 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Question Answering through query-based frame selection
Jan 12, 2026Video Question Answering (VideoQA) models enhance understanding and interaction with audiovisual content, making it more accessible, searchable, and useful for a wide range of fields such as education, surveillance, entertainment, and content creation. Due to heavy compute requirements, most large visual language models (VLMs) for VideoQA rely on a fixed number of frames by uniformly sampling the video. However, this process does not pick important frames or capture the context of the video. We present a novel query-based selection of frames relevant to the questions based on the submodular mutual Information (SMI) functions. By replacing uniform frame sampling with query-based selection, our method ensures that the chosen frames provide complementary and essential visual information for accurate VideoQA. We evaluate our approach on the MVBench dataset, which spans a diverse set of multi-action video tasks. VideoQA accuracy on this dataset was assessed using two VLMs, namely Video-LLaVA and LLaVA-NeXT, both of which originally employed uniform frame sampling. Experiments were conducted using both uniform and query-based sampling strategies. An accuracy improvement of up to \textbf{4\%} was observed when using query-based frame selection over uniform sampling. Qualitative analysis further highlights that query-based selection, using SMI functions, consistently picks frames better aligned with the question. We opine that such query-based frame selection can enhance accuracy in a wide range of tasks that rely on only a subset of video frames.
Improving Domain Adaptation Through Class Aware Frequency Transformation
Jul 28, 2024In this work, we explore the usage of the Frequency Transformation for reducing the domain shift between the source and target domain (e.g., synthetic image and real image respectively) towards solving the Domain Adaptation task. Most of the Unsupervised Domain Adaptation (UDA) algorithms focus on reducing the global domain shift between labelled source and unlabelled target domains by matching the marginal distributions under a small domain gap assumption. UDA performance degrades for the cases where the domain gap between source and target distribution is large. In order to bring the source and the target domains closer, we propose a novel approach based on traditional image processing technique Class Aware Frequency Transformation (CAFT) that utilizes pseudo label based class consistent low-frequency swapping for improving the overall performance of the existing UDA algorithms. The proposed approach, when compared with the state-of-the-art deep learning based methods, is computationally more efficient and can easily be plugged into any existing UDA algorithm to improve its performance. Additionally, we introduce a novel approach based on absolute difference of top-2 class prediction probabilities (ADT2P) for filtering target pseudo labels into clean and noisy sets. Samples with clean pseudo labels can be used to improve the performance of unsupervised learning algorithms. We name the overall framework as CAFT++. We evaluate the same on the top of different UDA algorithms across many public domain adaptation datasets. Our extensive experiments indicate that CAFT++ is able to achieve significant performance gains across all the popular benchmarks.
CoNMix for Source-free Single and Multi-target Domain Adaptation
Nov 07, 2022This work introduces the novel task of Source-free Multi-target Domain Adaptation and proposes adaptation framework comprising of \textbf{Co}nsistency with \textbf{N}uclear-Norm Maximization and \textbf{Mix}Up knowledge distillation (\textit{CoNMix}) as a solution to this problem. The main motive of this work is to solve for Single and Multi target Domain Adaptation (SMTDA) for the source-free paradigm, which enforces a constraint where the labeled source data is not available during target adaptation due to various privacy-related restrictions on data sharing. The source-free approach leverages target pseudo labels, which can be noisy, to improve the target adaptation. We introduce consistency between label preserving augmentations and utilize pseudo label refinement methods to reduce noisy pseudo labels. Further, we propose novel MixUp Knowledge Distillation (MKD) for better generalization on multiple target domains using various source-free STDA models. We also show that the Vision Transformer (VT) backbone gives better feature representation with improved domain transferability and class discriminability. Our proposed framework achieves the state-of-the-art (SOTA) results in various paradigms of source-free STDA and MTDA settings on popular domain adaptation datasets like Office-Home, Office-Caltech, and DomainNet. Project Page: https://sites.google.com/view/conmix-vcl
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022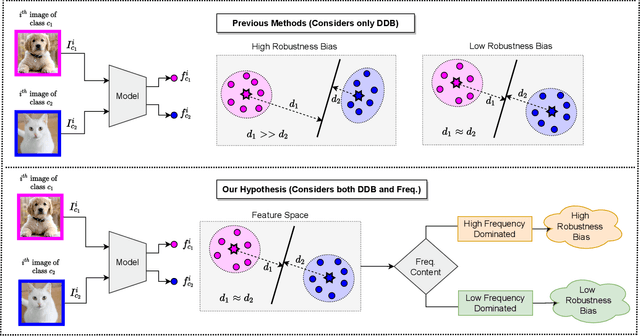
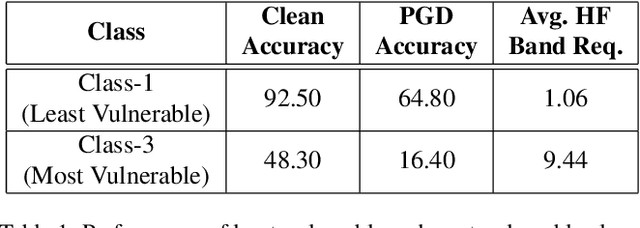
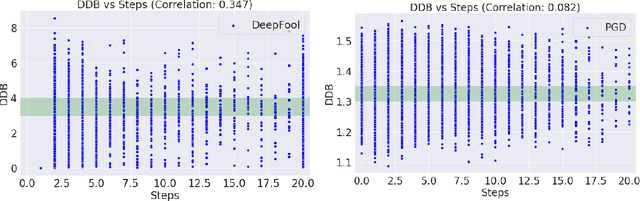

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.