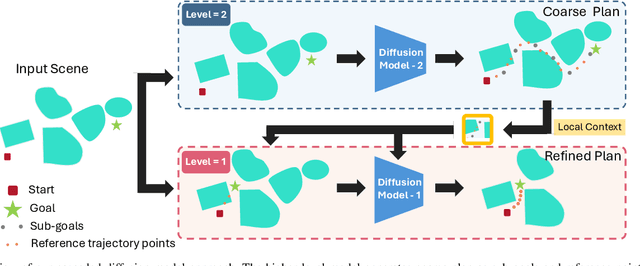

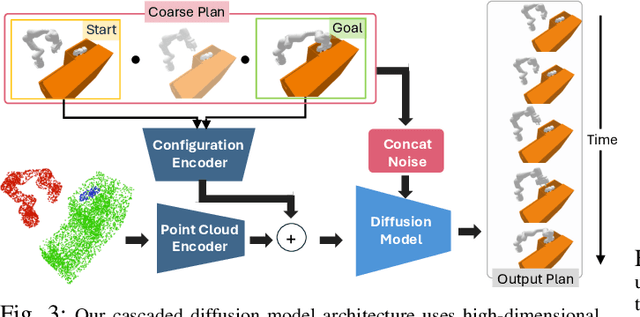
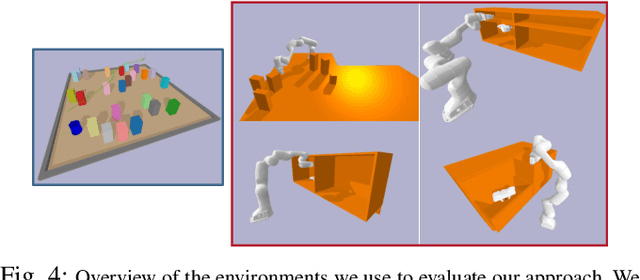
Robots in the real world need to perceive and move to goals in complex environments without collisions. Avoiding collisions is especially difficult when relying on sensor perception and when goals are among clutter. Diffusion policies and other generative models have shown strong performance in solving local planning problems, but often struggle at avoiding all of the subtle constraint violations that characterize truly challenging global motion planning problems. In this work, we propose an approach for learning global motion planning using diffusion policies, allowing the robot to generate full trajectories through complex scenes and reasoning about multiple obstacles along the path. Our approach uses cascaded hierarchical models which unify global prediction and local refinement together with online plan repair to ensure the trajectories are collision free. Our method outperforms (by ~5%) a wide variety of baselines on challenging tasks in multiple domains including navigation and manipulation.
Semantically Controllable Augmentations for Generalizable Robot Learning
Sep 02, 2024



Generalization to unseen real-world scenarios for robot manipulation requires exposure to diverse datasets during training. However, collecting large real-world datasets is intractable due to high operational costs. For robot learning to generalize despite these challenges, it is essential to leverage sources of data or priors beyond the robot's direct experience. In this work, we posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. These generative models encompass a broad range of real-world scenarios beyond a robot's direct experience and can synthesize novel synthetic experiences that expose robotic agents to additional world priors aiding real-world generalization at no extra cost. In particular, our approach leverages pre-trained generative models as an effective tool for data augmentation. We propose a generative augmentation framework for semantically controllable augmentations and rapidly multiplying robot datasets while inducing rich variations that enable real-world generalization. Based on diverse augmentations of robot data, we show how scalable robot manipulation policies can be trained and deployed both in simulation and in unseen real-world environments such as kitchens and table-tops. By demonstrating the effectiveness of image-text generative models in diverse real-world robotic applications, our generative augmentation framework provides a scalable and efficient path for boosting generalization in robot learning at no extra human cost.
Improving Domain Adaptation Through Class Aware Frequency Transformation
Jul 28, 2024In this work, we explore the usage of the Frequency Transformation for reducing the domain shift between the source and target domain (e.g., synthetic image and real image respectively) towards solving the Domain Adaptation task. Most of the Unsupervised Domain Adaptation (UDA) algorithms focus on reducing the global domain shift between labelled source and unlabelled target domains by matching the marginal distributions under a small domain gap assumption. UDA performance degrades for the cases where the domain gap between source and target distribution is large. In order to bring the source and the target domains closer, we propose a novel approach based on traditional image processing technique Class Aware Frequency Transformation (CAFT) that utilizes pseudo label based class consistent low-frequency swapping for improving the overall performance of the existing UDA algorithms. The proposed approach, when compared with the state-of-the-art deep learning based methods, is computationally more efficient and can easily be plugged into any existing UDA algorithm to improve its performance. Additionally, we introduce a novel approach based on absolute difference of top-2 class prediction probabilities (ADT2P) for filtering target pseudo labels into clean and noisy sets. Samples with clean pseudo labels can be used to improve the performance of unsupervised learning algorithms. We name the overall framework as CAFT++. We evaluate the same on the top of different UDA algorithms across many public domain adaptation datasets. Our extensive experiments indicate that CAFT++ is able to achieve significant performance gains across all the popular benchmarks.
Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Dec 01, 2023We pursue the goal of developing robots that can interact zero-shot with generic unseen objects via a diverse repertoire of manipulation skills and show how passive human videos can serve as a rich source of data for learning such generalist robots. Unlike typical robot learning approaches which directly learn how a robot should act from interaction data, we adopt a factorized approach that can leverage large-scale human videos to learn how a human would accomplish a desired task (a human plan), followed by translating this plan to the robots embodiment. Specifically, we learn a human plan predictor that, given a current image of a scene and a goal image, predicts the future hand and object configurations. We combine this with a translation module that learns a plan-conditioned robot manipulation policy, and allows following humans plans for generic manipulation tasks in a zero-shot manner with no deployment-time training. Importantly, while the plan predictor can leverage large-scale human videos for learning, the translation module only requires a small amount of in-domain data, and can generalize to tasks not seen during training. We show that our learned system can perform over 16 manipulation skills that generalize to 40 objects, encompassing 100 real-world tasks for table-top manipulation and diverse in-the-wild manipulation. https://homangab.github.io/hopman/
RoboHive: A Unified Framework for Robot Learning
Oct 10, 2023



We present RoboHive, a comprehensive software platform and ecosystem for research in the field of Robot Learning and Embodied Artificial Intelligence. Our platform encompasses a diverse range of pre-existing and novel environments, including dexterous manipulation with the Shadow Hand, whole-arm manipulation tasks with Franka and Fetch robots, quadruped locomotion, among others. Included environments are organized within and cover multiple domains such as hand manipulation, locomotion, multi-task, multi-agent, muscles, etc. In comparison to prior works, RoboHive offers a streamlined and unified task interface taking dependency on only a minimal set of well-maintained packages, features tasks with high physics fidelity and rich visual diversity, and supports common hardware drivers for real-world deployment. The unified interface of RoboHive offers a convenient and accessible abstraction for algorithmic research in imitation, reinforcement, multi-task, and hierarchical learning. Furthermore, RoboHive includes expert demonstrations and baseline results for most environments, providing a standard for benchmarking and comparisons. Details: https://sites.google.com/view/robohive
MoDem-V2: Visuo-Motor World Models for Real-World Robot Manipulation
Sep 25, 2023Robotic systems that aspire to operate in uninstrumented real-world environments must perceive the world directly via onboard sensing. Vision-based learning systems aim to eliminate the need for environment instrumentation by building an implicit understanding of the world based on raw pixels, but navigating the contact-rich high-dimensional search space from solely sparse visual reward signals significantly exacerbates the challenge of exploration. The applicability of such systems is thus typically restricted to simulated or heavily engineered environments since agent exploration in the real-world without the guidance of explicit state estimation and dense rewards can lead to unsafe behavior and safety faults that are catastrophic. In this study, we isolate the root causes behind these limitations to develop a system, called MoDem-V2, capable of learning contact-rich manipulation directly in the uninstrumented real world. Building on the latest algorithmic advancements in model-based reinforcement learning (MBRL), demo-bootstrapping, and effective exploration, MoDem-V2 can acquire contact-rich dexterous manipulation skills directly in the real world. We identify key ingredients for leveraging demonstrations in model learning while respecting real-world safety considerations -- exploration centering, agency handover, and actor-critic ensembles. We empirically demonstrate the contribution of these ingredients in four complex visuo-motor manipulation problems in both simulation and the real world. To the best of our knowledge, our work presents the first successful system for demonstration-augmented visual MBRL trained directly in the real world. Visit https://sites.google.com/view/modem-v2 for videos and more details.
Natural and Robust Walking using Reinforcement Learning without Demonstrations in High-Dimensional Musculoskeletal Models
Sep 07, 2023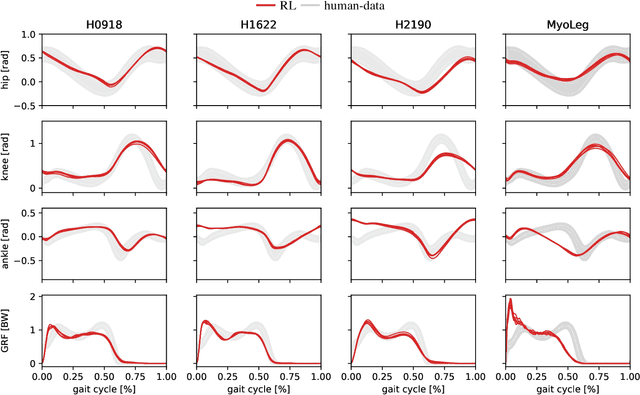
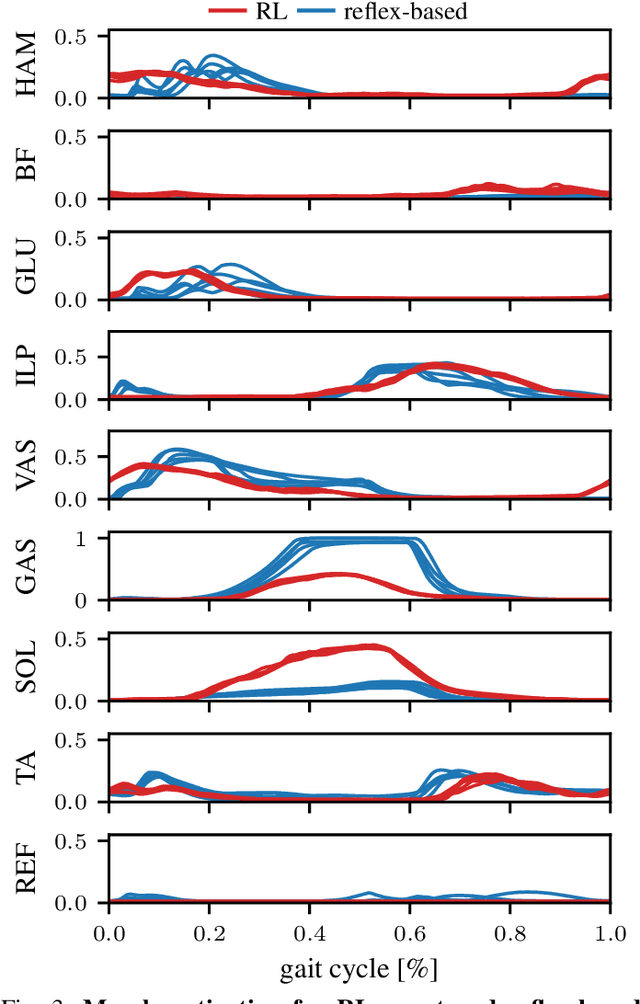
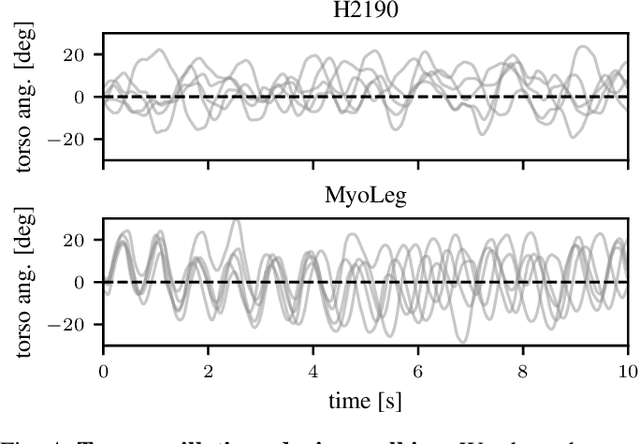

Humans excel at robust bipedal walking in complex natural environments. In each step, they adequately tune the interaction of biomechanical muscle dynamics and neuronal signals to be robust against uncertainties in ground conditions. However, it is still not fully understood how the nervous system resolves the musculoskeletal redundancy to solve the multi-objective control problem considering stability, robustness, and energy efficiency. In computer simulations, energy minimization has been shown to be a successful optimization target, reproducing natural walking with trajectory optimization or reflex-based control methods. However, these methods focus on particular motions at a time and the resulting controllers are limited when compensating for perturbations. In robotics, reinforcement learning~(RL) methods recently achieved highly stable (and efficient) locomotion on quadruped systems, but the generation of human-like walking with bipedal biomechanical models has required extensive use of expert data sets. This strong reliance on demonstrations often results in brittle policies and limits the application to new behaviors, especially considering the potential variety of movements for high-dimensional musculoskeletal models in 3D. Achieving natural locomotion with RL without sacrificing its incredible robustness might pave the way for a novel approach to studying human walking in complex natural environments. Videos: https://sites.google.com/view/naturalwalkingrl
MyoDex: A Generalizable Prior for Dexterous Manipulation
Sep 06, 2023



Human dexterity is a hallmark of motor control. Our hands can rapidly synthesize new behaviors despite the complexity (multi-articular and multi-joints, with 23 joints controlled by more than 40 muscles) of musculoskeletal sensory-motor circuits. In this work, we take inspiration from how human dexterity builds on a diversity of prior experiences, instead of being acquired through a single task. Motivated by this observation, we set out to develop agents that can build upon their previous experience to quickly acquire new (previously unattainable) behaviors. Specifically, our approach leverages multi-task learning to implicitly capture task-agnostic behavioral priors (MyoDex) for human-like dexterity, using a physiologically realistic human hand model - MyoHand. We demonstrate MyoDex's effectiveness in few-shot generalization as well as positive transfer to a large repertoire of unseen dexterous manipulation tasks. Agents leveraging MyoDex can solve approximately 3x more tasks, and 4x faster in comparison to a distillation baseline. While prior work has synthesized single musculoskeletal control behaviors, MyoDex is the first generalizable manipulation prior that catalyzes the learning of dexterous physiological control across a large variety of contact-rich behaviors. We also demonstrate the effectiveness of our paradigms beyond musculoskeletal control towards the acquisition of dexterity in 24 DoF Adroit Hand. Website: https://sites.google.com/view/myodex
REBOOT: Reuse Data for Bootstrapping Efficient Real-World Dexterous Manipulation
Sep 06, 2023Dexterous manipulation tasks involving contact-rich interactions pose a significant challenge for both model-based control systems and imitation learning algorithms. The complexity arises from the need for multi-fingered robotic hands to dynamically establish and break contacts, balance non-prehensile forces, and control large degrees of freedom. Reinforcement learning (RL) offers a promising approach due to its general applicability and capacity to autonomously acquire optimal manipulation strategies. However, its real-world application is often hindered by the necessity to generate a large number of samples, reset the environment, and obtain reward signals. In this work, we introduce an efficient system for learning dexterous manipulation skills with RL to alleviate these challenges. The main idea of our approach is the integration of recent advances in sample-efficient RL and replay buffer bootstrapping. This combination allows us to utilize data from different tasks or objects as a starting point for training new tasks, significantly improving learning efficiency. Additionally, our system completes the real-world training cycle by incorporating learned resets via an imitation-based pickup policy as well as learned reward functions, eliminating the need for manual resets and reward engineering. We demonstrate the benefits of reusing past data as replay buffer initialization for new tasks, for instance, the fast acquisition of intricate manipulation skills in the real world on a four-fingered robotic hand. (Videos: https://sites.google.com/view/reboot-dexterous)