 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ_0$-WM: A Unified Video-Action World Model for Robotic Manipulation
May 31, 2026Robotic manipulation requires models that generate executable actions while anticipating and evaluating their future consequences before physical execution. We present $τ_0$-World Model ($τ_0$-WM), a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework. Built on a shared video diffusion backbone, $τ_0$-WM provides two complementary interfaces. First, a video action model jointly predicts future visual latents and continuous action chunks from multi-view observations, language instructions, and robot state. Second, an action-conditioned video simulator rolls out candidate action chunks into multi-view futures and predicts dense task-progress scores. The model is trained on approximately $27{,}300$ hours of real-robot teleoperation, UMI-style interaction, egocentric human videos, and rollout or failure trajectories using modality-specific supervision masks. At inference time, $τ_0$-WM uses test-time computation to sample action candidates, rank them with re-denoising consistency, and invoke simulator-based rectification for low-quality candidates. On challenging long-horizon and fine-grained robotic manipulation tasks, $τ_0$-WM shows superior performance over other relevant baselines.
SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
Act2Goal: From World Model To General Goal-conditioned Policy
Dec 29, 2025Specifying robotic manipulation tasks in a manner that is both expressive and precise remains a central challenge. While visual goals provide a compact and unambiguous task specification, existing goal-conditioned policies often struggle with long-horizon manipulation due to their reliance on single-step action prediction without explicit modeling of task progress. We propose Act2Goal, a general goal-conditioned manipulation policy that integrates a goal-conditioned visual world model with multi-scale temporal control. Given a current observation and a target visual goal, the world model generates a plausible sequence of intermediate visual states that captures long-horizon structure. To translate this visual plan into robust execution, we introduce Multi-Scale Temporal Hashing (MSTH), which decomposes the imagined trajectory into dense proximal frames for fine-grained closed-loop control and sparse distal frames that anchor global task consistency. The policy couples these representations with motor control through end-to-end cross-attention, enabling coherent long-horizon behavior while remaining reactive to local disturbances. Act2Goal achieves strong zero-shot generalization to novel objects, spatial layouts, and environments. We further enable reward-free online adaptation through hindsight goal relabeling with LoRA-based finetuning, allowing rapid autonomous improvement without external supervision. Real-robot experiments demonstrate that Act2Goal improves success rates from 30% to 90% on challenging out-of-distribution tasks within minutes of autonomous interaction, validating that goal-conditioned world models with multi-scale temporal control provide structured guidance necessary for robust long-horizon manipulation. Project page: https://act2goal.github.io/
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025
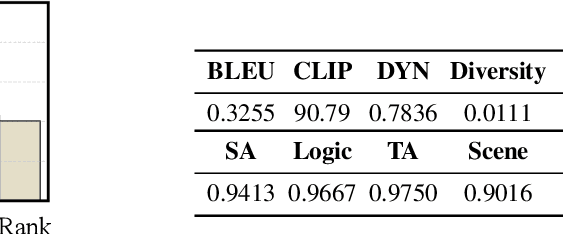

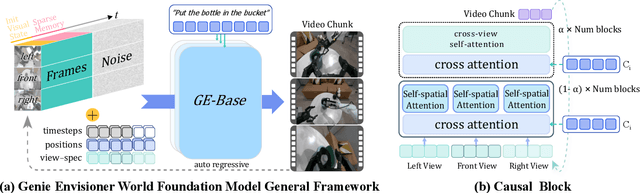
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation
Feb 23, 2025



Solving complex long-horizon robotic manipulation problems requires sophisticated high-level planning capabilities, the ability to reason about the physical world, and reactively choose appropriate motor skills. Vision-language models (VLMs) pretrained on Internet data could in principle offer a framework for tackling such problems. However, in their current form, VLMs lack both the nuanced understanding of intricate physics required for robotic manipulation and the ability to reason over long horizons to address error compounding issues. In this paper, we introduce a novel test-time computation framework that enhances VLMs' physical reasoning capabilities for multi-stage manipulation tasks. At its core, our approach iteratively improves a pretrained VLM with a "reflection" mechanism - it uses a generative model to imagine future world states, leverages these predictions to guide action selection, and critically reflects on potential suboptimalities to refine its reasoning. Experimental results demonstrate that our method significantly outperforms several state-of-the-art commercial VLMs as well as other post-training approaches such as Monte Carlo Tree Search (MCTS). Videos are available at https://reflect-vlm.github.io.
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
Dec 13, 2024Recent advances in robotic foundation models have enabled the development of generalist policies that can adapt to diverse tasks. While these models show impressive flexibility, their performance heavily depends on the quality of their training data. In this work, we propose Reinforcement Learning Distilled Generalists (RLDG), a method that leverages reinforcement learning to generate high-quality training data for finetuning generalist policies. Through extensive real-world experiments on precise manipulation tasks like connector insertion and assembly, we demonstrate that generalist policies trained with RL-generated data consistently outperform those trained with human demonstrations, achieving up to 40% higher success rates while generalizing better to new tasks. We also provide a detailed analysis that reveals this performance gain stems from both optimized action distributions and improved state coverage. Our results suggest that combining task-specific RL with generalist policy distillation offers a promising approach for developing more capable and efficient robotic manipulation systems that maintain the flexibility of foundation models while achieving the performance of specialized controllers. Videos and code can be found on our project website https://generalist-distillation.github.io
Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning
Oct 29, 2024Reinforcement learning (RL) holds great promise for enabling autonomous acquisition of complex robotic manipulation skills, but realizing this potential in real-world settings has been challenging. We present a human-in-the-loop vision-based RL system that demonstrates impressive performance on a diverse set of dexterous manipulation tasks, including dynamic manipulation, precision assembly, and dual-arm coordination. Our approach integrates demonstrations and human corrections, efficient RL algorithms, and other system-level design choices to learn policies that achieve near-perfect success rates and fast cycle times within just 1 to 2.5 hours of training. We show that our method significantly outperforms imitation learning baselines and prior RL approaches, with an average 2x improvement in success rate and 1.8x faster execution. Through extensive experiments and analysis, we provide insights into the effectiveness of our approach, demonstrating how it learns robust, adaptive policies for both reactive and predictive control strategies. Our results suggest that RL can indeed learn a wide range of complex vision-based manipulation policies directly in the real world within practical training times. We hope this work will inspire a new generation of learned robotic manipulation techniques, benefiting both industrial applications and research advancements. Videos and code are available at our project website https://hil-serl.github.io/.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.